1、集群准备
1.1、安装Hadoop,Hive
- Impala的安装需要提前装好Hadoop,Hive这两个框架
- hive需要在所有的Impala安装的节点上面都要有,因为Impala需要引用Hive的依赖包
- hadoop的框架需要支持C程序访问接口,查看下图,如果有该路径有.so结尾文件,就证明支持C接口。
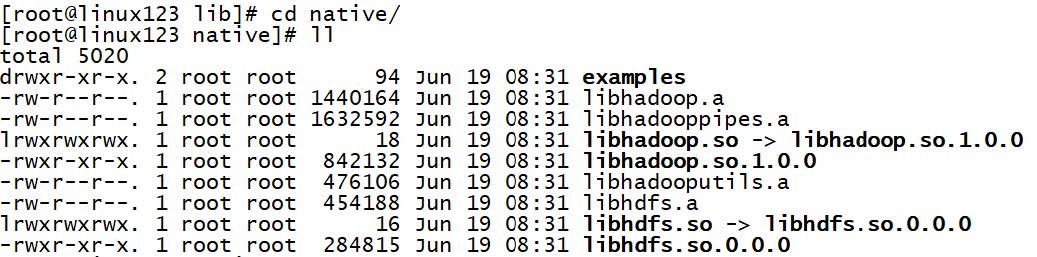
HDFS:impala数据存储在hdfs
Hive:impala直接使用Hive元数据管理数据
1.2、准备Impala的所有依赖包
Cloudera公司对于Impala的安装只提供了rpm包没有提供tar包;所以我们选择使用Cloudera的rpm包进行Impala的安装,但是另外一个问题,Impala的rpm包依赖非常多的其他的rpm包,我们可以一个个的将依赖找出来,但是这种方式实在是浪费时间。
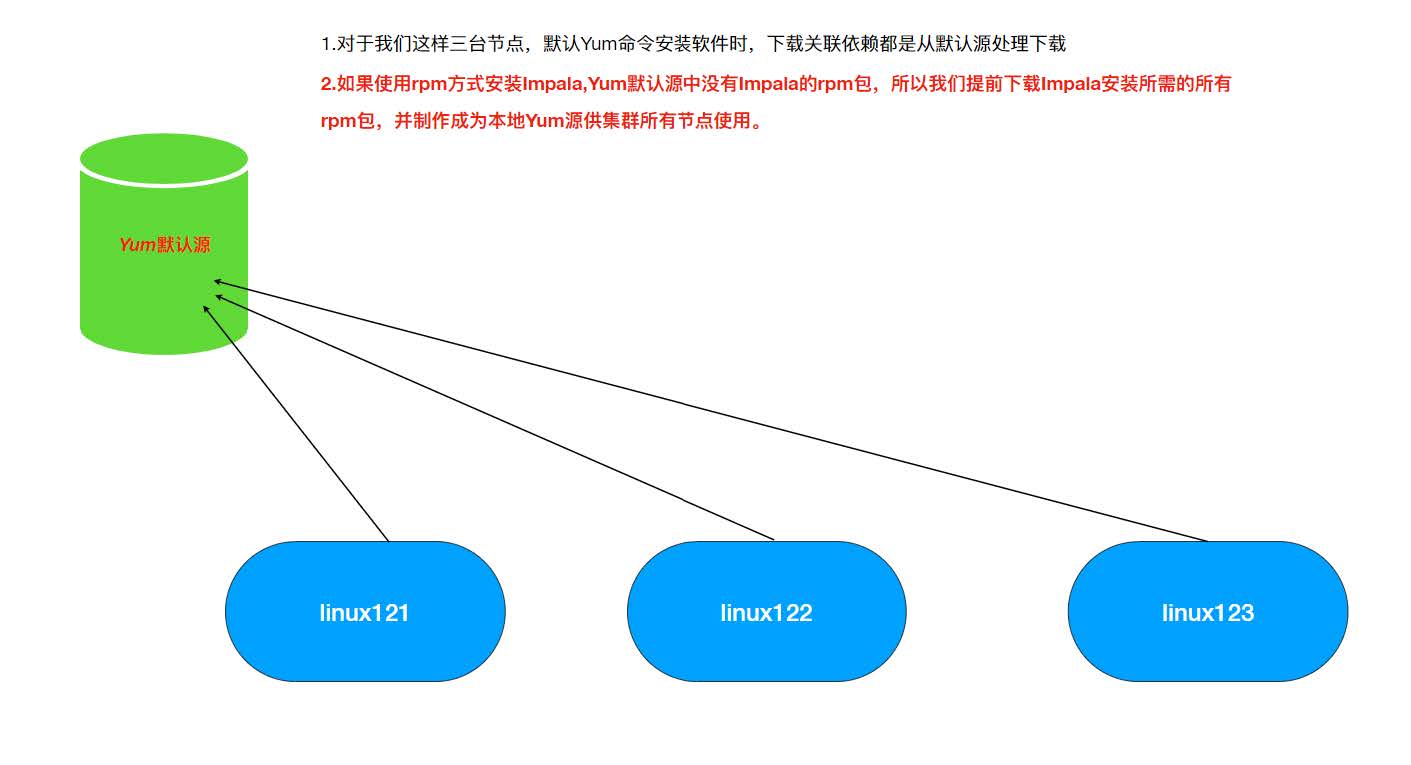
Linux系统中对于rpm包的依赖管理提供了一个非常好的管理工具叫做Yum,类似于Java工程中的包管理工具Maven,Maven可以自动搜寻指定Jar所需的其它依赖并自动下载来。Yum同理可以非常方便的让我们进行rpm包的安装无需关系当前rpm所需的依赖。但是与Maven下载其它依赖需要到中央仓库一样 Yum下载依赖所需的源也是在放置在国外服务器并且其中没有安装Impala所需要的rpm包,所以默认的这种Yum源可能下载依赖失败。所以我们可以自己指定Yum去哪里下载所需依赖。
