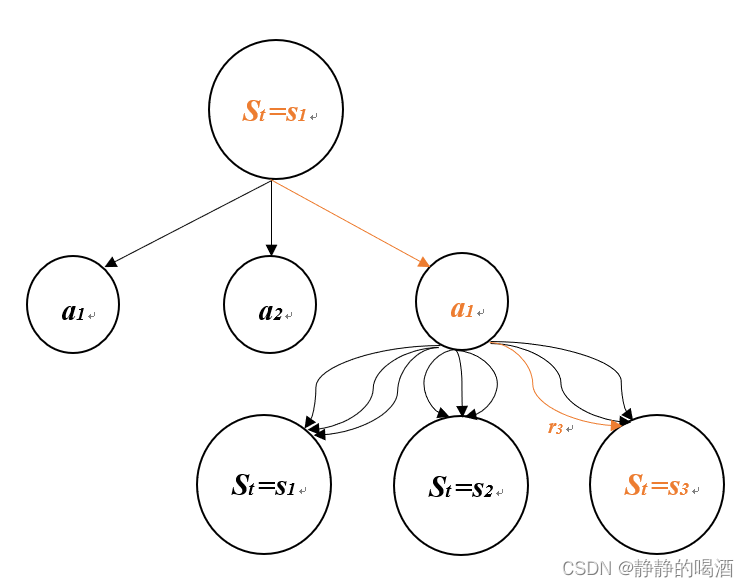
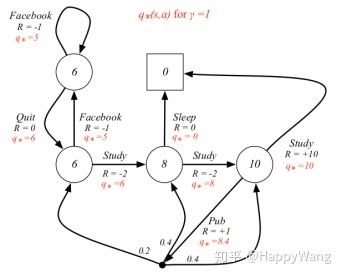
马尔可夫的动态特性:
![![马尔可夫的动态特性]](https://img-blog.csdnimg.cn/20210410100208243.png)
回报:(两种定义)
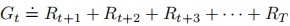
或
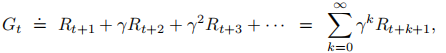
(折扣率大于等于0小于等于1,折扣率决定了未来收益的现值)
状态价值函数:从状态s开始,智能体按照策略π进行决策所获得回报的概率期望值
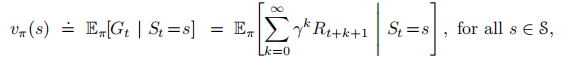
动作价值函数: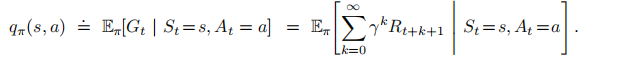
动作价值函数与状态价值函数的关系: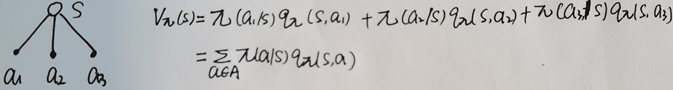
动作价值函数与马尔可夫的动态特性的关系: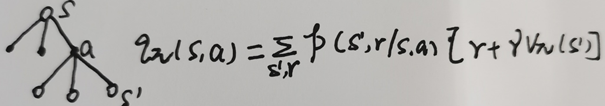
因此贝尔曼方程推导为:
或(原理一样,只不过我当时没看明白书上的推导,所以按照自己的理解根据回溯图手写了一下,其实手写和书上截图的推导是一样一样的)
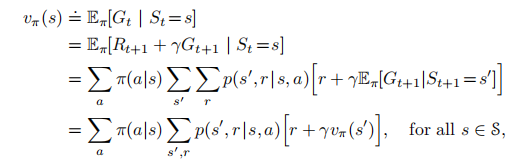
贝尔曼方程用等式表达了状态价值和后续状态价值之间的关系。