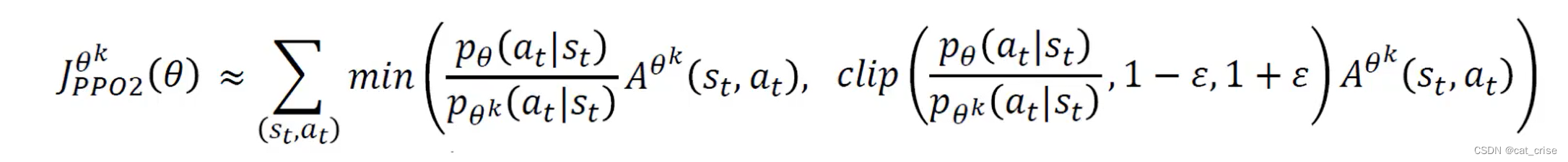优化PPO
- 介绍
- core implementation details
- 1.Vectorized architecture 量化结构
- Orthogonal Initialization of Weights and Constant Initialization of biases 算法权重的初始化以及恒定偏差的初始化
- The Adam Optimizer’s Epsilon Parameter Adam优化器的ε参数
- Adam Learning Rate Annealing Adam优化器的学习率退火
- Generalized Advantage Estimation(GAE)广义优势估计 in theory
- Mini-batch Updates 小批量更新 in code
- Normalization of Advantages 优势估计的正则化 in code
- Clipped surrogate objective 裁剪目标 in theory
- Value Function Loss Clipping 价值损失函数的裁剪 in code
- Overall Loss and Entropy Bonus 整体损失和熵平衡 in theory
- Global Gradient Clipping 全局梯度裁剪 in code
- Debug variables 调试变量 in code
- Shared and separate MLP networks for policy and value functions 策略函数和价值函数共享or独立的MLP神经网络 in code
- final
- Atari-specific implementation details
- details for continuous action domains
- Continuous actions via normal distributions 对连续动作采取正态分布 in theory
- State-independent log standard deviation 独立状态的log标准差??? in theory
- Independent action components 独立动作组件 in theory
- Separate MLP networks for policy and value functions 策略函数和价值函数共享or独立的MLP神经网络 in code
- Handling of action clipping to valid range and storage 对于动作的剪切到有效的范围以及存储的操作 in code
- Normalization of Observation 观测状态的正则化 in environment
- Observation Clipping 观测状态的裁剪 in environment
- Reward Scaling 奖励缩放 in environment
- Reward Clipping 奖励裁剪 in environment
- final
- LSTM implementation details
- Layer initialization for LSTM layers LSTM网络层的初始化 in network
- Initialize the LSTM states to be zeros LSTM状态的初始化 in network
- Reset LSTM states at the end of the episode 每次游戏结束时重置LSTM的状态 in theory
- Prepare sequential rollouts in mini-batches mini-batch顺序收集rollout阶段的数据 in theory
- Reconstruct LSTM states during training 训练过程中重构LSTM状态 in theory
- final
- MultiDiscrete action space detail
- Auxiliary implementation details
- Clip Range Annealing 裁剪区间退火 in code
- Parallellized Gradient Update 并行梯度更新 in code
- Early Stopping of the policy optimizations 策略优化(更新)的早期停止 in code
- Invalid Action Masking 掩盖无效动作 in theory
- final
介绍
本篇文章用于记录如何下手优化PPO表现效果。
37个实现细节:

core implementation details
1.Vectorized architecture 量化结构
针对于envs、obs、actions、done等数组维度的选择。(obs、actions、done维度与envs一致,所以这里主要针对于envs的维度选择)
envs的维度并不是越大越好。

N:num_envs
N*M:iteration_size
增加N虽然会提高训练的吞吐量,但是会使性能表现更差,多数人认为是经验块缩小(M更小)的原因导致的,所以为何不增加M来使算法运行时间延长呢?
对于N的选择,常常还需要考虑在多个游戏下的多个玩家考虑:

Orthogonal Initialization of Weights and Constant Initialization of biases 算法权重的初始化以及恒定偏差的初始化
总的来说:
- 算法隐藏层(hidden layer)权重的初始化常用np.sqrt(2)的比例(scale)。
- 策略输出层(the policy output layer)权重的初始化常用0.01的比例。
- 价值输出层(the valueoutput layer)常用1的比列初始化。
- 偏差(biases)常设为0。
介于此能够得到较优异的性能表现。