rpm方式安装:需要自己管理rpm包的依赖关系;非常麻烦;解决依赖关系使用yum;默认Yum源是没有 Impala的rpm安装包,所以我们自己准备好所有的Impala安装所需的rpm包,制作Yum本地源,配置 Yum命令去到我们准备的Yun源中下载Impala的rpm包进行安装。
Yum命令默认源
本地Yum源方式
具体制作步骤
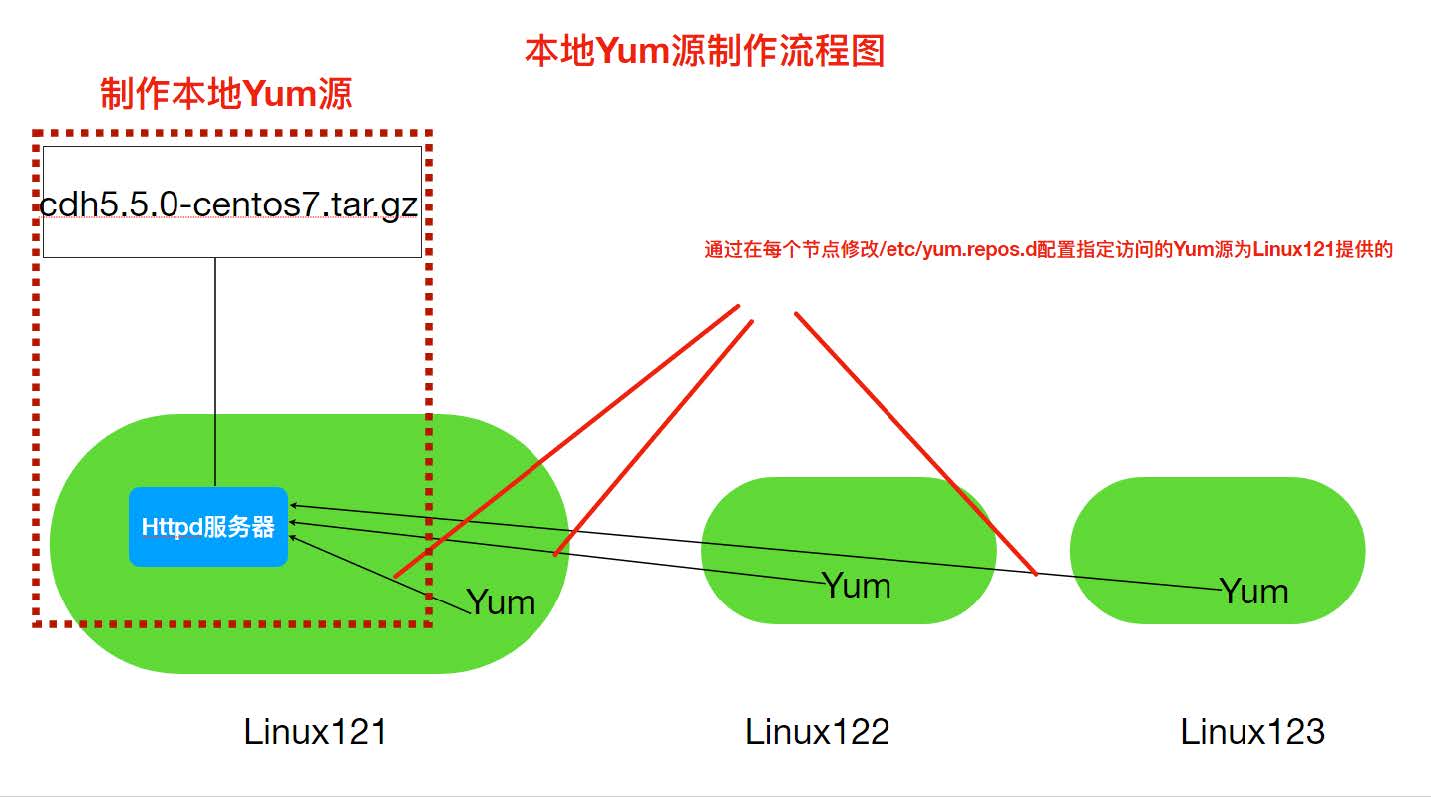
Yum源是Centos当中下载软件rpm包的地址,因此通过制作本地Yum源并指定Yum命令使用本地Yum 源,为了使Yum命令(本机,跨网络节点)可以通过网络访问到本地源,我们使用Httpd这种静态资源服务器来开放我们下载所有的rpm包。
(1)Linux121安装Httpd服务器
#yum方式安装httpd服务器
yum install httpd -y
#启动httpd服务器
systemctl start httpd
#验证httpd工作是否正常,默认端口是80,可以省略
http://linux121
(2) 新建一个测试页面
httpd默认存放页面路径
/var/www/html/
新建一个页面test.html
<html><div style="font-size:100px">this is a new page!!</div>
</html>访问
http://linux121/test.html
注:后续可以把下载的rpm包解压放置到此处便可以供yum访问
(3)下载Impala安装所需rpm包
Impala所需安装包需要到Cloudera提供地址下载
http://archive.cloudera.com/cdh5/repo-as-tarball/5.7.6/cdh5.7.6- centos7.tar.gz
注意:该tar.gz包是包含了Cloudera所提供的几乎所有rpm包,但是为了方便我们不再去梳理其中 依赖关系,全部下载来,整个文件件比较大,有3.8G。选择一个磁盘空间够的节点,后续还要把压缩包解压所以磁盘空间要剩余10G以上。
相关资料:链接:https://pan.baidu.com/s/1Uz2hr61Zodhs9TH79W7-uA?pwd=af0k
移动该安装包到/opt/lagou/software
# 解压缩
tar -zxvf cdh5.7.6-centos7.tar.gz
(4)使用Httpd盛放依赖包
# 创建软链接到/var/www/html下
ln -s /opt/lagou/software/cdh/5.7.6 /var/www/html/cdh57
# 验证
http://linux121/cdh57/
如果提示403 forbidden
vim /etc/selinux/config
将SELINUX=enforcing改为SELINUX=disabled

修改之后要记得重启机器!!之前修改过可以不用修改!!
