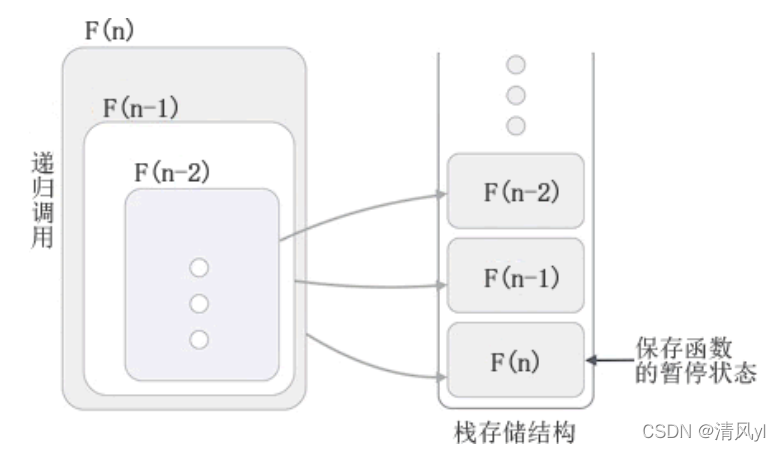
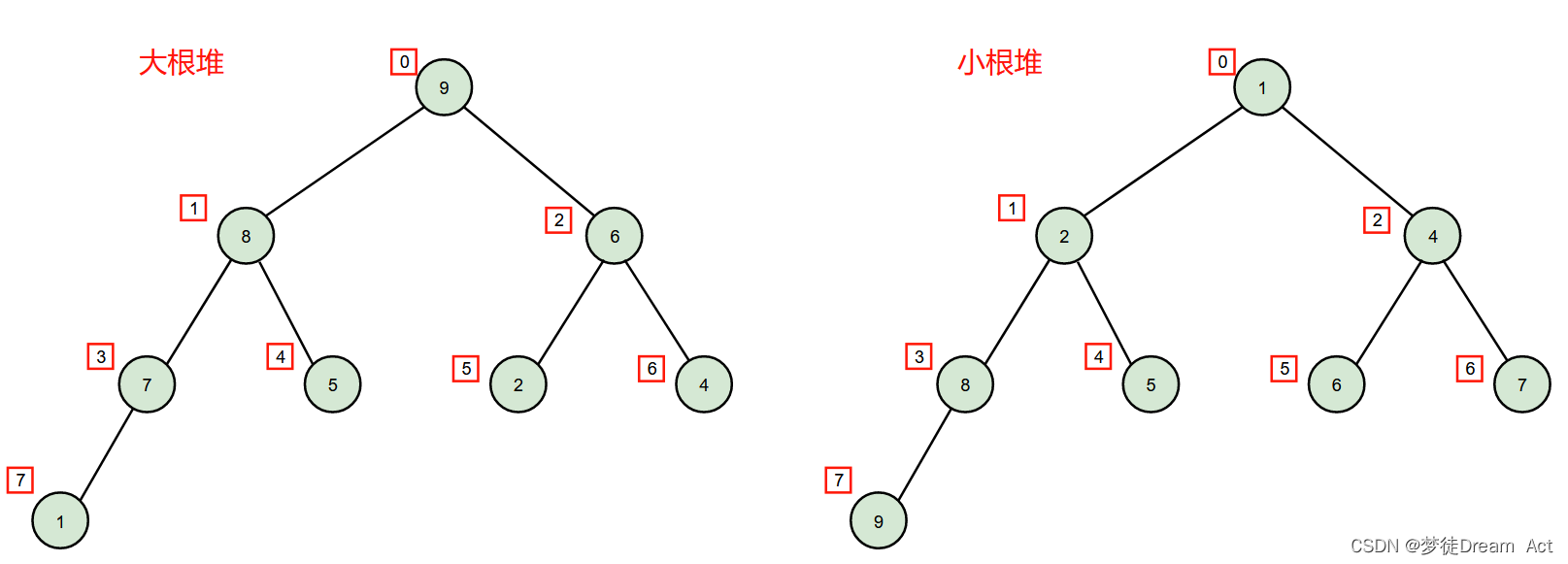
递归算法设计的基本思想是:对于一个复杂的问题,把原问题分解为若干个相对简单类同的子问题,继续下去直到子问题简单到能够直接求解,也就是说到了递推的出口,这样原问题就有递推得解。
关键要抓住的是:
(1)递归出口
(2)地推逐步向出口逼近
例子:
example: 求5的阶乘。。
如下:
上面的multiply是一个阶乘的例子。其实递归递归,从字面上解释就是在方法本身调用自己的方法,或者间接调用;看上面的程序,拿multiply(5)来说:
n=5;执行 5*multiply(4);
--------------------
这时候看multiply(4)
n=4 执行 4*multiply(3);
-------------------
看multiply(3)
n=3,执行 3*multiply(2);
---------------
mulitply(2);
n=2 执行 2*mulitply(1);
这时候,return 1;往上返回
2*1向上返回
3*(2*1)向上返回
4*(3*(2*1)) 向上返回
5*(4*(3*(2*1)) ) = 120
所以程序输出120;
这事简单的递归的例子;所以可以看出来递归的关键得有递归出口(本体的If语句),还有递归方法;
以下是我在百度知道碰到一个朋友的提问,也是关于递归算法的:
------------------------问题------------------------------
本人刚学JAVA,没有任何编程基础,各位高手见笑。
--------------------回答---------------------------
先执行count(1),然后进入count方法,N值为1,所以执行IF语句,也就是执行count(2),然后进入count方法,N值为2,所以执行IF语句,也就是执行count(3),然后进入count方法,N值为3,所以执行IF语句,也就是执行count(4),然后进入count方法,N值为4,所以执行IF语句,也就是执行count(5),然后进入count方法,N值为5,所以不执行IF语句,然后执行System.out.print(" "+n); 也就是输出5,然后本次参数为5的count方法调用结束了,返回到调用它的参数为4的count方法中,然后执行System.out.print(" "+n);输出4,然后一直这样下去,输出3,2,1 。这里需要说明的是在执行count(5)的时候,count(4)、count(3)、count(2)、count(1)都没有执行完毕,他们都在等自己方法体中的count(n+1)执行完毕,然后再执行System.out.print(" "+n);
关键要抓住的是:
(1)递归出口
(2)地推逐步向出口逼近
例子:
example: 求5的阶乘。。
如下:
Java代码 
- public class Test {
- static int multiply(int n){
- if(n==1||n==0)
- return n;
- else
- return n*multiply(n-1);
- }
- public static void main(String[] args){
- System.out.println(multiply(10));
- }
- }
public class Test {
static int multiply(int n){
