OpenAI API 核心概念介绍
OpenAI API 可以用于处理自然语言或编程语言的理解及生成相关的任务(从内容生成、语义搜索到分类等)。
ChatGPT 基于GPT 3.5 大规模预训练语言模型,通过“基于提示词的标注数据的监督学习 + 基于人类反馈的强化学习”微调预训练语言模型,以让模型学会理解人类的命令指令的含义,以及判断对于用户给定的指令,什么样的答案是优质的(内容丰富、有帮助、无害、无歧视等)。
核心概念
1. 提示(Prompts) 和补全(completions)
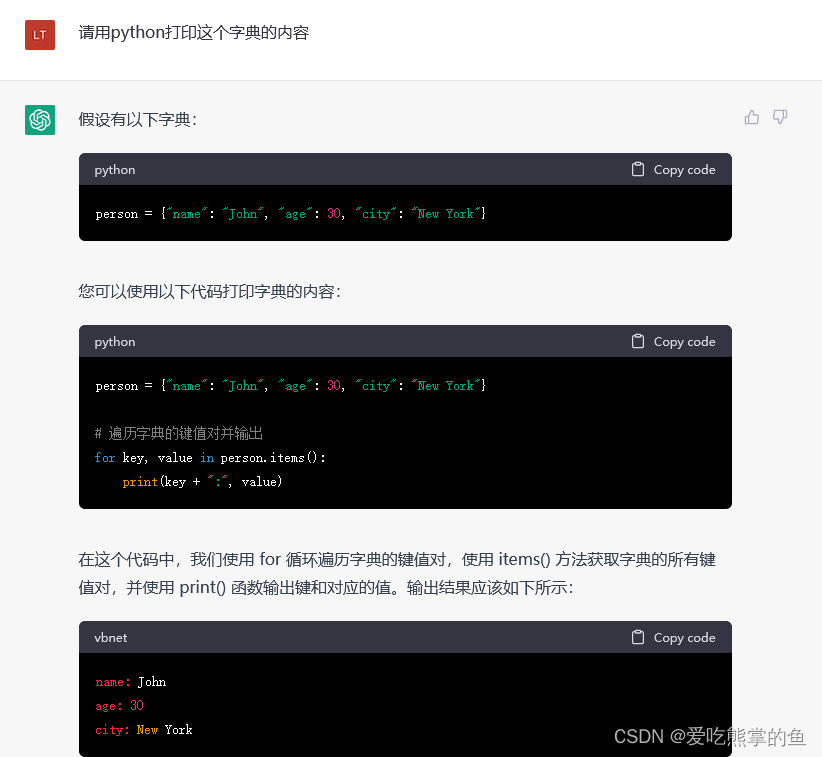
补全是其API的核心,它提供了一个简单、强大且灵活的接口,模型根据输入的提示词(Prompt)生成补全(completion)内容, 例如,如果你给API提示,“为一家冰淇淋店写一句标语”,它将返回:“我们为每一勺冰淇淋提供微笑!”。
设计提示词的过程,本质上是你在对模型进行编程,通常通过提供一些说明或一些例子来实现。为了获得准确的结果,需要尽量明确描述你的需求、提供高质量并准确的数据。好的提示词的秘诀是:提供示例而不仅仅是告诉需求。
这与大多数其他 NLP 服务不同,后者是为单一任务设计的,如情感分类或命名实体识别。而该补全接口几乎可以用于任何任务,包括内容或代码生成、摘要、扩展、对话、创意写作、风格转换等等。
2.标识符(Tokens)
模型通过将文本分解为标识符来理解和处理文本。可以是单词,也可以是字符集。例如,单词“hamburger”被分解为“ham”、“bur”和“ger”,而像“pear”这样简短而常见的单词则是一个单一的标识符。许多标识符以空格开始,例如“ hello”和“ bye”。
一个 API 请求中处理的令牌数量取决于输入和输出的长度。一个粗略基于经验的计算方法是,对于英语文本来说,1 个标记大约是 4 个字符或 0.75 个单词。要记住的一个限制是,提示词和生成的补全内容长度之和不能超过模型的最大上下文长度(对于大多数模型是 2048 个标识符,大约 1500 个单词)。可以通过工具检测文本对应的标识符数量。
3.模型(Models)
OpenAI API 由一组具有不同功能和价位的模型提供支持。可以对原始基本模型进行有限的定制。基础的 GPT-3 模型包括: Davinci、Curie、Babbage 和 Ada。 Codex 系列是 GPT-3 的后代,通过自然语言和代码的训练。
- Gpt -3.5 是在GPT-3基础上改进的一组模型,可以理解和生成自然语言或代码
- DALL·E 是一个可以根据自然语言提示生成和编辑图像的模型
- Whisper 可以将音频转换为文本的模型
- Embeddings 一组可以将文本转换为数字形式的模型
- Codex 一组可以理解和生成代码的模型,包括将自然语言转换为代码
- Moderation 一种微调模型,可以检测文本是否敏感或不安全