(5)修改Yum源配置文件
cd /etc/yum.repos.d
#创建一个新的配置⽂件
vim local.repo
#添加如下内容
[local]
name=local
baseurl=http://linux121/cdh57/
gpgcheck=0
enabled=1- name:对于当前源的描述
- baseurl:访问当前源的地址信息
- gpgcheck: 1 0,gpg校验
- enabled:1/0,是否使用当前源
(6)分发local.repo文件到其它节点(三台机器都要修改)
2、安装Impala
2.1、集群规划
| 服务名称 | linux121 | linux122 | linux123 |
| impala-catalogd | 不安装 | 不安装 | 安装 |
| impala-statestored | 不安装 | 不安装 | 安装 |
| impala-server | 安装 | 安装 | 安装 |
Impala角色
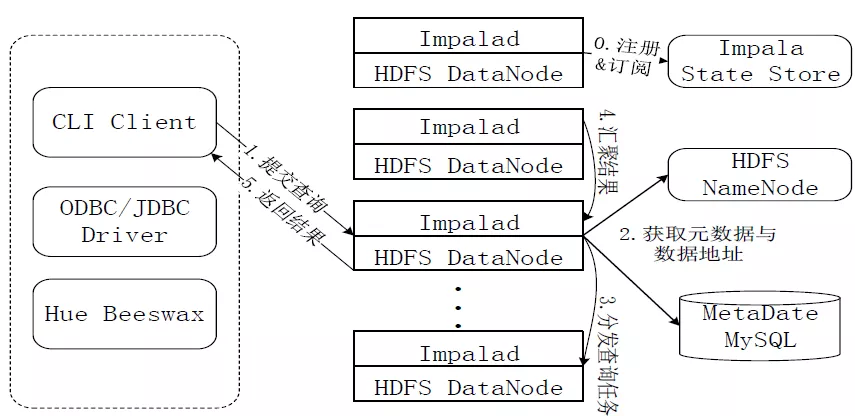
- impala-server:这个进程是Impala真正工作的进程,官方建议把impala-server安装在datanode节点, 更靠近数据(短路读取),进程名impalad
- impala-statestored:健康监控角色,主要监控impala-server,impala-server出现异常时告知给其它 impala-server;进程名叫做statestored
- impala-catalogd :管理和维护元数据(Hive),impala更新操作;把impala-server更新的元数据通知给其它impala-server,进程名catalogd
官方建议statestore与catalog安装在同一节点上!!
2.2、具体安装步骤
Linux123
yum install impala -y
yum install impala-server -y
yum install impala-state-store -y
yum install impala-catalog -y
yum install impala-shell -y
Linux121与Linux122
yum install impala-server -y
yum install impala-shell -y
配置Impala
(1)修改hive-site.xml
vim hive-site.xml
<!--指定metastore地址,之前添加过可以不用添加 -->
<property><name>hive.metastore.uris</name><value>thrift://linux121:9083,thrift://linux123:9083</value>
</property>
<property><name>hive.metastore.client.socket.timeout</name><value>3600</value>
</property>(2)分发Hive安装包到集群节点
rsync -r /opt/lagou/servers/hive-2.3.7/ linux122:/opt/lagou/servers/
rsync -r /opt/lagou/servers/hive-2.3.7/ linux121:/opt/lagou/servers/
(3)Linux123启动metastore服务
nohup hive --service metastore &
(4)启动hiveserver2服务
nohup hive --service hiveserver2 &
(5)修改HDFS集群hdfs-site.xml
配置HDFS集群的短路读取
什么是短路读取?