The Adam Optimizer’s Epsilon Parameter Adam优化器的ε参数
- PPO中常将Adam优化器的ε参数设为1e-5。
- Pytorch中设为1e-8。
- TensorFlow中设为1e-7。

Adam Learning Rate Annealing Adam优化器的学习率退火
Adam优化器的学习率可设为常数或者设置为从某一个值开始衰减,能够帮助提高智能体获得更高的episodic return。
通常默认:
- 在Atari 实验环境中,Adam学习率从2.5e-4线性衰减至0。
- 在MuJoCo实验环境中,Adam学习率从3e-4线性衰减至0。

Generalized Advantage Estimation(GAE)广义优势估计 in theory
- 如果下一个环境不是终态或没有被截断(截断一般是指智能体在环境中训练的时间限制),PPO估计子环境中下一个状态的价值作为价值目标。
- TD(λ),PPO中returns=advantages+values作为return目标,和TD(λ)用来价值估计相一致。
- 研究发现GAE的returns会使性能优于N-step returns。

Mini-batch Updates 小批量更新 in code
在PPO实现的学习阶段(learn phase)中,将N*M量的数据分割成小批量来计算梯度和更新策略。
错误实现:
- 使用整个batch即N*M来更新。
- 随机获取mini-batch。
Normalization of Advantages 优势估计的正则化 in code
正则化优势函数通常是通过减去均值后除标准差来正则化优势估计。注: In particular, this normalization happens at the minibatch level instead of the whole batch level!
Clipped surrogate objective 裁剪目标 in theory

基于此,可认为PPO裁剪可大大帮助PPO的性能,它能够达到和TRPO相类似的性能并且大大减少了计算能力。
Value Function Loss Clipping 价值损失函数的裁剪 in code
PPO更新价值网络通过使如下的价值损失函数最小化: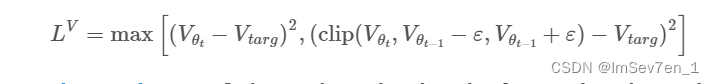
其中 V_targ=returns=advantages+values
但是研究发现目前没有发现value function loss clipping能优化性能,甚至会伤害性能表现。
Overall Loss and Entropy Bonus 整体损失和熵平衡 in theory
整体损失:loss = policy_loss - entropy * entropy_coefficient + value_loss * value_coefficient能够使entropy bonus最大化,能够使智能体的动作概率分布更随机些。(应当注意策略参数和价值参数共享相同的优化器。)
Global Gradient Clipping 全局梯度裁剪 in code
每一次迭代中,重新调整策略和价值的梯度,使全局的l2范数不超过0.5,能够稍微提升性能。

Debug variables 调试变量 in code

Shared and separate MLP networks for policy and value functions 策略函数和价值函数共享or独立的MLP神经网络 in code
- 默认地,PPO使用的MLP神经网络包含两层6各含4个神经元和
双曲正切作为激活函数,policy_head和value_head共享MLP神经网络的输出:

