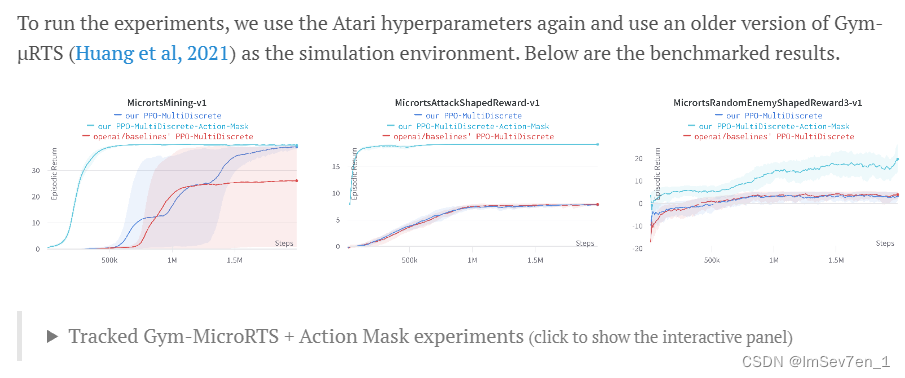
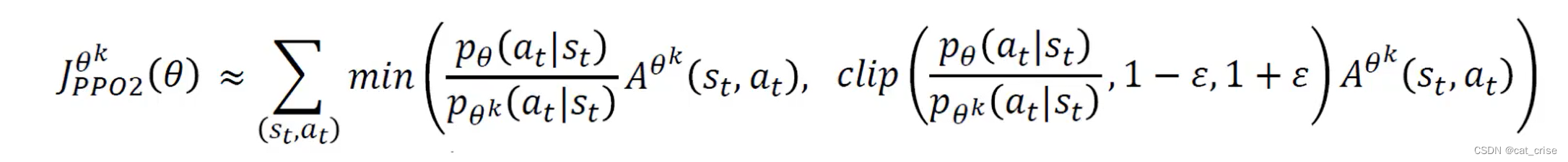原理:Proximal Policy Optimization近端策略优化(PPO)
视频:Proximal Policy Optimization (PPO) is Easy With PyTorch | Full PPO Tutorial
代码来自github:
Youtube-Code-Repository
EasyRL
网站:Neuralnet.ai
Package
import gym
import os
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.distributions.categorical import Categorical
Memory
sample():memory也就是一个batch分成多个mini batchpush():存储env.step后的trace信息,包括state,action,prob,val,reward,doneclear():更新完后清空memory,存放新的trace
class PPOmemory:def __init__(self, mini_batch_size):self.states = [] # 状态self.actions = [] # 实际采取的动作self.probs = [] # 动作概率self.vals = [] # critic输出的状态值self.rewards = [] # 奖励self.dones = [] # 结束标志self.mini_batch_size = mini_batch_size # minibatch的大小def sample(self):n_states = len(self.states) # memory记录数量=20batch_start = np.arange(0, n_states, self.mini_batch_size) # 每个batch开始的位置[0,5,10,15]indices = np.arange(n_states, dtype=np.int64) # 记录编号[0,1,2....19]np.random.shuffle(indices) # 打乱编号顺序[3,1,9,11....18]mini_batches = [indices[i:i + self.mini_batch_size] for i in batch_start] # 生成4个minibatch,每个minibatch记录乱序且不重复return np.array(self.states), np.array(self.actions), np.array(self.probs), \np.array(self.vals), np.array(self.rewards), np.array(self.dones), mini_batches# 每一步都存储trace到memorydef push(self, state, action, prob, val, reward, done):self.states.append(state)self.actions.append(action)self.probs.append(prob)self.vals.append(val)self.rewards.append(reward)self.dones.append(done)# 固定步长更新完网络后清空memorydef clear(self):self.states = []self.actions = []self.probs = []self.vals = []self.rewards = []self.dones = []
Actor
input:stateoutput:动作分布Categorical
actor网络即策略网络,输入state,输出action概率,使用Categorical生成动作分布
# actor:policy network
class Actor(nn.Module):def __init__(self, n_states, n_actions, hidden_dim):super(Actor, self).__init__()self.actor = nn.Sequential(nn.Linear(n_states, hidden_dim),nn.Tanh(),nn.Linear(hidden_dim, hidden_dim),nn.Tanh(),nn.Linear(hidden_dim, n_actions),nn.Softmax(dim=-1))def forward(self, state):dist = self.actor(state)dist = Categorical(dist)entropy = dist.entropy()return dist, entropy
Critic
input:stateoutput:状态值函数
critic网络即值网络,输入state,输出state-value
# critic:value network
class Critic(nn.Module):def __init__(self, n_states, hidden_dim):super(Critic, self).__init__()self.critic = nn.Sequential(nn.Linear(n_states, hidden_dim),nn.Tanh(),nn.Linear(hidden_dim, hidden_dim),nn.Tanh(),nn.Linear(hidden_dim, 1))def forward(self, state):value = self.critic(state)return value
Agent
choose_action():输入state,输出随机action,记录state的value以及action的对数problearn():更新actor和critic的网络参数
(1)计算GAE优势函数
(2)获取每个mini batch更新后的新策略
(3)执行clip操作得到actor loss
(4)更新估计状态值函数得到critic loss
(5)反向传播更新参数