在HDFS中通过DataNode来读取数据。但是,当客户端向DataNode请求读取文件时,DataNode 就会从磁盘读取该文件并通过TCP socket将数据发送到客户端。所谓“短路”是指Client客户端直接读取文件。很明显,这种情况只在客户端与数据放在同一地点(译者注:同一主机)时才有可能发生。短路读对于许多应用程序会带来重大的性能提升。
短路读取:就是Client与DataNode属于同⼀节点,⽆需再经过⽹络传输数据,直接本地读取。
要配置短路本地读,需要验证本机Hadoop是否有libhadoop.so;
# 进入下目录:
/opt/lagou/servers/hadoop-2.9.2/lib/native

短路读取配置步骤
(1)创建短路读取本地中转站
# 所有节点创建一下目录
mkdir -p /var/lib/hadoop-hdfs
(2)修改hdfs-site.xml
<!--添加如下内容 -->
<!--打开短路读取开关 -->
<!-- 打开短路读取配置-->
<property><name>dfs.client.read.shortcircuit</name><value>true</value>
</property>
<!--这是⼀个UNIX域套接字的路径,将⽤于DataNode和本地HDFS客户机之间的通信 -->
<property><name>dfs.domain.socket.path</name><value>/var/lib/hadoop-hdfs/dn_socket</value>
</property>
<!--block存储元数据信息开发开关 -->
<property><name>dfs.datanode.hdfs-blocks-metadata.enabled</name><value>true</value>
</property>
<property><name>dfs.client.file-block-storage-locations.timeout</name><value>30000</value>
</property>注:分发到集群其它节点。重启Hadoop集群。
#停止集群
stop-dfs.sh
start-dfs.sh
#启动集群
start-dfs.sh
start-yarn.sh
(5)Impala具体配置
引用HDFS,Hive配置
