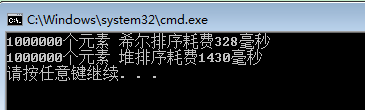
目前计算机语言多种多样,如C++、Java、Basic、Pascal等,此外还有JavaScript、VBScript、ActionScript等脚本语言,它们各自维护自己的数据类型,当使用C++这样强类型的语言来读取数据库或者与其他语言之间来交换数据时,它很有可能不知道获取到的数据的具体类型,这个时候必须借助于变体类型读取数据。VARIANT数据类型就具有跨语言的特性,同时它可以表示(存储)任意类型的数据。其在Visual C++中的定义:
typedef tagVARIANT VARIANT;
typedef struct tagVARIANT VARIANTARG;
VARIANT 其实是一个结构,结构中用一个vt成员表示数据的类型,同时真正的数据则存储在union空间中。一般我们使用VARIANT的步骤如下所示。
定义一个VARIANT变量,如:var。
通过vt成员设定VARIANT变量的数据类型,如:var.vt = VT_I4。
通过对应的union成员设定数据内容,如:var.lVal = 100。
综上所述,利用VARIANT表示一个整型数据:
VARIANT var;
var.vt = VT_I4; //指明整型数据
var.lVal = 100; //赋值
利用VARIANT表示一个布尔值:
VARIANT var;
var.vt = VT_BOOL; //指明整型数据
var.boolVal = VARIANT_TRUE; //赋值
利用VARIANT保存一个字符串:
VARIANT var;
var.vt = VT_BSTR;
var.bstrVal = SysAllocString(L"hello, world!");
根据以上的代码,读者可能会猜到,VARIANT的定义可能类似于如下:
struct VARIANT
{
VARTYPE vt; //数据类型
union
{
LONG lVal; //VT_I4
VARIANT_BOOL boolVal //VT_BOOL
BSTR bstrVal; //VT_BSTR
}
};
实际上,VARIANT的定义就是这样的!只不过由于它需要支持的类型太多,所以它包含的联合成员会更多。限于篇幅,在此不再附出。
VARIANT支持的类型,也就是vt成员的取值如表4-3所示。
表4-3 VARIANT支持的类型
类型名
含义
VT_EMPTY
指示未指定值
VT_NULL
指示空值(类似于 SQL 中的空值)
VT_I2
指示 short 整数
VT_I4
指示 long 整数
VT_R4
指示 float 值
VT_R8
指示 double 值
VT_CY
指示货币值
VT_DATE
指示 DATE 值
VT_BSTR
指示 BSTR 字符串
VT_DISPATCH
指示 IDispatch 指针
VT_ERROR
指示 SCODE
VT_BOOL
指示一个布尔值
VT_VARIANT
指示 VARIANTfar 指针
VT_UNKNOWN
指示 IUnknown 指针
VT_DECIMAL
指示 decimal 值
VT_I1
指示 char 值
(续表)
类型名
含义
VT_UI1
指示 byte
VT_UI2
指示 unsignedshort
VT_UI4
指示 unsignedlong
VT_I8
指示 64 位整数
VT_UI8
指示 64 位无符号整数
VT_INT
指示整数值
VT_UINT
指示 unsigned 整数值
VT_VOID
指示 C 样式 void
VT_HRESULT
指示 HRESULT
VT_PTR
指示指针类型
VT_SAFEARRAY
指示 SAFEARRAY
VT_CARRAY
指示 C 样式数组
VT_USERDEFINED
指示用户定义的类型
VT_LPSTR
指示一个以 NULL 结尾的字符串
VT_LPWSTR
指示由 nullNothingnullptrnull
引用(在 Visual Basic
中为 Nothing) 终止的宽字符串
VT_RECORD
指示用户定义的类型
VT_FILETIME
指示 FILETIME 值
VT_BLOB
指示以长度为前缀的字节
VT_STREAM
指示随后是流的名称
VT_STORAGE
指示随后是存储的名称
VT_STREAMED_OBJECT
指示流包含对象
VT_STORED_OBJECT
指示存储包含对象
VT_BLOB_OBJECT
指示 Blob 包含对象
VT_CF
指示剪贴板格式
VT_CLSID
指示类 ID
VT_VECTOR
指示简单的已计数数组
VT_ARRAY
指示 SAFEARRAY 指针
VT_BYREF
指示 值为引用
4.2.5 _variant_t、CComVariant与COleVariant、CDBVariant
从上面可以看出VARIANT这种类型使用起来比较复杂,其实有简单的办法,那就是采用VARIANT的封装类_variant_t。_variant_t的构造函数接受基本数据类型的数据作为参数,如下列出其中的一小部分:
- _variant_t(
- short sSrc,
- VARTYPE vtSrc = VT_I2
- );
- _variant_t(
- long lSrc,
- VARTYPE vtSrc = VT_I4
- );
- _variant_t(
- float fltSrc
- ) throw( );
- _variant_t(
- double dblSrc,
- VARTYPE vtSrc = VT_R8
- );
另一方面,_variant_t提供了反向的转换函数,如将一个_variant_t转换成一个short数值,如下列出其中的一小部分:
- operator short( ) const;
- operator long( ) const;
- operator float( ) const;
- operator double( ) const;
因此可以看出,利用_variant_t可以很方便地实现VARIANT类型和基本数据类型之间的转换,如:
- long l = 123;
- _variant_t lVal(l);
- long m = lVal;
也可以用COleVariant和CComVariant来简化对VARIANT的操作,代码参考如下:
- COleVariant v3 = _T("hello, world!");
- COleVariant v4 = (long)1999;
- CString str = (BSTR)v3.pbstrVal;
- long i = v4.lVal;
VARIANT类图如图4-7所示。
 |
| (点击查看大图)图4-7 VARIANT类图 |