目录
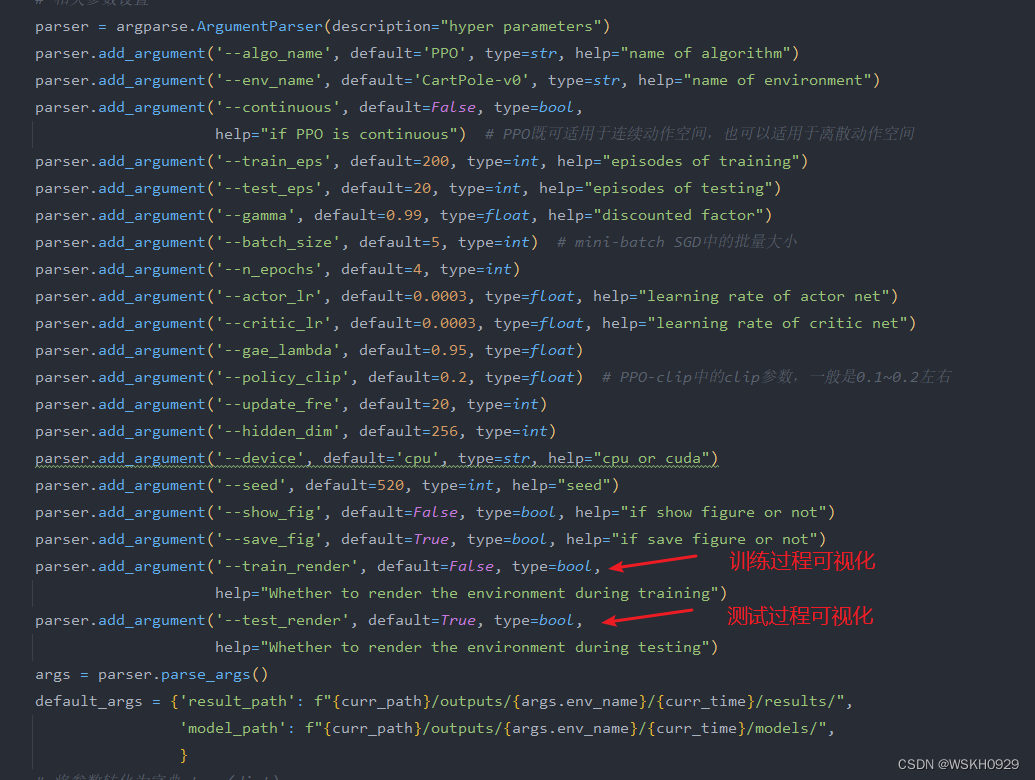
一、impala shell内部命令
1.进入impala交互命令行
2.内部命令(同sql操作类似)
3.退出impala
4.连接到指定的机器impalad上去执行
5.增量刷新
6.全量刷新
7.帮助
8.查看sql语句的执行计划
9.打印出更加详细的执行步骤
10.设置显示级别(0,1,2,3)
二、impala外部命令
1.查看帮助手册
2.刷新impala元数据
3.执行指定路径的sql文件
4.直接执行查询语句
5.指定连接运行 impalad 守护进程的主机
6.保存执行结果到文件
7.对查询结果去格式化
8.去格式化后指定分隔符
9.显示查询的执行计划(与EXPLAIN语句输出相同)和每个查询语句底层的执行步骤的详细信息
10.指定当shell连接到impalad节点时使用kerberos身份验证.但是如果impalad节点本身没有启用kerberos,连接将会报错.
11.该选项后面跟kerberos服务名称让impala-shell验证一个特定的impalad服务.如果没有指定kerberos服务名称,将使用impala作为默认的名称.如果该选项用于一个不支持kerberos的连接,将会返回错误
12.启用详细信息输出
13.禁用详细信息输出
14.查询版本信息
15.查询执行失败时继续执行
16.启用LDAP认证
17.启用LDAP时,指定用户名
一、impala shell内部命令
1.进入impala交互命令行
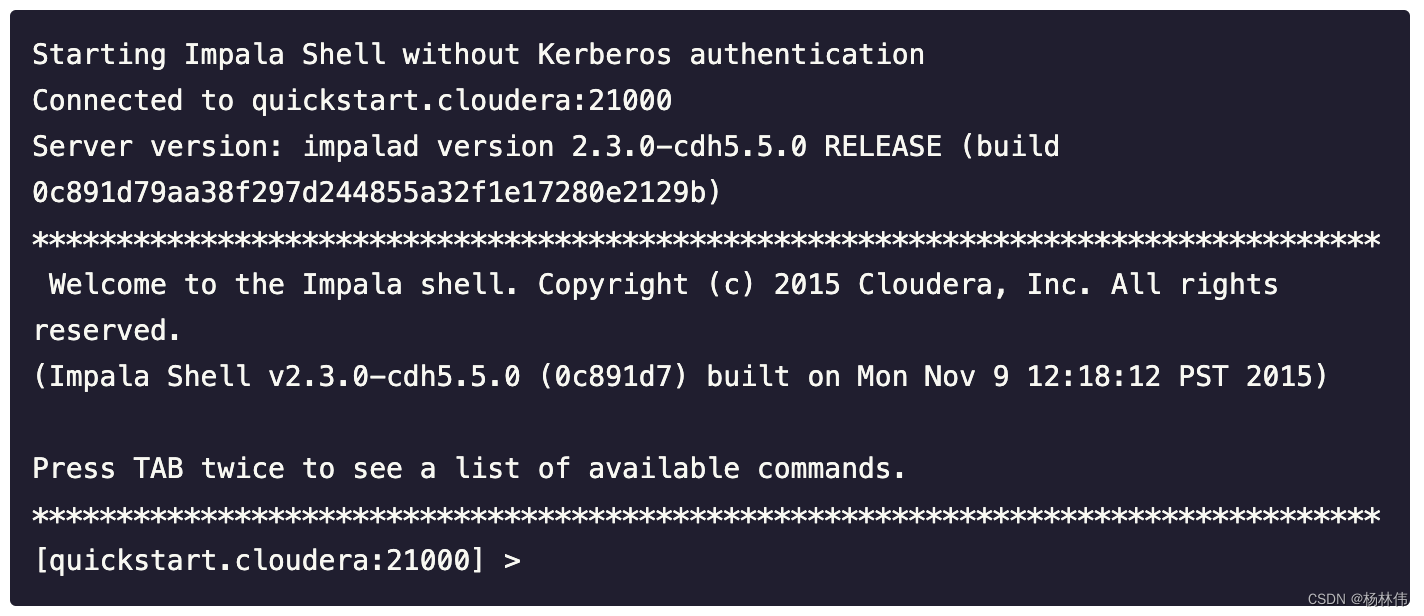
[root@chb1 ~]# impala -shell

2.内部命令(同sql操作类似)
show database;
show create table table_name;
select * from table_name;

3.退出impala
[chb1:21000] default> quit;
[chb1:21000] default> exit;
4.连接到指定的机器impalad上去执行
[chb1:21000] default>connect hostname
5.增量刷新
刷新某一张表的元数据,主要用于刷新hive当中数据表里面的数据改变的情况
[chb1:21000] default>refresh dbname.tablename
6.全量刷新
性能消耗较大,主要用于hive当中新建数据库或者数据库表的时候来进行刷新
[chb1:21000] default>invalidate metadata
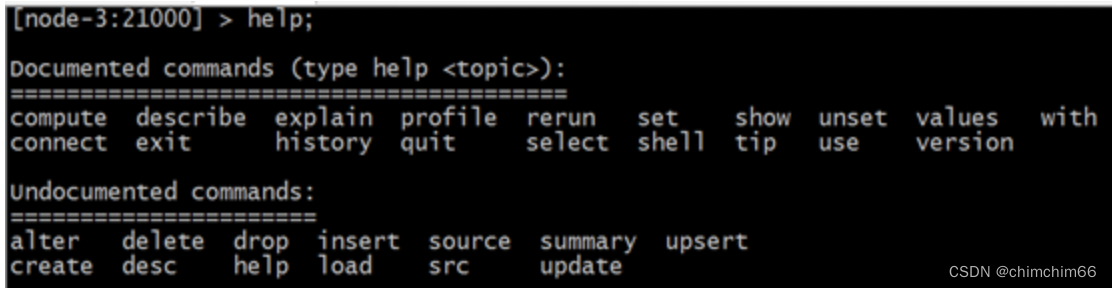
7.帮助
[chb1:21000] default>help;
8.查看sql语句的执行计划
[chb1:21000] default>explain select * from table;
