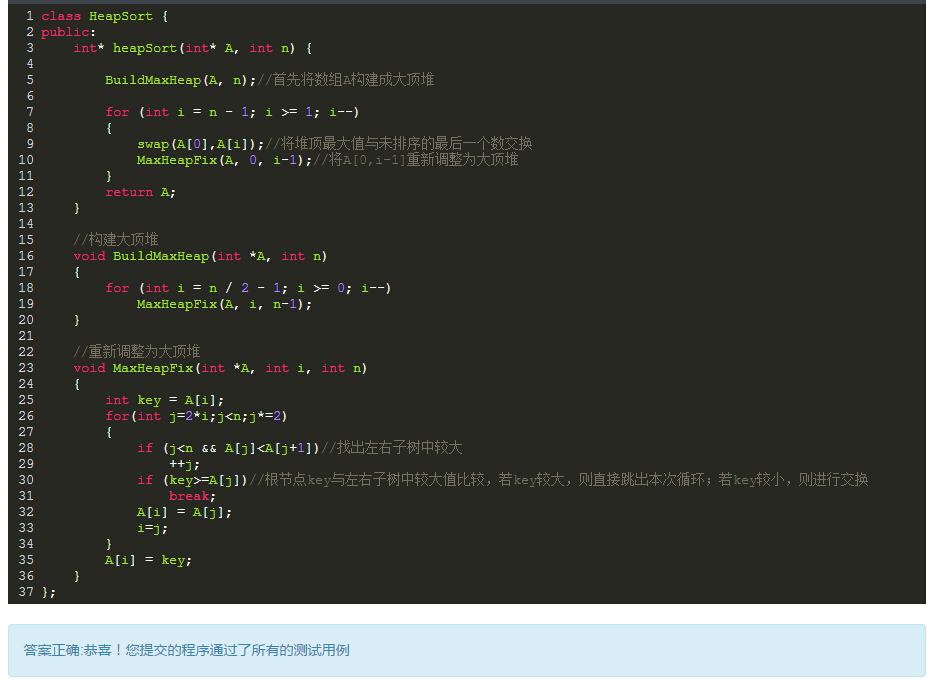
一、概述:
Java递归:简单说就是函数自身直接或间接调用函数的本身。
二、应用场景:
若:一个功能在被重复使用,并每次使用时,参与运算的结果和上一次调用有关,这时就可以使用递归来解决这个问题。
使用要点:
1,递归一定明确条件。否则容易栈溢出。
2,注意一下递归的次数。
三、示例:
最简单的递归演示
public class recursionDemo {public static void main(String[] args) {show();}private static void show() {method();}private static void method() {show();}}四、实际示例
我们都知道 6的二进制是110,那么程序是怎么执行的呢?
代码示例:
public static void main(String[] args) {toBin(6);}private static void toBin(int num) {if (num>0){//取余System.out.println(num%2);toBin(num/2);}} 
运行过程:
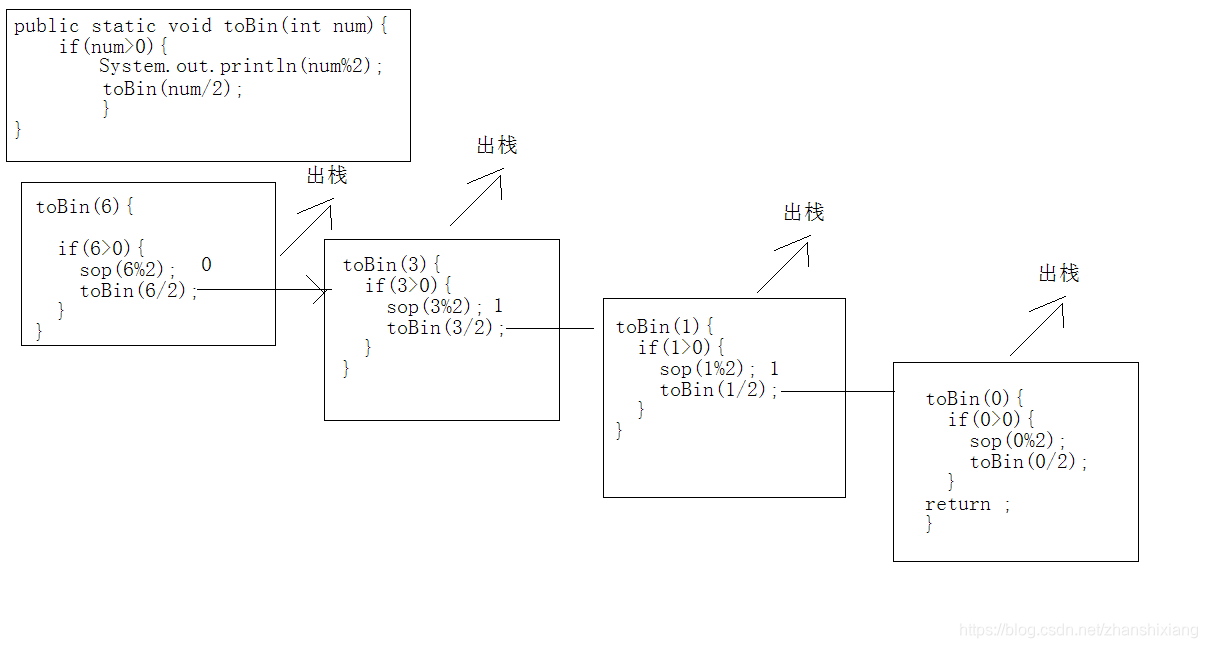
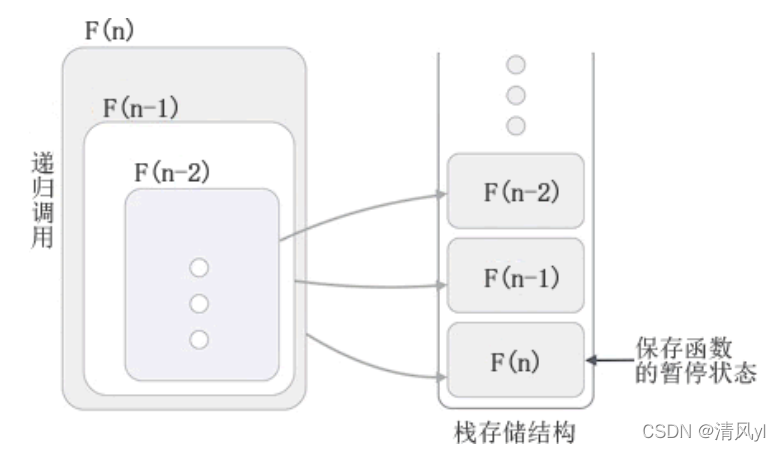
