一、impala 概述
1、什么是Impala?
- Impala是用于处理存储在Hadoop集群中的大量数据的MPP(大规模并行处理)SQL查询引擎。 它是一个用C ++和Java编写的开源软件。 与其他Hadoop的SQL引擎相比,它提供了高性能和低延迟。
2、为什么选择Impala?
- 使用Impala,与其他SQL引擎(如Hive)相比,用户可以使用SQL查询以更快的方式与HDFS或HBase进行通信。
- Impala可以读取Hadoop使用的几乎所有文件格式,如Parquet,Avro,RCFile。
- Impala将相同的元数据,SQL语法(Hive SQL),ODBC驱动程序和用户界面(Hue Beeswax)用作Apache Hive,为面向批量或实时查询提供熟悉且统一的平台。
- 与Apache Hive不同,Impala不基于MapReduce算法。 它实现了一个基于守护进程的分布式架构,它负责在同一台机器上运行的查询执行的所有方面。
3、Impala的优点
- 使用impala,您可以使用传统的SQL知识以极快的速度处理存储在HDFS中的数据。
- 由于在数据驻留(在Hadoop集群上)时执行数据处理,因此在使用Impala时,不需要对存储在Hadoop上的数据进行数据转换和数据移动。
- 使用Impala,您可以访问存储在HDFS,HBase和Amazon s3中的数据,而无需了解Java(MapReduce作业)。
- 为了在业务工具中写入查询,数据必须经历复杂的提取 - 变换负载(ETL)周期。但是,使用Impala,此过程缩短了。加载和重组的耗时阶段通过新技术克服,如探索性数据分析和数据发现,使过程更快。
- Impala正在率先使用Parquet文件格式,这是一种针对数据仓库场景中典型的大规模查询进行优化的柱状存储布局。
4、Impala的功能
- Impala支持内存中数据处理,即,它访问/分析存储在Hadoop数据节点上的数据,而无需数据移动。
- 与其他SQL引擎相比,Impala为HDFS中的数据提供了更快的访问。
- 使用Impala,您可以将数据存储在存储系统中,如HDFS,Apache HBase和Amazon s3。
- Impala支持各种文件格式,如LZO,序列文件,Avro,RCFile和Parquet。
5、关系数据库和Impala
| Impala | 关系型数据库 |
| Impala使用类似于HiveQL的类似SQL的查询语言 | 关系数据库使用SQL语言 |
| 在Impala中,您无法更新或删除单个记录 | 在关系数据库中,可以更新或删除单个记录 |
| Impala不支持事务 | 关系数据库支持事务 |
| Impala不支持索引 | 关系数据库支持索引 |
| Impala存储和管理大量数据(PB) | 与Impala相比,关系数据库处理的数据量较少(TB) |
6、Hive,Hbase和Impala
| HBase | Hive | Impala |
| HBase是基于Apache Hadoop的宽列存储数据库。 它使用BigTable的概念。 | Hive是一个数据仓库软件。 使用它,我们可以访问和管理基于Hadoop的大型分布式数据集。 | Impala是一个管理,分析存储在Hadoop上的数据的工具。 |
| HBase的数据模型是宽列存储。 | Hive遵循关系模型。 | Impala遵循关系模型。 |
| HBase是使用Java语言开发的。 | Hive是使用Java语言开发的。 | Impala是使用C ++开发的。 |
| HBase的数据模型是无模式的。 | Hive的数据模型是基于模式的。 | Impala的数据模型是基于模式的。 |
| HBase提供Java,RESTful和Thrift API。 | Hive提供JDBC,ODBC,Thrift API。 | Impala提供JDBC和ODBC API。 |
| 支持C,C#,C ++,Groovy,Java PHP,Python和Scala等编程语言。 | 支持C ++,Java,PHP和Python等编程语言。 | Impala支持所有支持JDBC / ODBC的语言。 |
| HBase提供对触发器的支持。 | Hive不提供任何触发器支持。 | Impala不提供对触发器的任何支持。 |
7、Impala的缺点
- Impala不提供任何对序列化和反序列化的支持。
- Impala只能读取文本文件,而不能读取自定义二进制文件。
- 每当新的记录/文件被添加到HDFS中的数据目录时,该表需要被刷新。
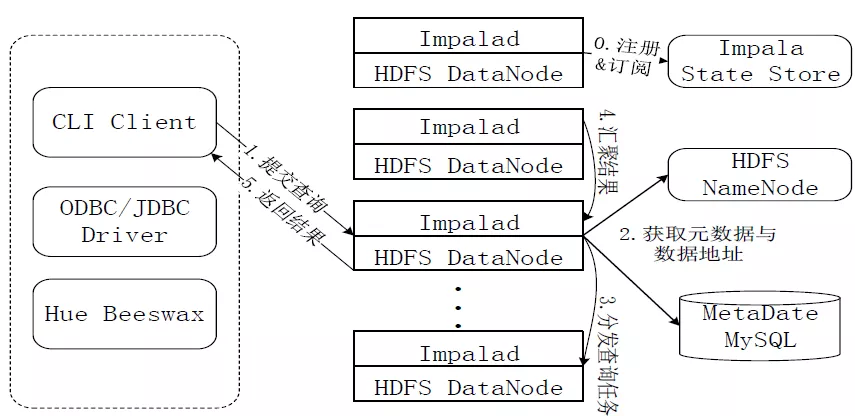
二、impala架构


- StateStore是Impala的一个子服务,用来监控集群中各个节点的健康状况,提供节点注册、错误检测等功能。
- Impala在每个节点运行了一个后台服务Impalad,Impalad用来响应外部请求,并完成实际的查询处理。
- Impalad主要包含Query Planner、Query Coordinator和Query Exec Engine三个模块。
- QueryPalnner接收来自SQL APP和ODBC的查询,然后将查询转换为许多子查询,Query Coordinator将这些子查询分发到各个节点上,由各个节点上的Query Exec Engine负责子查询的执行,最后返回子查询的结果,这些中间结果经过聚集之后最终返回给用户。
- Impala主要由Impalad, State Store和CLI组成。