class Agent:def __init__(self, n_states, n_actions, cfg):self.gamma = cfg.gammaself.policy_clip = cfg.policy_clipself.n_epochs = cfg.n_epochsself.gae_lambda = cfg.gae_lambdaself.device = cfg.deviceself.actor = Actor(n_states, n_actions, cfg.hidden_dim).to(self.device)self.critic = Critic(n_states, cfg.hidden_dim).to(self.device)self.actor_optimizer = optim.Adam(self.actor.parameters(), lr=cfg.actor_lr)self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=cfg.critic_lr)self.memory = PPOmemory(cfg.mini_batch_size)self.loss = 0def choose_action(self, state):state = torch.tensor(state, dtype=torch.float).to(self.device)dist, entropy = self.actor(state)value = self.critic(state)action = dist.sample()prob = torch.squeeze(dist.log_prob(action)).item()action = torch.squeeze(action).item()value = torch.squeeze(value).item()return action, prob, valuedef learn(self):for _ in range(self.n_epochs):state_arr, action_arr, old_prob_arr, vals_arr, reward_arr, dones_arr, batches = self.memory.sample()values = vals_arr[:]# 计算GAEadvantage = np.zeros(len(reward_arr), dtype=np.float32)for t in range(len(reward_arr) - 1):discount = 1a_t = 0for k in range(t, len(reward_arr) - 1):a_t += discount * (reward_arr[k] + self.gamma * values[k + 1] * (1 - int(dones_arr[k])) - values[k])discount *= self.gamma * self.gae_lambdaadvantage[t] = a_tadvantage = torch.tensor(advantage).to(self.device)# mini batch 更新values = torch.tensor(values).to(self.device)for batch in batches:states = torch.tensor(state_arr[batch], dtype=torch.float).to(self.device)old_probs = torch.tensor(old_prob_arr[batch]).to(self.device)actions = torch.tensor(action_arr[batch]).to(self.device)# 计算新的策略分布dist, entropy = self.actor(states)critic_value = torch.squeeze(self.critic(states))new_probs = dist.log_prob(actions)prob_ratio = new_probs.exp() / old_probs.exp()# actor_lossweighted_probs = advantage[batch] * prob_ratioweighted_clipped_probs = torch.clamp(prob_ratio, 1 - self.policy_clip,1 + self.policy_clip) * advantage[batch]actor_loss = -torch.min(weighted_probs, weighted_clipped_probs).mean()# critic_lossreturns = advantage[batch] + values[batch]critic_loss = (returns - critic_value) ** 2critic_loss = critic_loss.mean()# 更新entropy_loss = entropy.mean()total_loss = actor_loss + 0.5 * critic_loss - entropy_loss * 0.01self.loss = total_lossself.actor_optimizer.zero_grad()self.critic_optimizer.zero_grad()total_loss.backward()torch.nn.utils.clip_grad_norm_(self.actor.parameters(), 0.5)torch.nn.utils.clip_grad_norm_(self.critic.parameters(), 0.5)self.actor_optimizer.step()self.critic_optimizer.step()self.memory.clear()return self.lossdef save(self, path):actor_checkpoint = os.path.join(path, 'ppo_actor.pt')critic_checkpoint = os.path.join(path, 'ppo_critic.pt')torch.save(self.actor.state_dict(), actor_checkpoint)torch.save(self.critic.state_dict(), critic_checkpoint)def load(self, path):actor_checkpoint = os.path.join(path, 'ppo_actor.pt')critic_checkpoint = os.path.join(path, 'ppo_critic.pt')self.actor.load_state_dict(torch.load(actor_checkpoint))self.critic.load_state_dict(torch.load(critic_checkpoint))