- 让策略函数和价值函数使用各自的神经网络

final
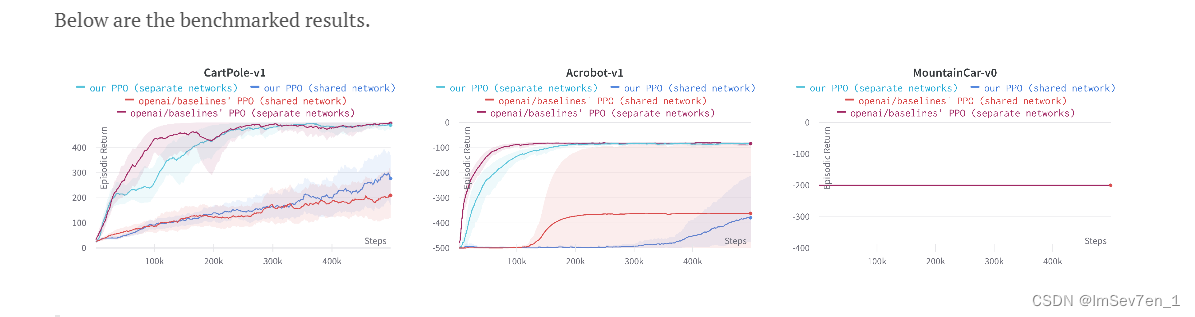
通过github库中的ppo.py(使用 separate-networks architecture)和ppo_shared.py(shared-network architecture)性能的比较可以看出使用独立的神经网络在实验环境中性能表现更优,而共享神经网络表现低下的原因很可能是因为策略和价值的目标竞争所导致的。
Atari-specific implementation details
details for continuous action domains
Continuous actions via normal distributions 对连续动作采取正态分布 in theory
- 策略梯度方法认为连续动作取样于正态分布,所以为了创建动作的正态分布,神经网络需要输出连续动作的均值和标准差
- 当在连续动作空间中,常使用高斯分布来表示动作的分布。
State-independent log standard deviation 独立状态的log标准差??? in theory
PPO的实现输出logits 的均值和logits标准差的对数而非logits的标准差,另外log std is set to be state-independent and initialized to be 0.(不懂)。
有人发现使用state-independent standard deviation性能和state-dependent standard deviation(也就是均值和标准差而非标准差的对数)两者性能相差无几。
Independent action components 独立动作组件 in theory
自认为是针对于多维度动作空间。
- 在许多机器人实验中,常需要有多个变量值来表示一个连续的动作,如
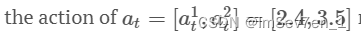
可能表示向左移动2.4单位 向上移动3.5单位。但由于大量文献表明这种行动是一个单一的标量值,所以为了统一,PPO将其视作为动作独立维度(组件)的概率如下: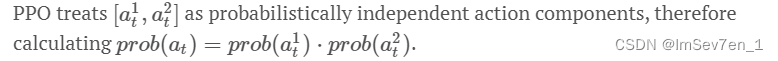
- 这个方法来源于目前常见的假设,
完全协方差的高斯分布用来表示策略,意味着对于每一个维度的动作选择是独立的。(但也有人认为不同维度间的动作是有所依赖的,如使用自回归策略来证明。)
Separate MLP networks for policy and value functions 策略函数和价值函数共享or独立的MLP神经网络 in code
与前方相同,不再赘述。
Handling of action clipping to valid range and storage 对于动作的剪切到有效的范围以及存储的操作 in code
在连续动作被取样后,该连续动作可能超出了环境的有效范围,为了避免此现象,加入了the rapper来裁剪动作至有效的范围,并且未被裁剪的action会作为episodic data的一部分存储。
由于高斯分布的取样没有边界,而环境通常对于动作空间有所约束,两种方法如下:
- 采用裁剪到边界的有效范围
- 采用对高斯样本使用可逆压缩函数如tanh来满足约束。
- 两种方法相差无几,但使用裁剪方法可以更好地获得与原文PPO一致的性能,而且由于裁剪带来的偏差有解决办法可解决。
Normalization of Observation 观测状态的正则化 in environment
在每一个时间步,VecNormalize 包装类会对观测进行预处理(即未处理的observation通过减去运行时的均值并除其方差来正则化。)
对输入使用正则化已成为训练神经网络的著名技术,对观测使用 a moving average normalization已成为默认的实现细节,值得指出的是对于观测的正则化对于性能的提升十分有用。
Observation Clipping 观测状态的裁剪 in environment
在对观测正则化后,VecNormalize 包装类还会对观测进行裁剪到一个范围,常为[-10,10]
有人发现观测裁剪并没有改善性能,但猜测在观察范围很广的环境中可能会起到作用。
Reward Scaling 奖励缩放 in environment
VecNormalize 包装类对reward使用某种基于折扣的方式(对奖励除折扣后奖励和的标准差。)
reward scaling能够显著影响算法的性能表现而且建议使用reward scaling
Reward Clipping 奖励裁剪 in environment
在对奖励缩放后,VecNormalize 包装类还会对奖励进行裁剪到一个范围,常为[-10,10]
但有人发现奖励裁剪并没有改善性能。
final
通过github库中的ppo.py进行修改得到ppo_continuous_action.py。

