目录
一、Impala概述
二、Impala优点
三、Impala和Hive
3.1 Impala和Hive的关系
3.2 Impala和Hive的区别
五、Impala查询过程
六、Impala安装
七、impala-shell命令
八、数据库语句
数据库命令
数据表命令
视图操作
Impala数据导入
刷新Impala数据
九、Java API
一、Impala概述
Impala是Cloudera公司推出,提供对HDFS、Hbase数据的高性能、低延迟的交互式SQL查询功能。
基于Hive使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点
- 与Apache Hive有相同的元数据、SQL语法、ODBC驱动、用户界面
- 能直接对存储在HDFS和HBase中的数据提供快速、交互式SQL查询
是CDH平台首选的PB级大数据实时查询分析引擎
二、Impala优点
- 熟悉的SQL接口
- 能够在Apache Hadoop中查询大量数据
- 集群环境中的分布式查询,以方便扩展和使用成本低廉的商品硬件
- 能够在不同的组件之间共享数据文件,没有复制或导出/导入步骤
- 用于大数据处理和分析的单一系统
三、Impala和Hive
3.1 Impala和Hive的关系
- 基于Hive的大数据分析查询引擎
- 使用Hive的元数据
- 兼容Hive的绝大部分语法
3.2 Impala和Hive的区别
Impala使用独立引擎,而不是MapReduce计算框架
优化技术
- 使用LLVM产生运行代码
- 利用可用的硬件指令
- 选择合适的数据存储格式
- 最大使用内存,中间结果不写磁盘
将执行计划表现为一颗完整的执行计划树
数据流采用拉数据的方式
使用simple-scheduler调度器进行调度
不进行容错处理,发生错误时直接返回
Hive适用于长时间的批处理查询分析,而Impala适用于实时交互式查询
Impala是Cloudera在受到Google的Dremel启发下开发的实时交互SQL大数据查询工具(实时SQL查询引擎Impala),Impala没有再使用缓慢的Hive+MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成),可以直接从HDFS或HBase中用SELECT、JOIN和统计函数查询数据,从而大大降低了延迟。

五、Impala查询过程
Impala主要由Impalad, State Store和CLI组成。
Impalad: 与DataNode运行在同一节点上,由Impalad进程表示,它接收客户端的查询请求(接收查询请求的Impalad为Coordinator,Coordinator通过JNI调用java前端解释SQL查询语句,生成查询计划树,再通过调度器把执行计划分发给具有相应数据的其它Impalad进行执行),读写数据,并行执行查询,并把结果通过网络流式的传送回给Coordinator,由Coordinator返回给客户端。同时Impalad也与State Store保持连接,用于确定哪个Impalad是健康和可以接受新的工作。
在Impalad中启动三个ThriftServer: beeswax_server(连接客户端),hs2_server(借用Hive元数据), be_server(Impalad内部使用)和一个ImpalaServer服务。
Impala State Store: 跟踪集群中的Impalad的健康状态及位置信息,由statestored进程表示,它通过创建多个线程来处理Impalad的注册订阅和与各Impalad保持心跳连接,各Impalad都会缓存一份State Store中的信息,当State Store离线后(Impalad发现State Store处于离线时,会进入recovery模式,反复注册,当State Store重新加入集群后,自动恢复正常,更新缓存数据)因为Impalad有State Store的缓存仍然可以工作,但会因为有些Impalad失效了,而已缓存数据无法更新,导致把执行计划分配给了失效的Impalad,导致查询失败。
CLI: 提供给用户查询使用的命令行工具(Impala Shell使用python实现),同时Impala还提供了Hue,JDBC, ODBC使用接口。

六、Impala安装
Impala的安装方式有三种:
通过源码自行编译
通过RPM包安装(需要解决依赖问题)
通过cloudera-manager平台安装(推荐)
七、impala-shell命令
外部命令指的是不需要进入到impala-shell交互命令行当中即可执行的命令参数
impala-shell后面执行的时候可以带很多参数
#查看帮助
impala-shell -h
#刷新元数据并进入impala
impala-shell -r
#执行一个SQL文件
impala-shell -f
#执行一个SQL命令
impala-shell -q
#连接到其他的impalad服务
impala-shell -i
#将结果输出到文件
impala-shell -o内部命令指的是进入impala-shell命令行之后可以执行的语法