参数
def get_args():parser = argparse.ArgumentParser(description="hyper parameters")parser.add_argument('--algo_name', default='PPO', type=str, help="name of algorithm")parser.add_argument('--env_name', default='CartPole-v1', type=str, help="name of environment")parser.add_argument('--train_eps', default=200, type=int, help="episodes of training")parser.add_argument('--test_eps', default=20, type=int, help="episodes of testing")parser.add_argument('--gamma', default=0.99, type=float, help="discounted factor")parser.add_argument('--mini_batch_size', default=5, type=int, help='mini batch size')parser.add_argument('--n_epochs', default=4, type=int, help='update number')parser.add_argument('--actor_lr', default=0.0003, type=float, help="learning rate of actor net")parser.add_argument('--critic_lr', default=0.0003, type=float, help="learning rate of critic net")parser.add_argument('--gae_lambda', default=0.95, type=float, help='GAE lambda')parser.add_argument('--policy_clip', default=0.2, type=float, help='policy clip')parser.add_argument('-batch_size', default=20, type=int, help='batch size')parser.add_argument('--hidden_dim', default=256, type=int, help='hidden dim')parser.add_argument('--device', default='cpu', type=str, help="cpu or cuda")args = parser.parse_args()return args
训练
def train(cfg, env, agent):print('开始训练!')print(f'环境:{cfg.env_name}, 算法:{cfg.algo_name}, 设备:{cfg.device}')rewards = []steps = 0for i_ep in range(cfg.train_eps):state = env.reset()done = Falseep_reward = 0while not done:action, prob, val = agent.choose_action(state)state_, reward, done, _ = env.step(action)steps += 1ep_reward += rewardagent.memory.push(state, action, prob, val, reward, done)if steps % cfg.batch_size == 0:agent.learn()state = state_rewards.append(ep_reward)if (i_ep + 1) % 10 == 0:print(f"回合:{i_ep + 1}/{cfg.train_eps},奖励:{ep_reward:.2f}")print('完成训练!')
环境
def env_agent_config(cfg, seed=1):env = gym.make(cfg.env_name)n_states = env.observation_space.shape[0]n_actions = env.action_space.nagent = Agent(n_states, n_actions, cfg)if seed != 0:torch.manual_seed(seed)env.seed(seed)np.random.seed(seed)return env, agent
运行
cfg = get_args()
env, agent = env_agent_config(cfg, seed=1)
train(cfg, env, agent)
结果
开始训练!
环境:CartPole-v1, 算法:PPO, 设备:cpu
回合:10/200,奖励:12.00
回合:20/200,奖励:52.00
回合:30/200,奖励:101.00
回合:40/200,奖励:141.00
回合:50/200,奖励:143.00
回合:60/200,奖励:118.00
回合:70/200,奖励:84.00
回合:80/200,奖励:500.00
回合:90/200,奖励:112.00
回合:100/200,奖励:149.00
回合:110/200,奖励:252.00
回合:120/200,奖励:500.00
回合:130/200,奖励:500.00
回合:140/200,奖励:500.00
回合:150/200,奖励:500.00
回合:160/200,奖励:500.00
回合:170/200,奖励:500.00
回合:180/200,奖励:500.00
回合:190/200,奖励:500.00
回合:200/200,奖励:500.00
完成训练!