LSTM implementation details
LSTM(Long Short Term Memory),是具有记忆长短期信息能力的神经网络。LSTM提出的动机是为了解决长期依赖问题。传统的RNN节点输出仅由权值,偏置以及激活函数决定。RNN是一个链式结构,每个时间片使用的是相同的参数。
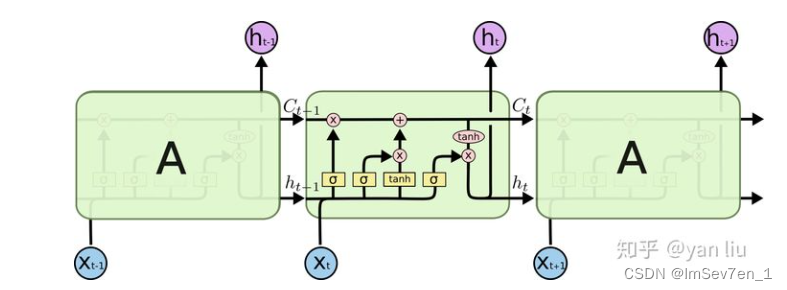
Layer initialization for LSTM layers LSTM网络层的初始化 in network
LSTM网络层的权重中std=1、偏差为0
Initialize the LSTM states to be zeros LSTM状态的初始化 in network
所有的状态初始化为0(向量)。
Reset LSTM states at the end of the episode 每次游戏结束时重置LSTM的状态 in theory
无论是在rollout阶段还是在learning阶段,每一次游戏结束后将状态重置为0(向量)。
Prepare sequential rollouts in mini-batches mini-batch顺序收集rollout阶段的数据 in theory
若无LSTM,mini-batch随机从训练数据中获取数据且不会对训练性能造成影响。
但在有LSTM的神经网络中,mini-batch需要顺序地从下一个训练环境中顺序获取数据(该数据的获取顺序对于LSTM是十分重要的)。
Reconstruct LSTM states during training 训练过程中重构LSTM状态 in theory
算法在rollout前会利用initial_lstm_state来保存LSTM初始状态的副本,这可以确保我们能够重建在rollout中用到的概率分布。(可以重复相同的rollout以获取我们想要的过程中的数据也就是能够进行实验回滚操作。)

