简介
Impala是Cloudera公司主导开发的新型查询系统,是Google Dremel的开源实现。它提供SQL语义,能够查询存储在Hadoop的HDFS和HBase中的PB级大数据。已有的Hive系统虽然也提供了SQL语义,但是由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性;相比之下,Impala的最大特点也是最大卖点就是它的快速。在介绍Impala之前需要先介绍Google的Dremel系统,因为Impala最开始是参照 Dremel系统进行设计的。
Dremel系统
Dremel是Google的交互式数据分析系统,它构建于Google的GFS(Google File System)等系统之上,支撑了Google的数据分析服务BigQuery等诸多服务。Dremel的技术亮点主要有两个:
一是实现了嵌套型数据的列存储;
二是使用了多层查询树,使得任务可以在数千个节点上并行执行和聚合结果。
列存储在关系型数据库中并不陌生,它可以减少查询时处理的数据量,有效提升查询效率。Dremel的列存储的不同之处在于它针对的并不是传统的关系数据,而是嵌套结构的数据。Dremel可以将一条条的嵌套结构的记录转换成列存储形式,查询时根据查询条件读取需要的列,然后进行条件过滤,输出时再将列组装成嵌套结构的记录输出,记录的正向和反向转换都通过高效的状态机实现。另外,Dremel的多层查询树则借鉴了分布式搜索引擎的设计,查询树的根节点负责接收查询,并将查询分发到下一层节点,底层节点负责具体的数据读取和查询执行,然后将结果返回上层节点。
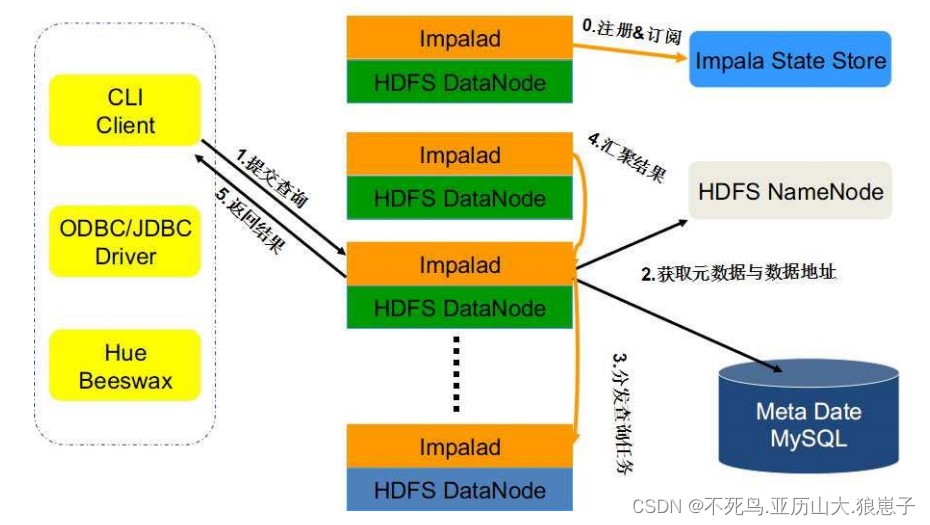
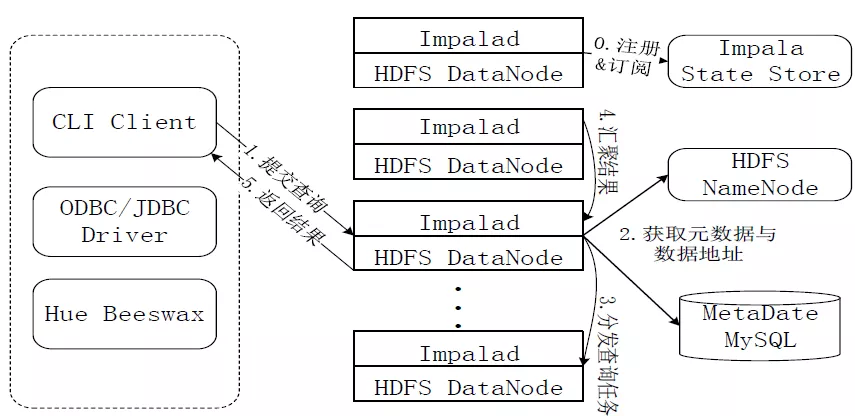
Impala是Cloudera在受到Google的Dremel启发下开发的实时交互SQL大数据查询工具,Impala没有再使用缓慢的Hive+MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成),可以直接从HDFS或HBase中用SELECT、JOIN和统计函数查询数据,从而大大降低了延迟。Impala其实就是Hadoop的Dremel,Impala使用的列存储格式是Parquet。Parquet实现了Dremel中的列存储,未来还将支持 Hive并添加字典编码、游程编码等功能。Impala使用了Hive的SQL接口(包括SELECT、 INSERT、Join等操作),但目前只实现了Hive的SQL语义的子集(例如尚未对UDF提供支持),表的元数据信息存储在Hive的 Metastore中。StateStore是Impala的一个子服务,用来监控集群中各个节点的健康状况,提供节点注册、错误检测等功能。 Impala在每个节点运行了一个后台服务Impalad,Impalad用来响应外部请求,并完成实际的查询处理。
