运行Shell脚本有两种方法:
1、vi test.sh
#! /bin/bash
#编写内容
运行sh test.sh
2、chmod +x ./test.sh #脚本具有执行权限
./test.sh #执行脚本

if条件判断
单分支if条件:
if [ 条件判断式 ]then程序
fi
注意:中括号与条件判断式之间有空格
双分支if条件:
if [ 条件判断式 ]then条件成立时,执行的程序else条件不成立时,执行的另一个程序
fi
多分支if条件:
if [ 条件判断式1 ]then当条件判断式1成立时,执行程序1
elif [ 条件判断式2 ]then当条件判断式2成立时,执行程序2
…更多条件elif…
else当所有条件都不成立时,最后执行此程序
fi
多分支case条件语句
case语句和if…elif…else语句一样都是多分支条件语句,不过和if多分支条件语句不同的是,case语句只能判断一种条件关系,而if语句可以判断多种条件关系。
case $变量名 in“值1”)如果变量的值等于值1,则执行程序1;;“值2”)如果变量的值等于值2,则执行程序2;;…省其他分支…*)如果变量的值都不是以上的值,则执行此程序;;
esac
for循环
这种语法中for循环的次数,取决于in后面值的个数(空格分隔),有几个值就循环几次,并且每次循环都把值赋予变量。
也就是说,假设in后面有三个值,for会循环三次,第一次循环会把值1赋予变量,第二次循环会把值2赋予变量,以此类推。
for 变量 in 值1 值2 值3 …(可以是一个文件等)do程序done
第二种:
比如初始值i=1;循环控制条件i<=100;变量条件i++
for((初始值;循环控制条件;变量条件))do程序done
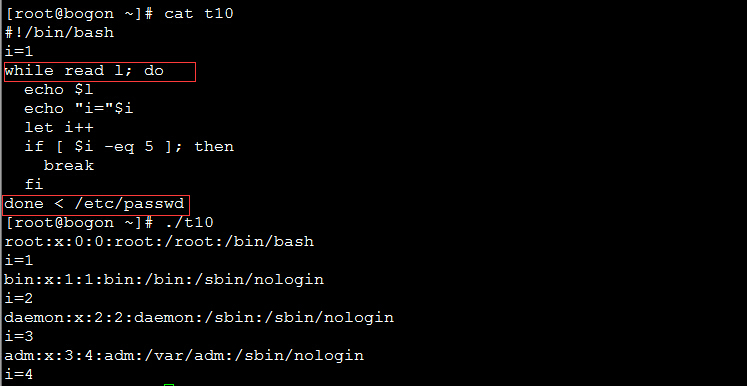
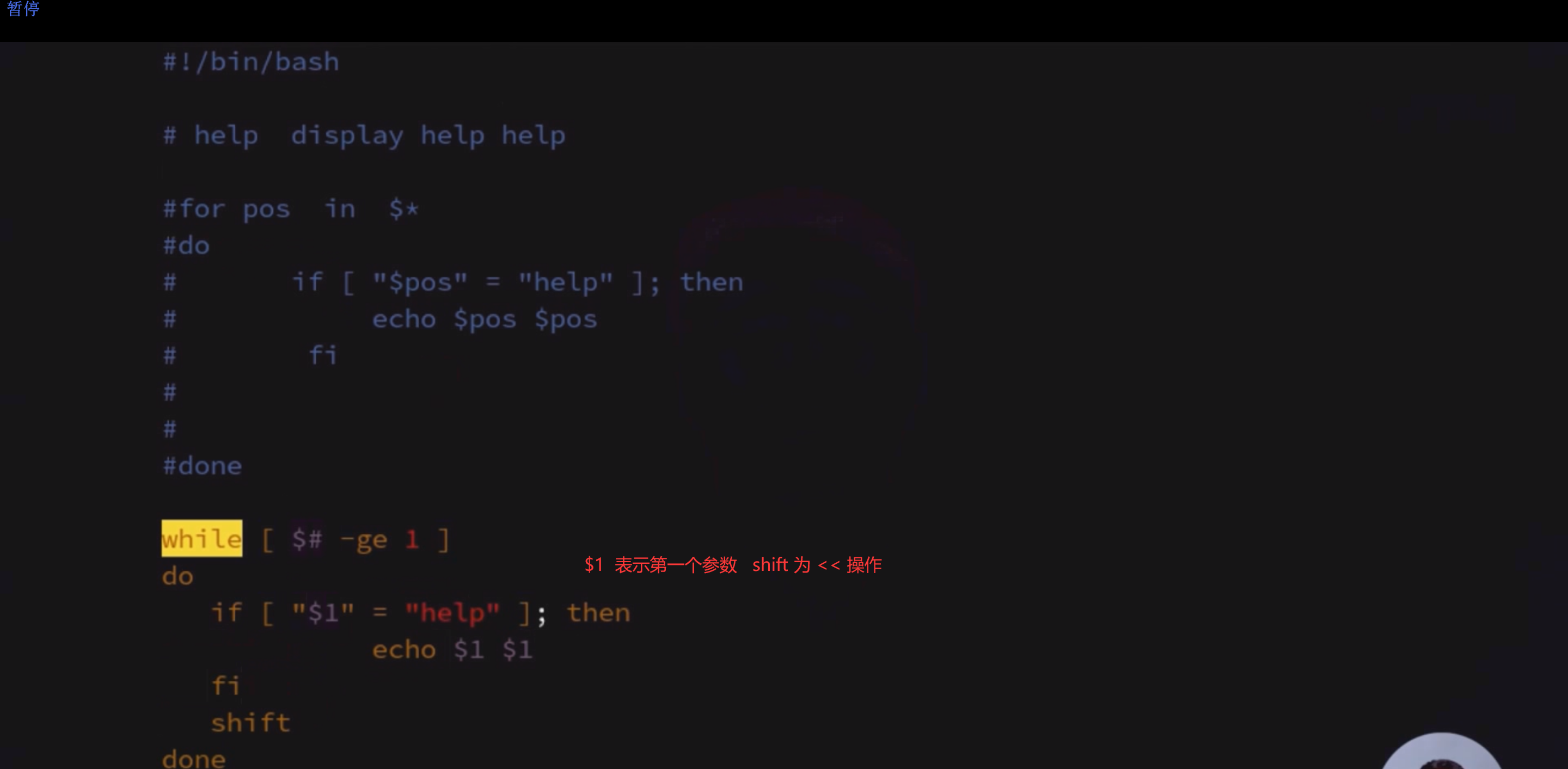
While循环
while循环,只要条件为true,就一直执行程序。
While [ 条件判断式 ]do程序done
until循环
和while循环相反,until循环时只要条件判断式不成立则进行循环,并执行循环程序。一旦循环条件成立,则终止循环。
Until [ 条件判断式 ]do程序done