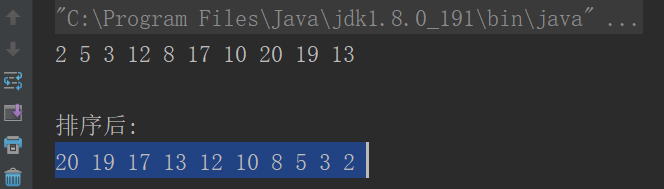
递归在程序语言中就是方法本身自己调用自己,而递归思想是算法的重要思想之一,就是利用递归来实现解决问题的算法。
递归也分为直接递归和间接递归。
那么什么叫直接递归什么又叫间接递归呢?
//直接递归调用
function(){...function();...
}
//间接递归调用
function1(){...function2();...
}
function2(){...function1();...
}直接递归调用其实就是方法自己直接调用自己,而间接递归则是在递归的过程中没有直接的调用自己,是间接的把自己调用了,用以上的列子来讲则是,方法1中包涵了方法2,而方法2里又包涵了方法1,所以方法1也包涵了自己本身,只是通过方法2 间接调用并没有直接递归那么明显。
在使用递归时有一点需要注意:必须要为递归方法设计一个出口,也就是停止的操作,没有出口的递归方法最终将会不断运行陷入死循环。
这里用递归算法来实现阶乘作为列子
import java.util.Scanner;
public class Recusion {int sum = 0;public static void main(String[] args) {System.out.printf("输入 n 的值:");Scanner scanner = new Scanner(System.in);int i = scanner.nextInt();int a;// 注意 由于mul不是静态方法所以要先声明对象Recusion recusion = new Recusion();a = recusion.mul(i);System.out.println(i+"的阶乘的结果为:"+ a);}public int mul(int i) {//出口 当 i等于1和0时跳出递归if (i == 1 || i == 0) {return 1;}else {return i * mul(i - 1);}}
}
递归到底是怎么实现的呢?它的实现原理是什么?
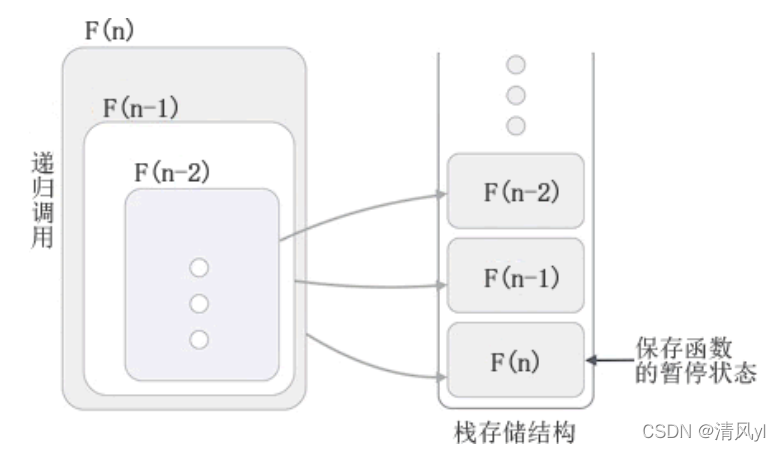
这里给出了一个具体的图解来解释递归方法的实现过程。以求阶乘的递归算法为例,列入输入5,方法执行到 n * (n-1) 后,也就是5 * 4之后暂停,再去执行以4为n的方法 实现为4 * 3 ,一直到3 * 2, 2 * 1,等到为1停止递归时将所有停止的数据恢复重新执行 也就是 : 5 * 4 *3 * 2 * 1,最终获得递归后的结果。
除了阶乘,用到递归算法的问题还有问题,与此同时许多算法也需要借助递归来实现:回溯算法和分治算法等等。
这里再给出斐波那契数列的解法:
import java.util.Scanner;
public class Fibonacci {public static void main(String[] args) {System.out.printf("输入 n 的值:");Scanner scanner = new Scanner(System.in);int n = scanner.nextInt();int a = fib(n);System.out.println("斐波那契数列中第"+n+"个的值是:" + a );}//斐波那契数列的等差公式:an = an-1 + an-2public static int fib(int n) {//添加结束条件if (n == 1 || n == 2) {return 1;}//递归return fib(n - 1) + fib(n - 2);}
}对于斐波那契数列需要了解的就是它本身的规律:数列中每一个的值都等于它前两个值的和,借助这个规律再化用递归算法就能将原本复杂的问题简单化。