9.打印出更加详细的执行步骤
[chb1:21000] default>profile;
10.设置显示级别(0,1,2,3)
set explain_level
二、impala外部命令
1.查看帮助手册
impala-shell –h
2.刷新impala元数据
与建立连接后执行 REFRESH 语句效果相同
impala-shell –r (--refresh_after_connect)
3.执行指定路径的sql文件
impala-shell –f (--query_file=query_file)
impala-shell -f a.sql
4.直接执行查询语句
impala-shell -q(--query=query)
impala-shell -q "select * from table"
5.指定连接运行 impalad 守护进程的主机
默认端口是 21000。你可以连接到集群中运行 impalad 的任意主机。
impala-shell –i hostname (--impalad=hostname)
6.保存执行结果到文件
impala-shell –o (--output_file filename)
impala-shell –o 文件名
7.对查询结果去格式化
impala-shell –B(--delimited)
8.去格式化后指定分隔符
--output delimiter-:该选项对使用-B选项去格式化输出的查询结果指定各字段间的分,隔符.默认的分隔符为制表键('\t'),如果输出字段中包含了分隔符字符,这个字段将使用/进行 转义
impala-shell –B --output_delimiter="," 指定分隔符,
--print_header 打印列名
9.显示查询的执行计划(与EXPLAIN语句输出相同)和每个查询语句底层的执行步骤的详细信息
impala-shell -p
impala-shell --show-profiles
10.指定当shell连接到impalad节点时使用kerberos身份验证.但是如果impalad节点本身没有启用kerberos,连接将会报错.
impala-shell -k或者impala-shell -kerberos (--kerberos)
11.该选项后面跟kerberos服务名称让impala-shell验证一个特定的impalad服务.如果没有指定kerberos服务名称,将使用impala作为默认的名称.如果该选项用于一个不支持kerberos的连接,将会返回错误
-s或者-kerberos_service_name
12.启用详细信息输出
-V或者-verbose
13.禁用详细信息输出
-quiet
14.查询版本信息
-v (--version)
15.查询执行失败时继续执行
-c
16.启用LDAP认证
-l
17.启用LDAP时,指定用户名
-u