2、递归演示二:计算1-5,求和
public static void main(String[] args) {//1-5求和int sum = getSum(5);System.out.println(sum);}private static int getSum(int num) {int x=9;if (num==1){return 1;}return num+getSum(num-1);} 
程序运行图:
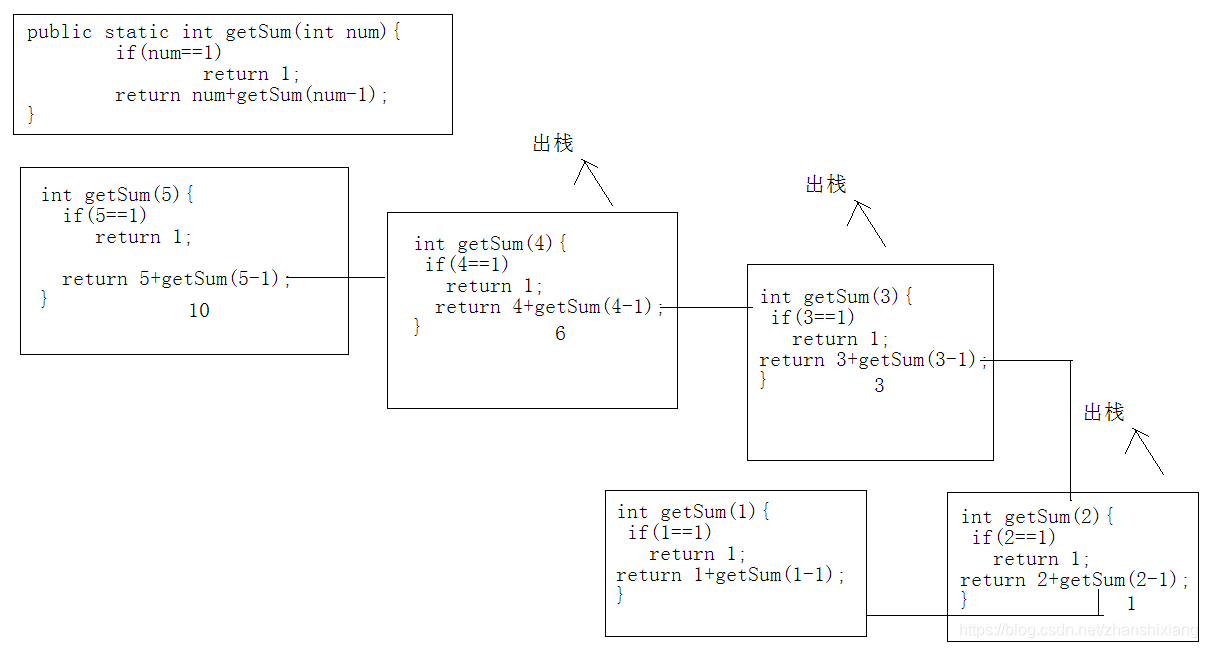
五、递归的缺点
在使用递归时,一定要考虑递归的次数,负责很容易造成虚拟机 “栈溢出”。
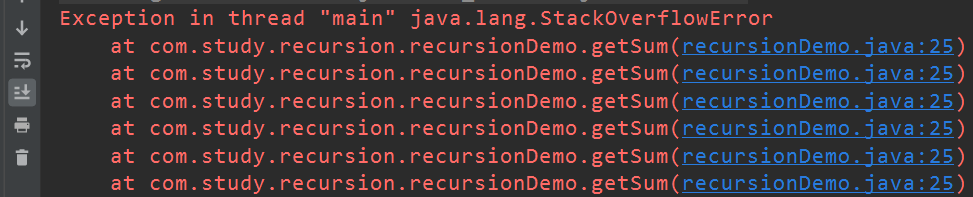
仍然使用上面的求和代码,只是这次将求和基数变为 90000000,看看结果如何
public static void main(String[] args) {//1-90000000求和int sum = getSum(90000000);System.out.println(sum);}private static int getSum(int num) {int x=9;if (num==1){return 1;}return num+getSum(num-1);}果然就造成了虚拟机栈溢出。