使用Yum方式安装impala默认的Impala配置文件目录为 /etc/impala/conf,Impala的使用要依赖 Hadoop,Hive框架,所以需要把Hdfs,Hive的配置文件告知Impala。
执行以下命令把Hdfs,Hive的配置文件软链接到/etc/impala/conf下
ln -s /opt/lagou/servers/hadoop-2.9.2/etc/hadoop/core-site.xml /etc/impala/conf/core-site.xmlln -s /opt/lagou/servers/hadoop-2.9.2/etc/hadoop/hdfs-site.xml /etc/impala/conf/hdfs-site.xmlln -s /opt/lagou/servers/hive-2.3.7/conf/hive-site.xml /etc/impala/conf/hive-site.xml注:所有节点都要执行此命令!
Impala自身配置
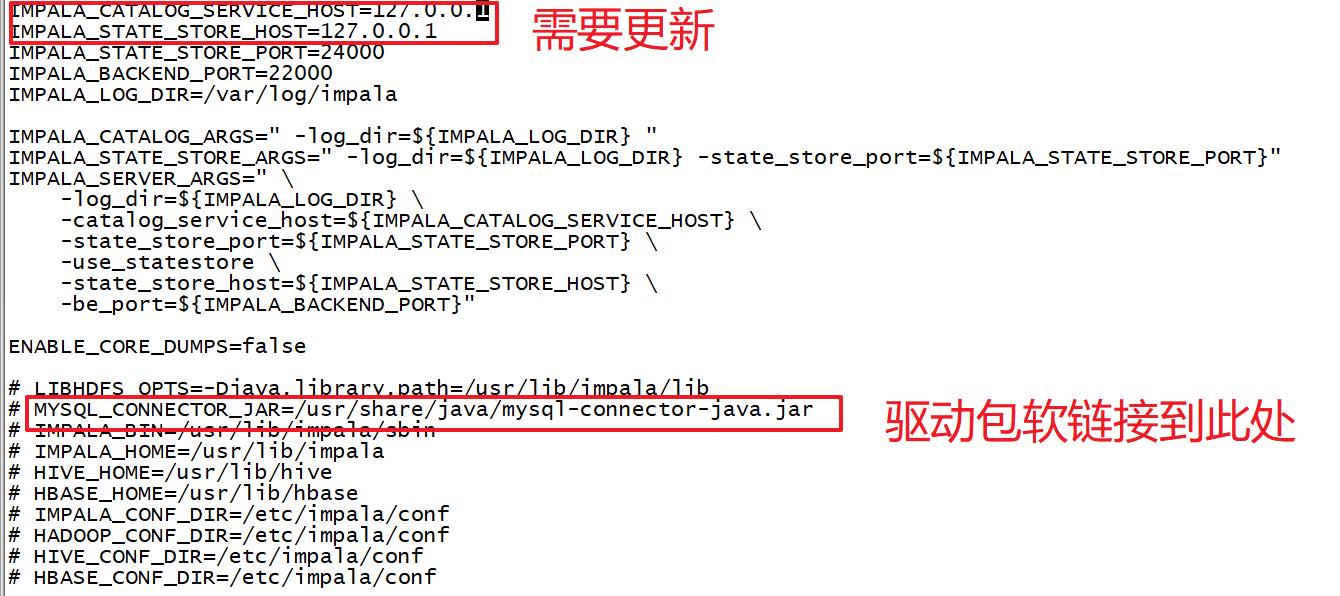
所有节点更改Impala默认配置⽂件以及添加mysql的驱动包
vim /etc/default/impala
<!--更新如下内容 --> IMPALA_CATALOG_SERVICE_HOST=linux123 IMPALA_STATE_STORE_HOST=linux123
所有节点创建mysql的驱动包的软链接
#创建节点
mkdir -p /usr/share/java
ln -s /opt/lagou/servers/hive-2.3.7/lib/mysql-connector-java-5.1.46.jar /usr/share/java/mysql-connector-java.jar
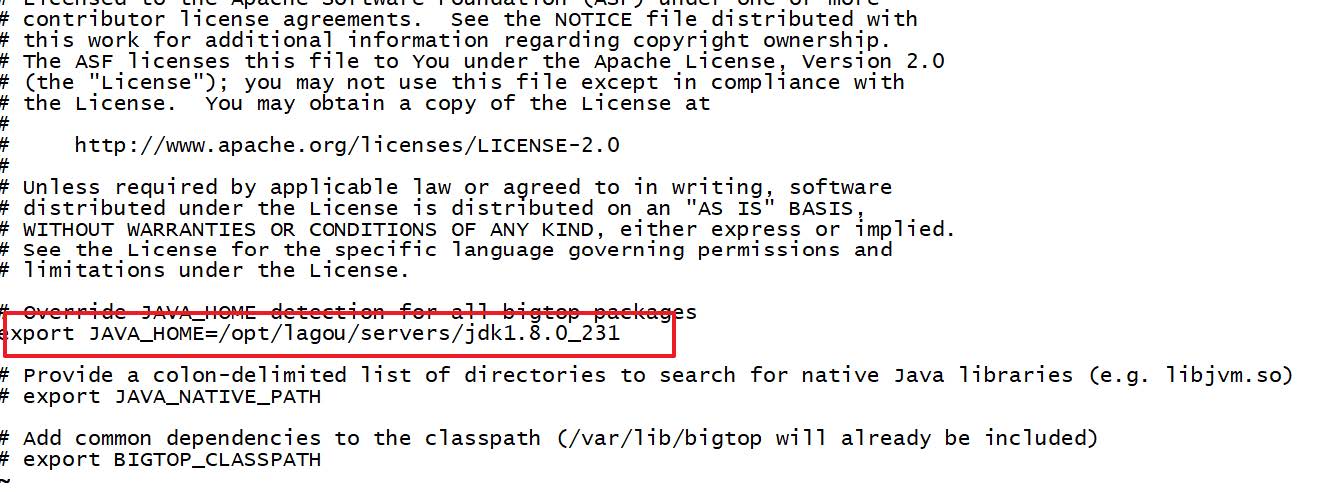
修改bigtop的java_home路径
vim /etc/default/bigtop-utils
# 添加下面内容
export JAVA_HOME=/opt/lagou/servers/jdk1.8.0_231
注意:Apache Bigtop 是一个针对基础设施工程师和数据科学家的开源项目,旨在全面打包、测试 和配置领先的开源大数据组件/项目。Impala项目中使用到了此软件。
启动Impala
