在运行脚本时重复执行一系列的命令是很常见的,这时我们就需要使用循环语句来达到这个目的。
一、for命令
格式:for 变量 in 列表;do
循环体
done
for命令会遍历列表中的每一个值,并且在遍历完成后退出循环。
列表形式有以下几种:
1、在命令中定义的一系列的值;
2、变量;
3、命令;
4、目录;
5、文件。
实例1:
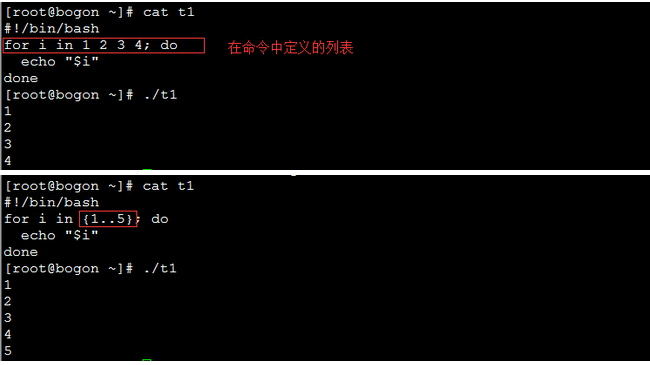
上例中使用{初始值..结束值}格式来表示一个区间的数值。
实例2:以变量作为列表:

实例3:用命令生成列表:

上例中使用seq命令来生成列表,seq命令的格式为:seq [初始值 步长] 终止值
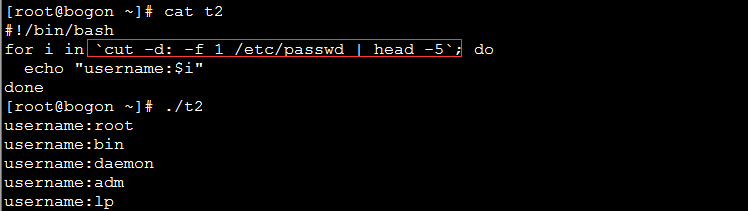
以上两个例子中使用反引号将得到命令运行的结果。
实例4:将目录作为列表:
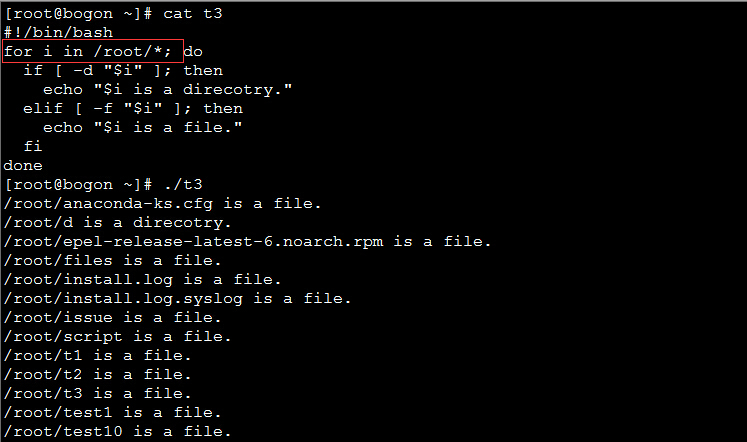
二、C语言风格的for命令
格式:for (( 变量赋值;循环终止条件;步长 )); do
循环体
done
实例:求从1加到100的和:

三、until命令
格式:until 条件; do
statement
...
done
until命令中的条件满足时则会退出循环。
实例:

四、while命令
格式:while 条件; do
statement
...
done
while命令当条件满足时则进入循环。
实例:

五、控制循环
1、break命令
作用:退出正在进行中的循环。
实例:如果变量i为3则退出循环。

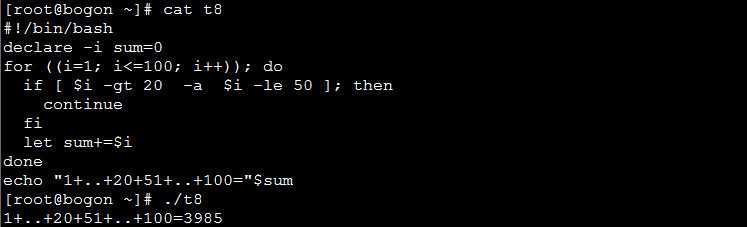
2、continue命令
作用:提前进入下一轮循环。
实例:将1到20和51到100之间的数相加:
六、while的殊用法
1、死循环
格式:while :; do
语句
done
实例:

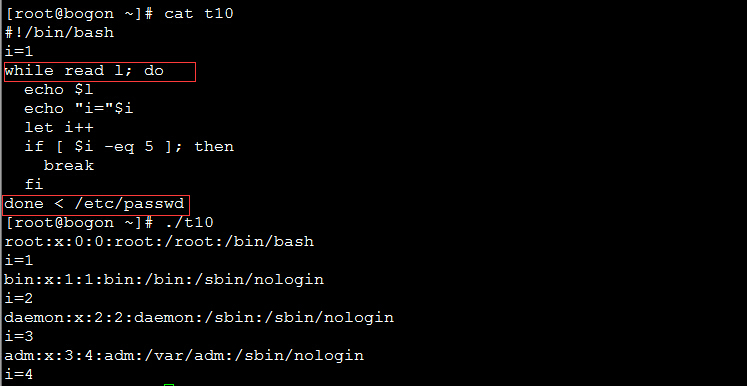
2、将文件内容逐行读入循环中
格式:while read 变量名; do
循环体
done < 文件
实例:逐行读入/etc/passwd文件的内容: