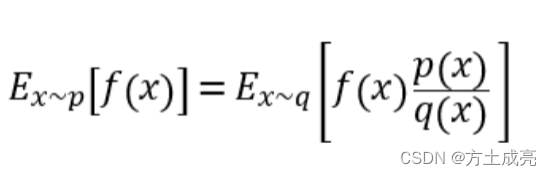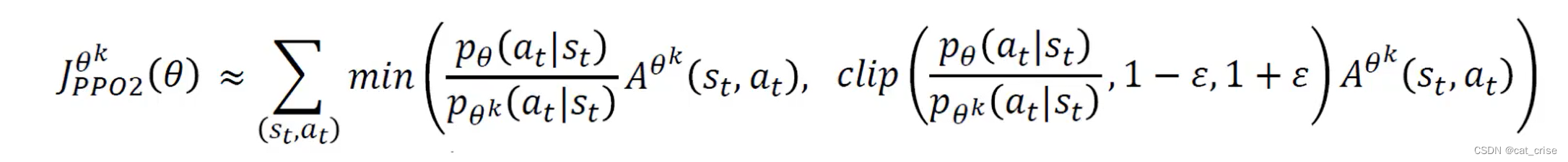阅读本文前对PPO的基本原理要有概念性的了解,本文基于我的上一篇文章:强化学习之PPO
当然,查看代码对于算法的理解直观重要,这使得你的知识不止停留在概念的层面,而是深入到应用层面。
代码采用了简单易懂的强化学习库PARL,对新手十分友好。
首先先来复述一下PARL的代码架构。强化学习可以看作智能体和环境交互学习的过程。而环境是独立于算法框架之外的内容。PARL把智能体分成了Agent,Algorthm,Model三个部分,这三个部分是层层嵌套的关系而不是相互独立的关系。Model负责定义神经网络模型,Algorithm负责利用Model的神经网络模型来定义算法。而Agent则负责利用算法来与环境进行交互和训练。

因此我们就分成三个部分来讲解PARL对PPO算法的实际应用。
如果想了解全貌,可以直接从主程序的main函数开始看。
神经网络模型
PPO是一个Actor-Critic算法,我们需要给它定义两个神经网络模型,一个给actor,一个给Critic:
import parl
import paddle
import paddle.nn as nnclass MujocoModel(parl.Model):def __init__(self, obs_dim, act_dim):super(MujocoModel, self).__init__()self.actor = Actor(obs_dim, act_dim)self.critic = Critic(obs_dim)def policy(self, obs):return self.actor(obs)def value(self, obs):return self.critic(obs)class Actor(parl.Model):def __init__(self, obs_dim, act_dim):super(Actor, self).__init__()self.fc1 = nn.Linear(obs_dim, 64)self.fc2 = nn.Linear(64, 64)self.fc_mean = nn.Linear(64, act_dim)# 此处创建了一个Tensor来表示标准差的log,用来提高模型的探索能力,并且这些参数可以自动优化self.log_std = paddle.static.create_parameter([act_dim],dtype='float32',default_initializer=nn.initializer.Constant(value=0))def forward(self, obs):x = paddle.tanh(self.fc1(obs))x = paddle.tanh(self.fc2(x))mean = self.fc_mean(x)return mean, self.log_stdclass Critic(parl.Model):def __init__(self, obs_dim):super(Critic, self).__init__()self.fc1 = nn.Linear(obs_dim, 64)self.fc2 = nn.Linear(64, 64)self.fc3 = nn.Linear(64, 1)def forward(self, obs):x = paddle.tanh(self.fc1(obs))x = paddle.tanh(self.fc2(x))value = self.fc3(x)return value
可以看到,这个文件非常简单,定义了actor和critic两个网络的结构,然后用再用一个类来封装它们。
这两个网络都是较为简单的输入状态,经过线性层和激活函数后,输出动作和value。注意这里的价值网络指的是状态价值而不是动作价值,所以只输入了状态而没有输入动作。
PPO算法
PPO有两种,第一种是用KL散度来限制更新幅度,第二种是直接clip更新幅度,一般现在用第二种方法。
import parl
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Normal
from parl.utils.utils import check_model_method__all__ = ['PPO']class PPO(parl.Algorithm):def __init__(self,model,clip_param,value_loss_coef,entropy_coef,initial_lr,eps=None,max_grad_norm=None,use_clipped_value_loss=True):# 检查两个网络check_model_method(model, 'value', self.__class__.__name__)check_model_method(model, 'policy', self.__class__.__name__)self.model = modelself.clip_param = clip_paramself.value_loss_coef = value_loss_coefself.entropy_coef = entropy_coefself.max_grad_norm = max_grad_normself.use_clipped_value_loss = use_clipped_value_lossself.optimizer = optim.Adam(model.parameters(), lr=initial_lr, eps=eps)def learn(self, obs_batch, actions_batch, value_preds_batch, return_batch,old_action_log_probs_batch, adv_targ):values = self.model.value(obs_batch)mean, log_std = self.model.policy(obs_batch)# 建立分布dist = Normal(mean, log_std.exp())# log_prob为计算定义的正态分布中对应的概率密度的对数,sum将其最后一个维度相加,并保持维度不变action_log_probs = dist.log_prob(actions_batch).sum(-1, keepdim=True)# 计算熵dist_entropy = dist.entropy().sum(-1).mean()# 这四行为PPO算法计算目标优化函数的公式,计算actor网络的lossratio = torch.exp(action_log_probs - old_action_log_probs_batch)surr1 = ratio * adv_targsurr2 = torch.clamp(ratio, 1.0 - self.clip_param,1.0 + self.clip_param) * adv_targaction_loss = -torch.min(surr1, surr2).mean()# 计算critic网络的lossif self.use_clipped_value_loss:value_pred_clipped = value_preds_batch + \(values - value_preds_batch).clamp(-self.clip_param, self.clip_param)value_losses = (values - return_batch).pow(2)value_losses_clipped = (value_pred_clipped - return_batch).pow(2)value_loss = 0.5 * torch.max(value_losses,value_losses_clipped).mean()else:value_loss = 0.5 * (return_batch - values).pow(2).mean()self.optimizer.zero_grad()# 三个Loss一定比例相加,其中为了增加探索性,熵越大越好,因此为负(value_loss * self.value_loss_coef + action_loss -dist_entropy * self.entropy_coef).backward()nn.utils.clip_grad_norm_(self.model.parameters(), self.max_grad_norm)self.optimizer.step()return value_loss.item(), action_loss.item(), dist_entropy.item()# actor和critic的输出def sample(self, obs):value = self.model.value(obs)mean, log_std = self.model.policy(obs)# 通过均值和标准差建立高斯分布dist = Normal(mean, log_std.exp())# 对分布进行采样action = dist.sample()# log_prob为计算定义的正态分布中对应的概率密度的对数,sum将其最后一个维度相加,并保持维度不变action_log_probs = dist.log_prob(action).sum(-1, keepdim=True)return value, action, action_log_probs# 通过输入状态到actor来预测动作输出def predict(self, obs):mean, _ = self.model.policy(obs)return mean# 通过输入状态到critic来计算def value(self, obs):return self.model.value(obs)智能体
智能体初始化的参数中传入了algorithm,说明PPO算法是嵌套在智能体中的。
import parl
import paddleclass MujocoAgent(parl.Agent):def __init__(self, algorithm):super(MujocoAgent, self).__init__(algorithm)# 通过状态来预测动作输出def predict(self, obs):obs = paddle.to_tensor(obs, dtype='float32')action = self.alg.predict(obs)return action.detach().numpy()# 给定状态,预测状态价值,动作,以及动作概率密度的对数的加和def sample(self, obs):obs = paddle.to_tensor(obs)value, action, action_log_probs = self.alg.sample(obs)return value.detach().numpy(), action.detach().numpy(), \action_log_probs.detach().numpy()# 重要!调用该函数即进行学习def learn(self, next_value, gamma, gae_lambda, ppo_epoch, num_mini_batch,rollouts):""" Learn current batch of rollout for ppo_epoch epochs.Args:next_value (np.array): next predicted value for calculating advantagegamma (float): the discounting factorgae_lambda (float): lambda for calculating n step returnppo_epoch (int): number of epochs Knum_mini_batch (int): number of mini-batchesrollouts (RolloutStorage): the rollout storage that contains the current rollout"""value_loss_epoch = 0action_loss_epoch = 0dist_entropy_epoch = 0# PPO中每次学习迭代的次数ppo_epochfor e in range(ppo_epoch):# 得到采样的数据data_generator = rollouts.sample_batch(next_value, gamma,gae_lambda, num_mini_batch)for sample in data_generator:obs_batch, actions_batch, \value_preds_batch, return_batch, old_action_log_probs_batch, \adv_targ = sampleobs_batch = paddle.to_tensor(obs_batch)actions_batch = paddle.to_tensor(actions_batch)value_preds_batch = paddle.to_tensor(value_preds_batch)return_batch = paddle.to_tensor(return_batch)old_action_log_probs_batch = paddle.to_tensor(old_action_log_probs_batch)adv_targ = paddle.to_tensor(adv_targ)# 使用PPO计算Loss,并自己调整网络参数value_loss, action_loss, dist_entropy = self.alg.learn(obs_batch, actions_batch, value_preds_batch, return_batch,old_action_log_probs_batch, adv_targ)value_loss_epoch += value_lossaction_loss_epoch += action_lossdist_entropy_epoch += dist_entropynum_updates = ppo_epoch * num_mini_batchvalue_loss_epoch /= num_updatesaction_loss_epoch /= num_updatesdist_entropy_epoch /= num_updatesreturn value_loss_epoch, action_loss_epoch, dist_entropy_epoch# 给定状态,评估状态价值def value(self, obs):obs = paddle.to_tensor(obs)val = self.alg.value(obs)return val.detach().numpy()storage
储存信息的类
import numpy as np
from paddle.io import BatchSampler, RandomSamplerclass RolloutStorage(object):def __init__(self, num_steps, obs_dim, act_dim):self.num_steps = num_stepsself.obs_dim = obs_dimself.act_dim = act_dimself.obs = np.zeros((num_steps + 1, obs_dim), dtype='float32')self.actions = np.zeros((num_steps, act_dim), dtype='float32')self.value_preds = np.zeros((num_steps + 1, ), dtype='float32')self.returns = np.zeros((num_steps + 1, ), dtype='float32')self.action_log_probs = np.zeros((num_steps, ), dtype='float32')self.rewards = np.zeros((num_steps, ), dtype='float32')self.masks = np.ones((num_steps + 1, ), dtype='bool')self.bad_masks = np.ones((num_steps + 1, ), dtype='bool')self.step = 0def append(self, obs, actions, action_log_probs, value_preds, rewards,masks, bad_masks):self.obs[self.step + 1] = obsself.actions[self.step] = actionsself.rewards[self.step] = rewardsself.action_log_probs[self.step] = action_log_probsself.value_preds[self.step] = value_predsself.masks[self.step + 1] = masksself.bad_masks[self.step + 1] = bad_masksself.step = (self.step + 1) % self.num_stepsdef sample_batch(self,next_value,gamma,gae_lambda,num_mini_batch,mini_batch_size=None):# calculate return and advantage firstself.compute_returns(next_value, gamma, gae_lambda)advantages = self.returns[:-1] - self.value_preds[:-1]advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-5)# generate sample batchmini_batch_size = self.num_steps // num_mini_batchsampler = BatchSampler(sampler=RandomSampler(range(self.num_steps)),batch_size=mini_batch_size,drop_last=True)for indices in sampler:obs_batch = self.obs[:-1][indices]actions_batch = self.actions[indices]value_preds_batch = self.value_preds[:-1][indices]returns_batch = self.returns[:-1][indices]old_action_log_probs_batch = self.action_log_probs[indices]value_preds_batch = value_preds_batch.reshape(-1, 1)returns_batch = returns_batch.reshape(-1, 1)old_action_log_probs_batch = old_action_log_probs_batch.reshape(-1, 1)adv_targ = advantages[indices]adv_targ = adv_targ.reshape(-1, 1)yield obs_batch, actions_batch, value_preds_batch, returns_batch, old_action_log_probs_batch, adv_targdef after_update(self):self.obs[0] = np.copy(self.obs[-1])self.masks[0] = np.copy(self.masks[-1])self.bad_masks[0] = np.copy(self.bad_masks[-1])def compute_returns(self, next_value, gamma, gae_lambda):self.value_preds[-1] = next_valuegae = 0for step in reversed(range(self.rewards.size)):delta = self.rewards[step] + gamma * self.value_preds[step + 1] * self.masks[step + 1] - self.value_preds[step]gae = delta + gamma * gae_lambda * self.masks[step + 1] * gaegae = gae * self.bad_masks[step + 1]self.returns[step] = gae + self.value_preds[step]
主程序
from collections import deque
import numpy as np
import paddle
import gym
from mujoco_model import MujocoModel
from mujoco_agent import MujocoAgent
from storage import RolloutStorage
from parl.algorithms import PPO
from parl.env.mujoco_wrappers import wrap_rms, get_ob_rms
from parl.utils import summary
import argparseLR = 3e-4
GAMMA = 0.99
EPS = 1e-5 # Adam optimizer epsilon (default: 1e-5)
GAE_LAMBDA = 0.95 # Lambda parameter for calculating N-step advantage
ENTROPY_COEF = 0. # Entropy coefficient (ie. c_2 in the paper)
VALUE_LOSS_COEF = 0.5 # Value loss coefficient (ie. c_1 in the paper)
MAX_GRAD_NROM = 0.5 # Max gradient norm for gradient clipping
NUM_STEPS = 2048 # data collecting time steps (ie. T in the paper)
PPO_EPOCH = 10 # number of epochs for updating using each T data (ie K in the paper)
CLIP_PARAM = 0.2 # epsilon in clipping loss (ie. clip(r_t, 1 - epsilon, 1 + epsilon))
BATCH_SIZE = 32# Logging Params
LOG_INTERVAL = 1# 用于评估策略
def evaluate(agent, ob_rms):eval_env = gym.make(args.env)eval_env.seed(args.seed + 1)eval_env = wrap_rms(eval_env, GAMMA, test=True, ob_rms=ob_rms)eval_episode_rewards = []obs = eval_env.reset()while len(eval_episode_rewards) < 10:action = agent.predict(obs)# Observe reward and next obsobs, _, done, info = eval_env.step(action)# get validation rewards from info['episode']['r']if done:eval_episode_rewards.append(info['episode']['r'])eval_env.close()print(" Evaluation using {} episodes: mean reward {:.5f}\n".format(len(eval_episode_rewards), np.mean(eval_episode_rewards)))return np.mean(eval_episode_rewards)def main():paddle.seed(args.seed)# 创建环境env = gym.make(args.env)env.seed(args.seed)env = wrap_rms(env, GAMMA)# 创建模型model = MujocoModel(env.observation_space.shape[0],env.action_space.shape[0])# 根据模型创建PPO算法algorithm = PPO(model, CLIP_PARAM, VALUE_LOSS_COEF, ENTROPY_COEF, LR, EPS,MAX_GRAD_NROM)# 根据PPO算法创建智能体agent = MujocoAgent(algorithm)# 实例化一个数据存储的类rollouts = RolloutStorage(NUM_STEPS, env.observation_space.shape[0],env.action_space.shape[0])# 重置环境,获取第一个状态,并存入rolloutsobs = env.reset()rollouts.obs[0] = np.copy(obs)# 创建队列episode_rewards = deque(maxlen=10)num_updates = int(args.train_total_steps) // NUM_STEPS# 开始训练,训练总步数为args.train_total_stepsfor j in range(num_updates):for step in range(NUM_STEPS):# 得到当前的状态,由两个神经网络得到状态价值,动作,以及概率密度函数的加和value, action, action_log_prob = agent.sample(rollouts.obs[step])# 把动作输入环境中,得到下一个状态,奖励,是否游戏结束,以及信息obs, reward, done, info = env.step(action)# 把奖励信息添加到列表中if done:episode_rewards.append(info['episode']['r'])# 其他信息masks = paddle.to_tensor([[0.0]] if done else [[1.0]], dtype='float32')bad_masks = paddle.to_tensor([[0.0]] if 'bad_transition' in info.keys() else [[1.0]],dtype='float32')# 给rollouts添加信息rollouts.append(obs, action, action_log_prob, value, reward, masks,bad_masks)# 输入下一个状态,得到下一个状态对应的状态价值next_value = agent.value(rollouts.obs[-1])# 关键一行,计算Loss,并进行一次学习,一次学习中包含若干个PPO epochvalue_loss, action_loss, dist_entropy = agent.learn(next_value, GAMMA, GAE_LAMBDA, PPO_EPOCH, BATCH_SIZE, rollouts)rollouts.after_update()# 打印信息if j % LOG_INTERVAL == 0 and len(episode_rewards) > 1:total_num_steps = (j + 1) * NUM_STEPSprint("Updates {}, num timesteps {},\n Last {} training episodes: mean/median reward {:.1f}/{:.1f}, min/max reward {:.1f}/{:.1f}\n".format(j, total_num_steps, len(episode_rewards),np.mean(episode_rewards), np.median(episode_rewards),np.min(episode_rewards), np.max(episode_rewards),dist_entropy, value_loss, action_loss))# 评估智能体if (args.test_every_steps is not None and len(episode_rewards) > 1and j % args.test_every_steps == 0):ob_rms = get_ob_rms(env)eval_mean_reward = evaluate(agent, ob_rms)summary.add_scalar('ppo/mean_validation_rewards', eval_mean_reward,(j + 1) * NUM_STEPS)if __name__ == "__main__":parser = argparse.ArgumentParser(description='RL')parser.add_argument('--seed', type=int, default=616, help='random seed (default: 616)')parser.add_argument('--test_every_steps',type=int,default=10,help='eval interval (default: 10)')parser.add_argument('--train_total_steps',type=int,default=10e5,help='number of total time steps to train (default: 10e5)')parser.add_argument('--env',default='Hopper-v3',help='environment to train on (default: Hopper-v3)')args = parser.parse_args()main()注意事项
- 在运行程序之前要安装好mujoco,有坑。
- 可以看到PPO算法采用了三个Loss,目的如下:首先actor的Loss是为了让优势函数A越高越好 ,Critic的Loss是让其输出与目标输出越接近越好,而actor输出分布的熵让它在达成目的的同时越大越好,有利于系统的稳定性。