final
通过github库中的ppo_atari.py进行修改得到ppo_atari_lstm.py。
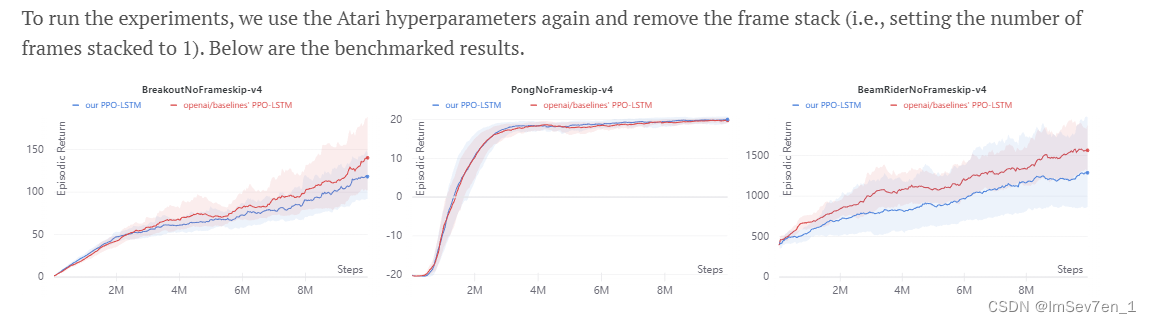
MultiDiscrete action space detail
MultiDiscrete action space 多重离散动作空间用来描述多重动作中每一动作的作用次数不同的离散空间(如键盘,其中的每一个键就代表着一个离散的动作空间)。
Gym官方解释如下:
对于多重离散动作空间,使用独立动作组件来处理:
在多重离散动作空间中,动作由众多离散动作值组成,PPO将整个动作看作为所有独立动作组件的概率。
通过github库中的ppo_atari.py进行修改得到ppo_multidiscrete.py。
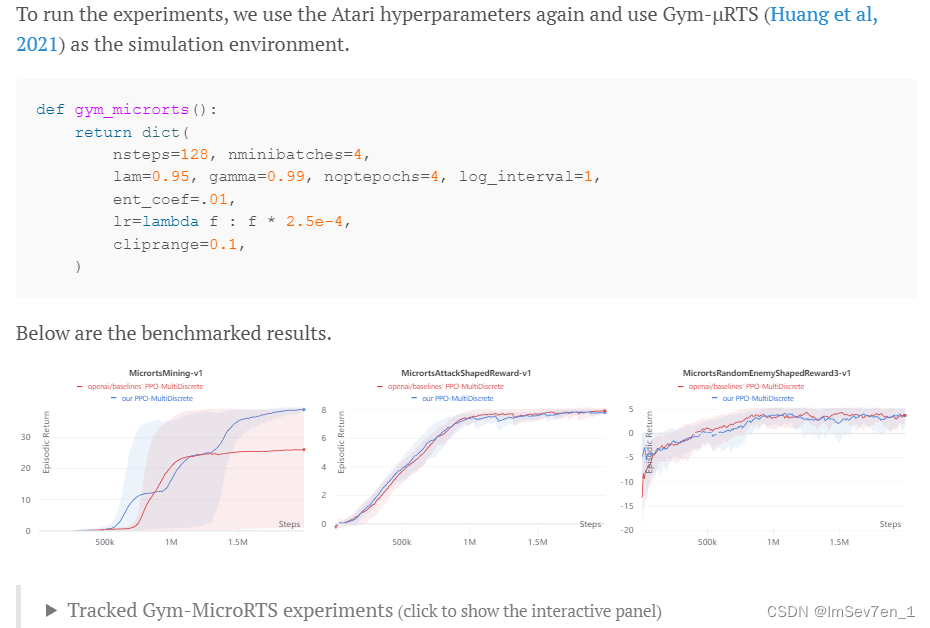
Auxiliary implementation details
4个在特殊情况下能有效改善PPO实现的细节,(官方PPO未用这四个细节实现)
Clip Range Annealing 裁剪区间退火 in code
和学习率衰减类似, PPO的裁剪系数也可以衰减退火。
Parallellized Gradient Update 并行梯度更新 in code
使用多进程来并行地进行梯度更新,常用在PPO1中,PPO2不常用。
Early Stopping of the policy optimizations 策略优化(更新)的早期停止 in code
- 策略优化(更新)的早期停止,可以看作为一种对于PPO实现中的
超参数noptepochs的显式置信度取域约束的一种附加机制。 - 更详细地来说,计算策略在更新前和更新一步后的网络权重的近似的平均KL散度,若此KL散度超过一个提前设置好的阈值,那么对于此策略的更新将会被提前停止。
- 此方法即用于策略的早期停止,也可用于价值网络的早期停止。

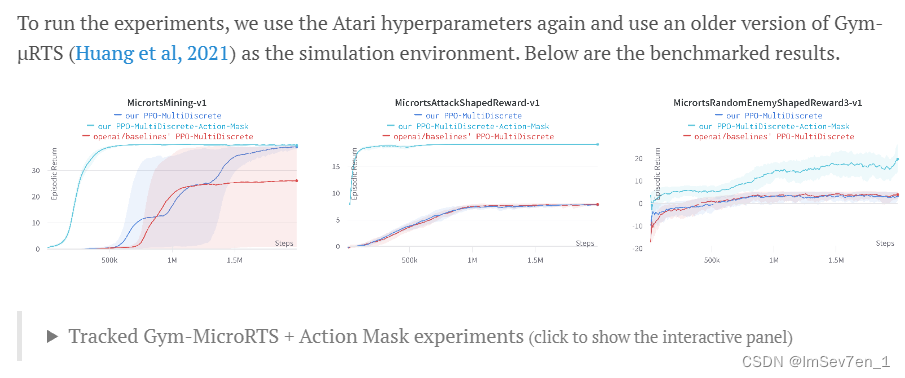
Invalid Action Masking 掩盖无效动作 in theory
- Invalid Action Masking技术在AlphaStar和OpenAI Five中效果显著,主要用来在智能体训练过程中对于当前游戏状态避免执行无效动作
- 更详细地说,在将logits传递给softmax前使用负无穷来代替无效动作的logits,这种操作实际上就是使无效操作对应的梯度为0。
- Furthermore, Huang et al, 2021 demonstrated invalid action masking to be the critical technique in training agents to win against all past μRTS bots they tested.
final
通过github库中的ppo_multidiscrete.py进行修改得到ppo_multidiscrete_mask.py。