Impalad主要包含Query Planner、Query Coordinator和Query Exec Engine三个模块。QueryPalnner接收来自SQL APP和ODBC的查询,然后将查询转换为许多子查询,Query Coordinator将这些子查询分发到各个节点上,由各个节点上的Query Exec Engine负责子查询的执行,最后返回子查询的结果,这些中间结果经过聚集之后最终返回给用户。
性能
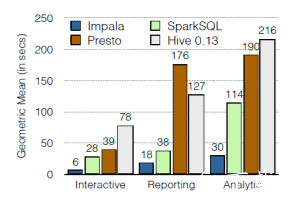
Impala是hadoop上交互式MPP SQL引擎,也是目前性能最好的开源SQL-on-hadoop方案,能够实现对海量数据的实时查询分析。
如下图所示, impala性能超过SparkSQL、 Presto、 Hive。
优势
快速
可以方便地执行SQL语句,在数秒内返回查询分析结果。
这一点,其实还要依赖于你在HDFS或HBase上存储的数据的规模,依赖于你对Impala系统的配置调优情况,可能还依赖于你写的SQL语句的执行效率。
灵活
可以直接查询存储在HDFS上的原生数据,也可以查询经过优化设计而存储的数据,只要数据的格式它们能够兼容MapReduce、Hive、Pig等等。
整合&开放
可以非常容易地与Hadoop系统整合,并使用Hadoop生态系统的资源和优势,也不需要将数据迁移到特定的存储系统就能满足查询分析的要求。
可伸缩性
可以很好地与一些BI应用系统协同工作,如Microstrategy、Tableau、Qlikview,等等。
支持特性
Impala支持的特性,主要包括如下几点:
- 对 ANSI-92 SQL标准的支持
Impala支持ANSI-92 SQL所有子集,包括CREATE、ALTER、SELECT、INSERT、JOIN、GROUP BY以及子查询。它还支持分区JOIN、常用的聚合函数(SUM、COUNT、MAX、MIN、AVG等等)、topN查询。你使用这些语句时,可以像使用关系数据库中使用的SQL语句一样去设计,很容易上手。
- 数据来源与数据格式
Impala可以操作HDFS、HBase中存储的数据,支持如下HDFS的支持文件格式:Text file、SequenceFile、RCFile、Avro file、Parquet,支持的压缩格式有:Snappy、GZIP、Deflate、BZIP,其中Snappy压缩格式的性能更好一些。
- 支持的数据访问接口
主要包括Hive所支持的如下接口:JDBC Driver、ODBC Driver、Hue Beeswax、Cloudera Impala Query UI.,另外,还可以通过CLI接口(也就是Impala Shell)访问。