if(n==1||n==0)
return n;
else
return n*multiply(n-1);
}
public static void main(String[] args){
System.out.println(multiply(10));
}
} 上面的multiply是一个阶乘的例子。其实递归递归,从字面上解释就是在方法本身调用自己的方法,或者间接调用;看上面的程序,拿multiply(5)来说:
n=5;执行 5*multiply(4);
--------------------
这时候看multiply(4)
n=4 执行 4*multiply(3);
-------------------
看multiply(3)
n=3,执行 3*multiply(2);
---------------
mulitply(2);
n=2 执行 2*mulitply(1);
这时候,return 1;往上返回
2*1向上返回
3*(2*1)向上返回
4*(3*(2*1)) 向上返回
5*(4*(3*(2*1)) ) = 120
所以程序输出120;
这事简单的递归的例子;所以可以看出来递归的关键得有递归出口(本体的If语句),还有递归方法;
以下是我在百度知道碰到一个朋友的提问,也是关于递归算法的:
------------------------问题------------------------------
本人刚学JAVA,没有任何编程基础,各位高手见笑。
Java代码
- public class Count
- {
- static void count(int n) //递归方法
- {
- if (n<5)
- count(n+1);
- System.out.print(" "+n);
- }
- public static void main(String args[])
- {
- count(1);
- System.out.println();
- }
- }
public class Count
{
static void count(int n) //递归方法
{
if (n<5)
count(n+1);
System.out.print(" "+n);
}
public static void main(String args[])
{
count(1);
System.out.println();
}
}--------------------回答---------------------------
先执行count(1),然后进入count方法,N值为1,所以执行IF语句,也就是执行count(2),然后进入count方法,N值为2,所以执行IF语句,也就是执行count(3),然后进入count方法,N值为3,所以执行IF语句,也就是执行count(4),然后进入count方法,N值为4,所以执行IF语句,也就是执行count(5),然后进入count方法,N值为5,所以不执行IF语句,然后执行System.out.print(" "+n); 也就是输出5,然后本次参数为5的count方法调用结束了,返回到调用它的参数为4的count方法中,然后执行System.out.print(" "+n);输出4,然后一直这样下去,输出3,2,1 。这里需要说明的是在执行count(5)的时候,count(4)、count(3)、count(2)、count(1)都没有执行完毕,他们都在等自己方法体中的count(n+1)执行完毕,然后再执行System.out.print(" "+n);