八、数据库语句
数据库命令
-- 创建数据库
create database if not exists database_name;
-- 删除数据库
drop database if exists database_name cascade;
数据表命令
-- 创建表
create table if not exists table_name(field1 type1,field2,type2,...)
location 'file_dir'
-- 查询表信息
desc table_name;
-- 查询表信息(格式)
desc formatted table_name;
-- 插入数据
insert into table_name values(field1,field2,...);
-- 修改表名
alter table table_nameA rename to table_nameB;
-- 添加列
alter table table_name add columns(field type);
-- 删除列
alter table table_name drop field;
-- 修改列名
alter table table_name change fieldA fieldB type;
-- 清空表
truncate table table_name;
-- 删除表
drop table table_name;
视图操作
-- 创建视图
create view if not exists view_name as select field1,field2,... from table_name;
-- 查看视图
desc view_name;
-- 查看视图(格式)
desc formatted view_name;
-- 修改视图
alter view view_name as select field1,... from table_name;
-- 删除视图
drop view view_name;Impala数据导入
load 导入数据
-- 建表
create table table_name(field1 type1,field2 type2,...)
row format delimited
fields terminated by '\t'
-- 通过文件进行数据导入
load data inpath 'file_dir'insert 插入数据
-- 建表
create table table_name(field1 type1,field2 type2,...);
-- 通过insert插入数据into表示追加插入overwrite表示覆盖插入
insert into/overwrite table table_name values(field1,field2,...);通过select 语句导入数据
-- 通过select语句插入
create table table_nameB(field1 type1,field2 type2,...);
insert into table_nameB select field1,... from table_nameA;
-- 通过select 语句建表
create table table_nameB as select field1,... from table_nameA;刷新Impala数据
Impala catalogd 不是实时进行元数据抓取的,所以当Hive有了数据的更新,我们在Impala中需要手动刷新元数据
-- 增量刷新,主要用于刷新Hive当中数据表里面的数据改变情况
refresh dbname.tablename;
-- 全量刷新,性能消耗较大,主要用于Hive当中新建数据库或者数据表的时候进行刷新或者每天数仓批处理后执行
invalidate metadata;九、Java API
9.1 驱动包下载https://www.cloudera.com/downloads/connectors/impala/jdbc/2-5-28.html
9.2 创建java工程,创建普通的即可,把依赖添加到工程
9.3 编写代码
package com.wch;import java.sql.*;public class ImpalaDemo {public static void main(String[] args) {Connection conn = null;PreparedStatement ps = null;ResultSet rs = null;try {Class.forName("com.cloudera.impala.jdbc41.Driver");// 1.创建连接 Connectionconn = DriverManager.getConnection("jdbc:impala://localhost:21050");// 2.获取ps对象ps = conn.prepareStatement("select * from test.employee;");// 3.执行查询语句rs = ps.executeQuery();// 4.对查询到的结果进行遍历while (rs.next()){System.out.print(rs.getInt(1)+"\t");System.out.print(rs.getString(2)+"\t");System.out.print(rs.getInt(3)+"\t");System.out.print(rs.getString(4)+"\t");System.out.println();}} catch (ClassNotFoundException | SQLException e) {e.printStackTrace();} finally {try {rs.close();ps.close();conn.close();} catch (Exception e) {e.printStackTrace();}}}
}9.4 配置SSH隧道
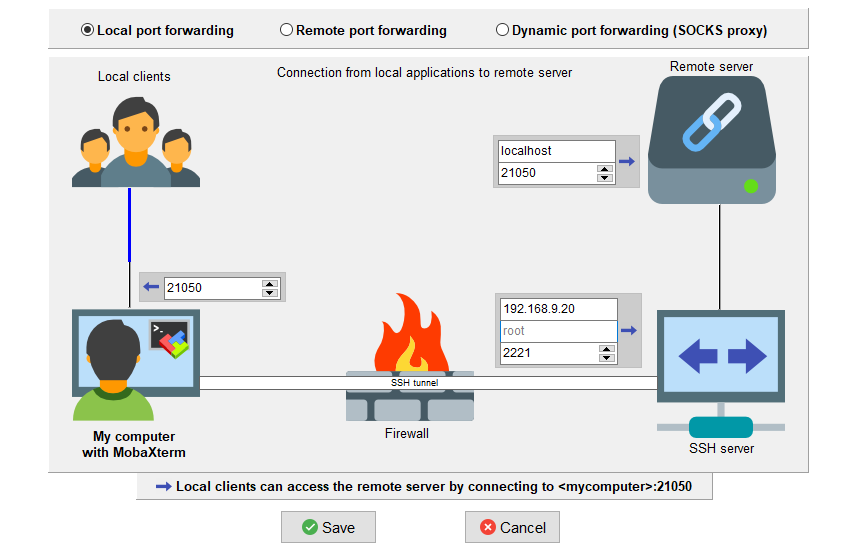
9.5 执行代码
2 Khilan 25 Delhi
5 Hardik 27 Bhopal
1 Ramesh 32 Ahmedabad
4 Chaitali 25 Mumbai
6 Komal 22 MP
3 kaushik 23 Kota