# linux123启动如下角色
service impala-state-store start
service impala-catalog start
service impala-server start
# 其余节点启动如下角色
service impala-server start
验证Impala启动结果
ps -ef | grep impala
浏览器Web界面验证
访问impalad的管理界面
http://linux123:25000/
访问statestored的管理界面
http://linux123:25010/
Impalad管理界面
Statestore管理界面
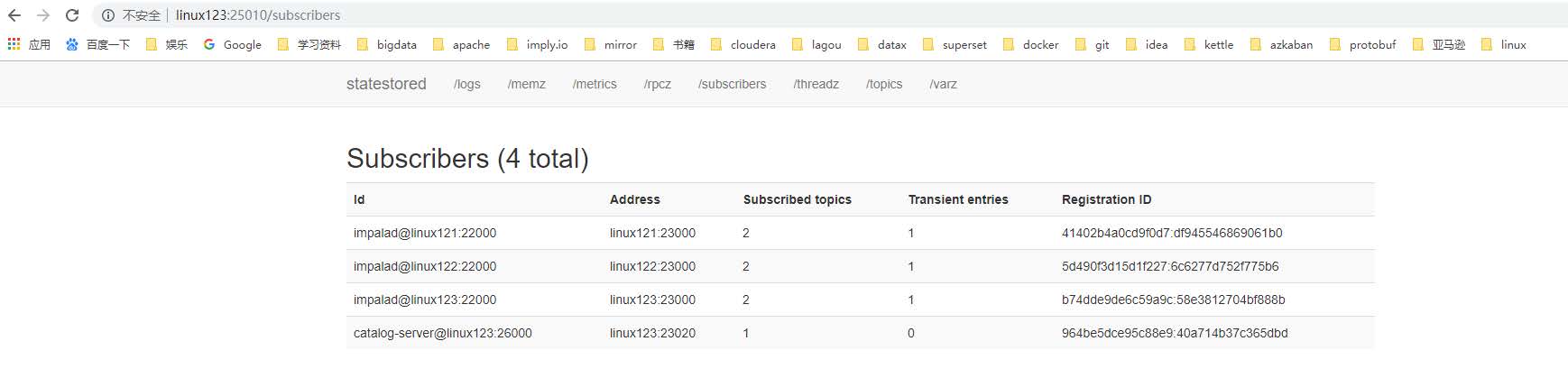
注意:启动之后所有关于Impala的日志默认都在/var/log/impala 这个路径下,Linux123机器上面应该有三个进程,Linux121与Linux122机器上面只有一个进程,如果进程个数不对,去对应目录下查看报错日志。
消除Impala影响
由于使用Yum命令安装Impala,我们选择使用yum自动进行Impala依赖的安装和处理,所以本次安装默认会把Impala依赖的所有框架都会安装,比如Hadoop,Hive,Mysql等,为了保证我们自己安装的Hadoop等使用正常我们需要删除掉Impala默认安装的其它框架。
[root@linux122 conf]# which hadoop
/usr/bin/hadoop
[root@linux122 conf]# which hive
/usr/bin/hive
#使⽤which命令 查找hadoop,hive等会发现,命令⽂件是/usr/bin/hadoop ⽽⾮我们⾃⼰安装的路径,需要把这些删除掉,所有节点都要执⾏
rm -rf /usr/bin/hadoop
rm -rf /usr/bin/hdfs
rm -rf /usr/bin/hive
rm -rf /usr/bin/beeline
rm -rf /usr/bin/hiveserver2#重新⽣效环境变量
source /etc/profilejps 时出现没有名字的进程或者process information unavailable
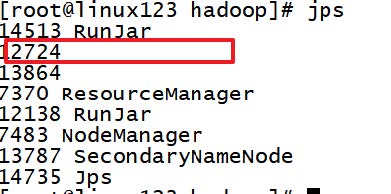
解决方式
rm -rf /tmp/hsperfdata_*