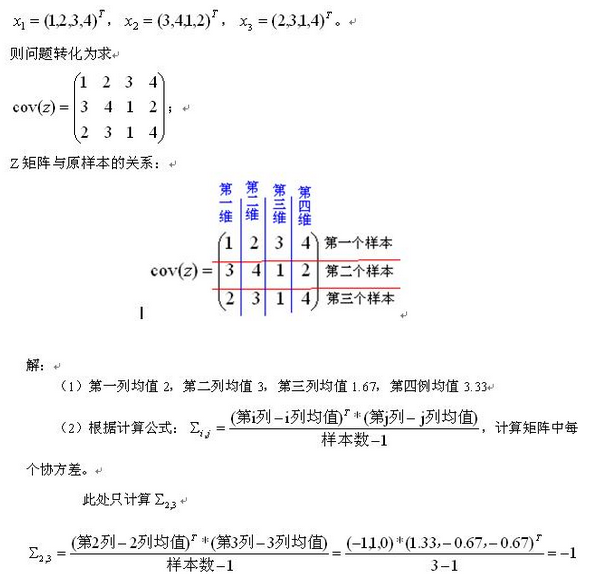
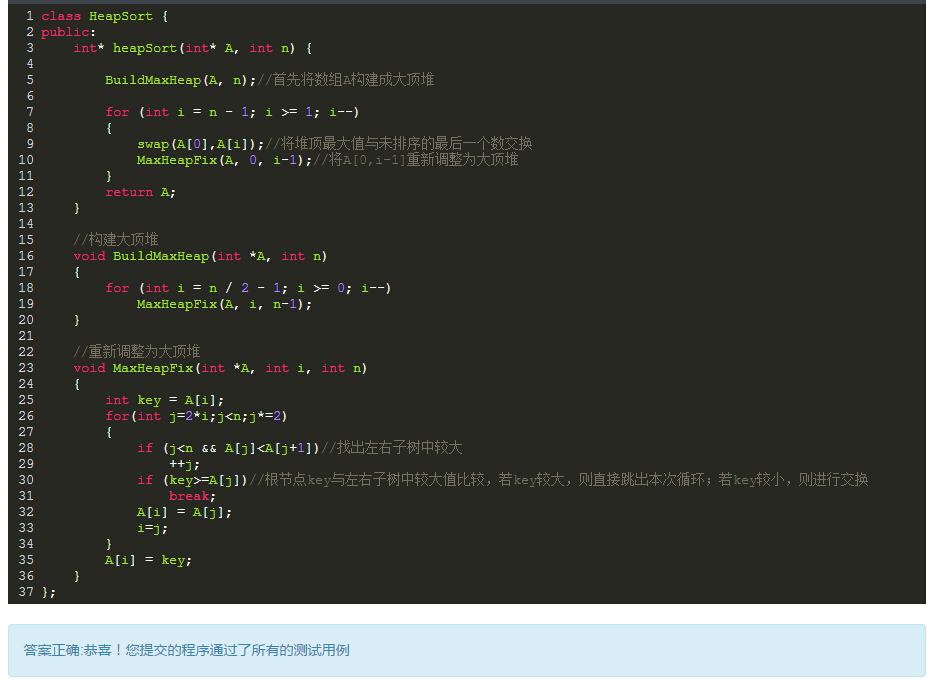
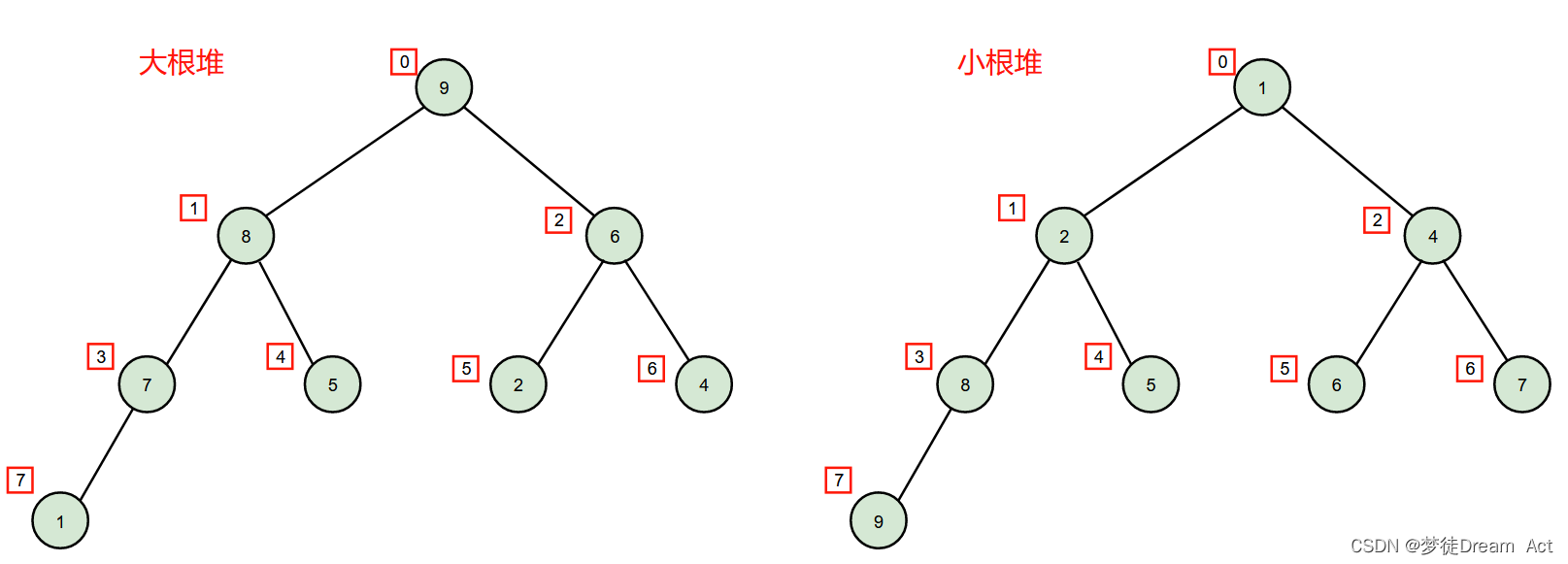
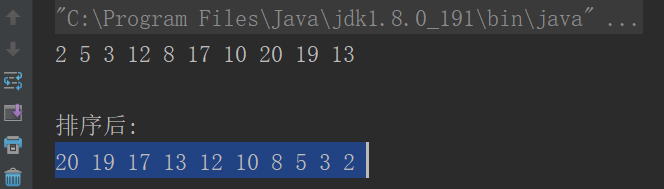
写在前面
浏览更多内容,可访问:http://www.growai.cn
欢迎您关注作者知乎:ML与DL成长之路
推荐关注公众号:AI成长社,ML与DL的成长圣地。
函数
numpy.convolve(a, v, mode=‘full’),这是numpy函数中的卷积函数库
参数:
a:(N,)输入的一维数组
b:(M,)输入的第二个一维数组
mode:{‘full’, ‘valid’, ‘same’}参数可选
‘full’ 默认值,返回每一个卷积值,长度是N+M-1,在卷积的边缘处,信号不重叠,存在边际效应。
‘same’ 返回的数组长度为max(M, N),边际效应依旧存在。
‘valid’ 返回的数组长度为max(M,N)-min(M,N)+1,此时返回的是完全重叠的点。边缘的点无效。
直观理解
数字输入的是离散信号,如下图。
已知x[0] = a,x[1]=b,x[2]=c
已知y[0]=i,y[1]=j,y[2]=k
下面演示x[n]*y[n]过程
第一步,x[n]乘以y[0]并平移到位置0:
第二步,x[n]乘以y[1]并平移到位置1:
第三步,x[n]乘以y[2]并平移到位置2:
最后,把上面三个图叠加,就得到了x[n] * y[n]:
公式及代码
- 公式:[外链图片转存失败(img-LcEepnoS-1567095783853)(https://docs.scipy.org/doc/numpy/_images/math/a15e07437f8ff0a95c28abb0111c56cbc221df53.png)]
- 代码:
由上面的公式可以直接得到下面的数组
>>> np.convolve([1, 2, 3], [0, 1, 0.5])
array([ 0. , 1. , 2.5, 4. , 1.5])
数组中的5个点分别最后一张图片中的五个值
>>> np.convolve([1,2,3],[0,1,0.5], 'same')
array([ 1. , 2.5, 4. ])
三个值分别对应图片中的(1、2、3)三个下标的值
>>> np.convolve([1,2,3],[0,1,0.5], 'valid')
array([ 2.5])
对应图片坐标为2的值
参考:numpy.convolve¶
知乎