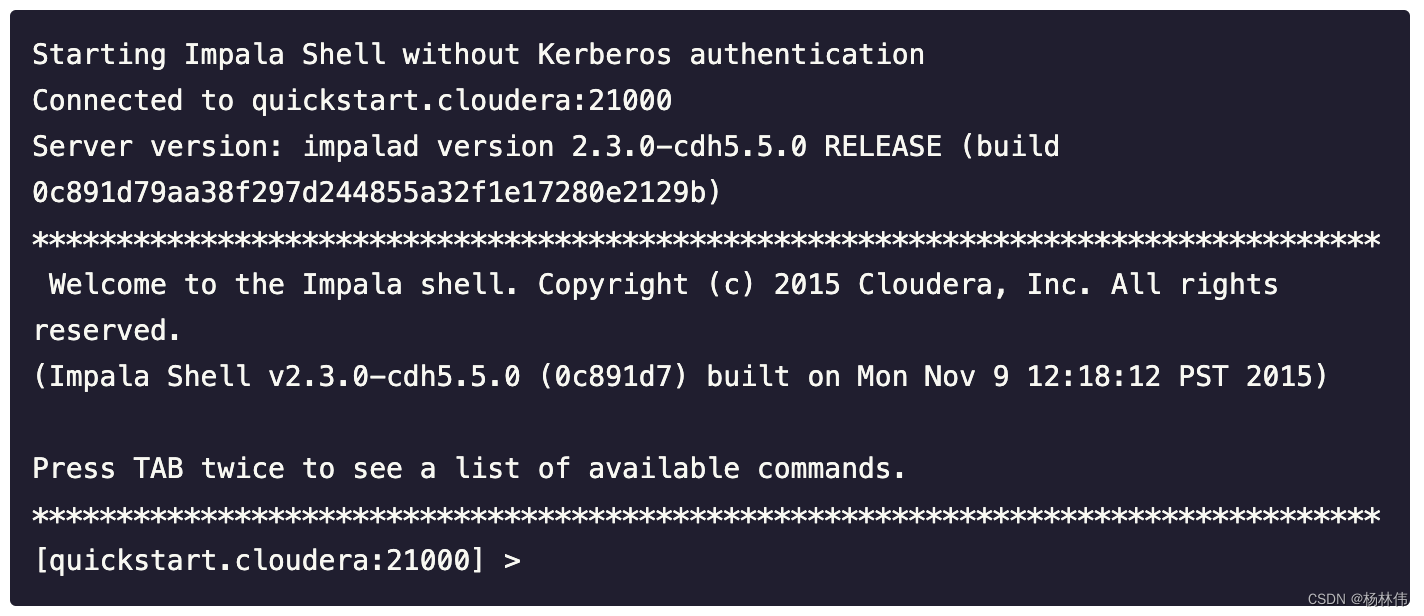
一、什么是Impala?
Impala是用于处理存储在Hadoop集群中的大量数据的MPP(大规模并行处理)SQL查询引擎。 它是一个用C ++和Java编写的开源软件。 与其他Hadoop的SQL引擎相比,它提供了高性能和低延迟。
换句话说,Impala是性能最高的SQL引擎(提供类似RDBMS的体验),它提供了访问存储在Hadoop分布式文件系统中的数据的最快方法。
二、为什么选择Impala?
Impala通过使用标准组件(如HDFS,HBase,Metastore,YARN和Sentry)将传统分析数据库的SQL支持和多用户性能与Apache Hadoop的可扩展性和灵活性相结合。
-
使用Impala,与其他SQL引擎(如Hive)相比,用户可以使用SQL查询以更快的方式与HDFS或HBase进行通信。
-
Impala可以读取Hadoop使用的几乎所有文件格式,如Parquet,Avro,RCFile。
Impala将相同的元数据,SQL语法(Hive SQL),ODBC驱动程序和用户界面(Hue Beeswax)用作Apache Hive,为面向批量或实时查询提供熟悉且统一的平台。
与Apache Hive不同,Impala不基于MapReduce算法。 它实现了一个基于守护进程的分布式架构,它负责在同一台机器上运行的查询执行的所有方面。
因此,它减少了使用MapReduce的延迟,这使Impala比Apache Hive快。
三、关系数据库与Impala区别
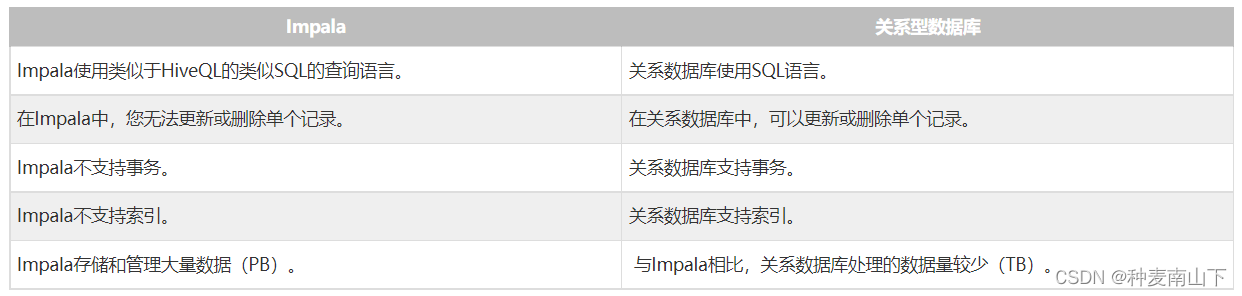
Impala使用类似于SQL和HiveQL的Query语言。 下表描述了SQL和Impala查询语言之间的一些关键差异。
四、Hive,Hbase和Impala
虽然Cloudera Impala使用与Hive相同的查询语言,元数据和用户界面,但在某些方面它与Hive和HBase不同。 下表介绍了HBase,Hive和Impala之间的比较分析。

五、数据库连接工具连接到Impala
1、SqlDbx
SqlDbx是一款快速且易于使用的数据库 SQL 开发 IDE,适用于在异构数据库环境中工作的数据库管理员、应用程序和数据库开发人员。

2、Impala ODBC Connector 2.6.0 for Cloudera Enterprise
Cloudera ODBC 驱动程序使您的企业用户能够通过具有 ODBC 支持的商业智能 (BI) 应用程序访问 Hadoop 数据。驱动程序通过将开放式数据库连接 (ODBC) 调用从应用程序转换为 SQL 并将 SQL 查询传递到基础 Impala 引擎来实现此目的。
Download Impala ODBC Connector 2.6.0 (cloudera.com)