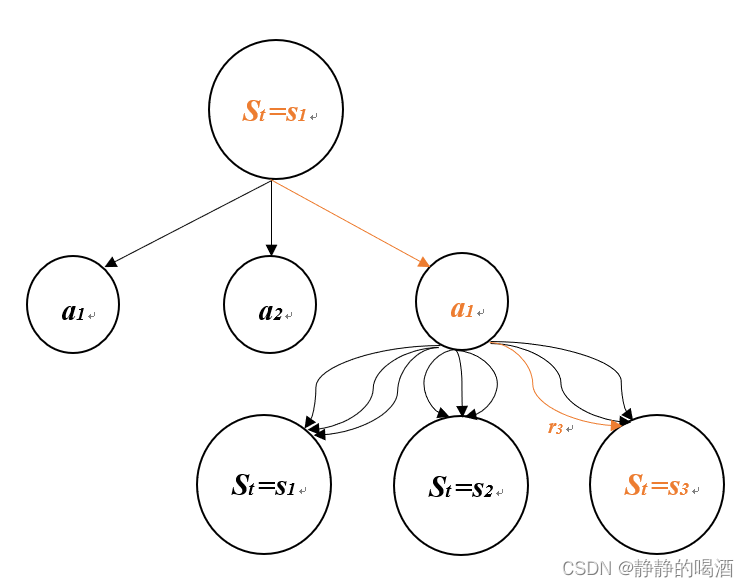
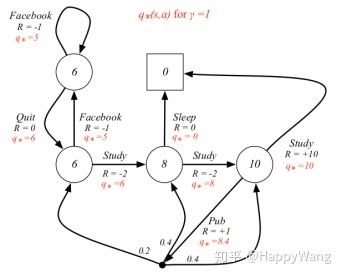
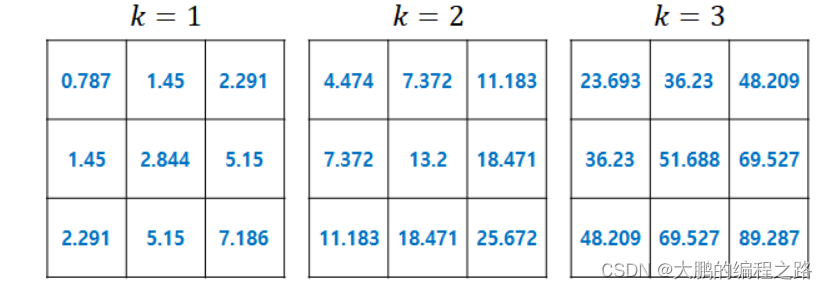
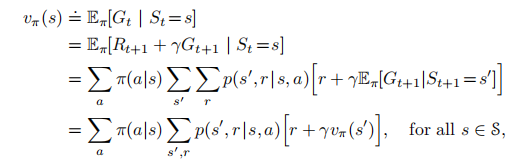贝尔曼方程(Bellman Equation)也被称作动态规划方程(Dynamic Programming Equation),由理查·贝尔曼(Richard Bellman)发现,由于其中运用了变分法思想,又被称之为现代变分法。
贝尔曼方程(Bellman Equation) 也被称作动态规划方程(Dynamic Programming Equation),由理查·贝尔曼(Richard Bellman)发现。
贝尔曼方程是动态规划(Dynamic Programming)这些种数学最佳化方法能够达到最佳化的必要条件。此方程把“决策问题在特定时间怎么的值”以“来自初始选择的报酬比从初始选择衍生的决策问题的值”的形式表示。借此这个方式把动态最佳化问题变成开简单的子问题,而这些子问题遵守从贝尔曼所提出来的“最佳化还原理”。
贝尔曼方程最早应用在工程领域的控制理论和其他应用数学领域,而后成为经济学上的重要工具。
几乎所有的可以用最佳控制理论(Optimal Control Theory)解决的问题也可以通过分析合适的贝尔曼方程得到解决。然而,贝尔曼方程通常指离散时间(discrete-time)最佳化问题的动态规划方程。
处理连续时间(continuous-time)最佳化问题上,也有类似那些偏微分方程,称作汉密尔顿-雅克比-贝尔曼方程(Hamilton–Jacobi–Bellman Equation,HJB Equation)。

1. TensorFlow入门基本教程
http://edu.csdn.net/course/detail/4369
http://edu.csdn.net/course/detail/4369
2. C++标准模板库从入门到精通
http://edu.csdn.net/course/detail/3324
3.跟老菜鸟学C++
http://edu.csdn.net/course/detail/2901
4. 跟老菜鸟学python
http://edu.csdn.net/course/detail/2592
5. 在VC2015里学会使用tinyxml库
http://edu.csdn.net/course/detail/2590
6. 在Windows下SVN的版本管理与实战
http://edu.csdn.net/course/detail/2579
7.Visual Studio 2015开发C++程序的基本使用
http://edu.csdn.net/course/detail/2570
http://edu.csdn.net/course/detail/2582
http://edu.csdn.net/course/detail/2672