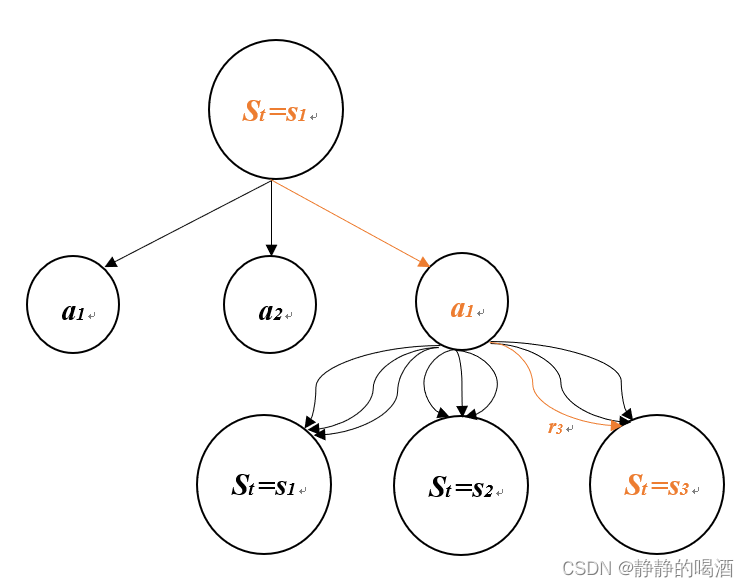
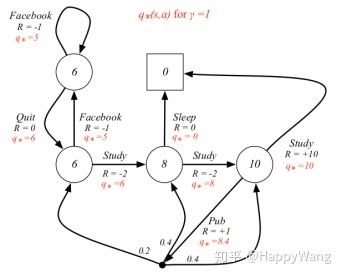
假设智能体观测到状态 s 0 s_0 s0,并且有 N N N个可用action,每个action都会导致另一种状态,及相应的奖励。另外,假设我们知道与状态s0相连的所有状态的价值 V i V_i Vi。在这种情况下,智能体可以采取的最佳行动是什么?

如果选择动作 a i a_i ai,价值为 V 0 ( a = a i ) = r i + V i V_0(a=a_i)=r_i+V_i V0(a=ai)=ri+Vi,如果要选择最佳动作,既要保证 a i a_i ai满足 V 0 = max a ∈ 1 , ⋯ , N ( r a + V a ) V_0=\max_{a\in1,\cdots,N}(r_a+V_a) V0=maxa∈1,⋯,N(ra+Va),如果考虑折扣因子的话就变成
V 0 = max a ∈ 1 , ⋯ , N ( r a + γ V a ) V_0=\max_{a\in1,\cdots,N}(r_a+\gamma V_a) V0=a∈1,⋯,Nmax(ra+γVa)
这个式子就是贝尔曼方程。
在此基础上,我们给环境加入一点不确定性,即,智能体执行action之后对环境产生的影响是不确定的,结果按照某种概率分布给出。

在这个例子中,智能体执行动作 a = 1 a=1 a=1后导致概率不同的三种结果,这时候价值计算就变成:
V 0 ( a = 1 ) = p 1 ( r 1 + γ V 1 ) + p 2 ( r 2 + γ V 2 ) + p 3 ( r 3 + γ V 3 ) V_0(a=1)=p_1(r_1+\gamma V_1)+p_2(r_2+\gamma V_2)+p_3(r_3+\gamma V_3) V0(a=1)=p1(r1+γV1)+p2(r2+γV2)+p3(r3+γV3)
用数学语言表述为
V 0 ( a ) = E s ∼ S [ r s , a + γ V s ] = ∑ s ∈ S p a , 0 → s ( r s , a + γ V s ) V_0\left( a \right) =\mathbb{E}_{s\sim S}\left[ r_{s,a}+\gamma V_s \right] =\sum_{s\in S}{p_{a,0\rightarrow s}\left( r_{s,a}+\gamma V_s \right)} V0(a)=Es∼S[rs,a+γVs]=s∈S∑pa,0→s(rs,a+γVs)
式中 p a , i → j p_{a,i\rightarrow j} pa,i→j表示从状态 i i i采取动作 a a a转移到状态 j j j的概率
同时我们考虑贝尔曼方程,就得到了一般情况下的贝尔曼最优方程
V 0 = max a ∈ A E s ∼ S [ r s , a + γ V s ] = max a ∈ A ∑ s ∈ S p a , 0 → s ( r s , a + γ V s ) V_0=\underset{a\in A}{\max}\mathbb{E}_{s\sim S}\left[ r_{s,a}+\gamma V_s \right] =\underset{a\in A}{\max}\sum_{s\in S}{p_{a,0\rightarrow s}\left( r_{s,a}+\gamma V_s \right)} V0=a∈AmaxEs∼S[rs,a+γVs]=a∈Amaxs∈S∑pa,0→s(rs,a+γVs)