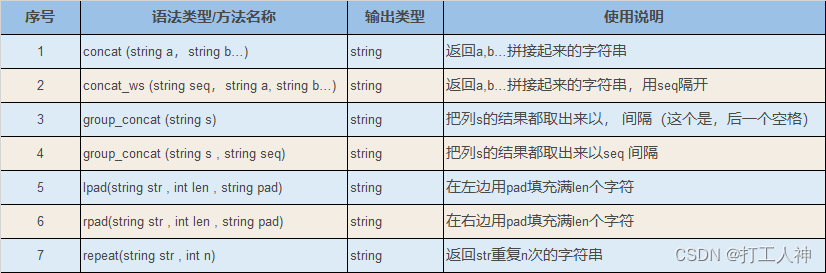
作为铺垫,本文首先对Broadcast Join和Partitioned Join进行简要介绍。
Broadcast Join
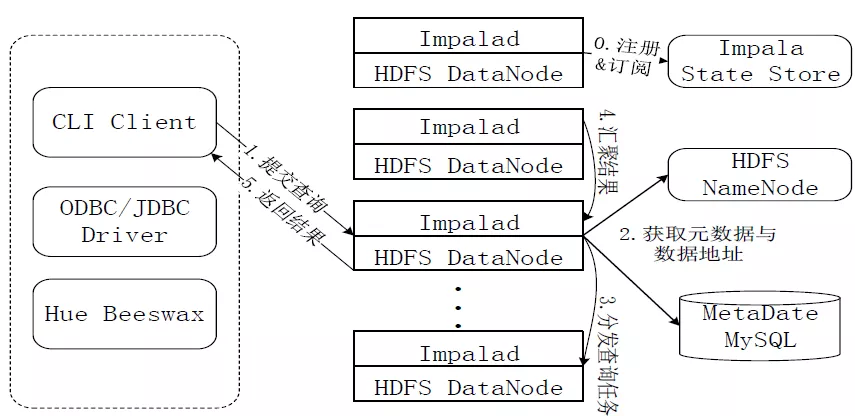
顾名思义,Broadcast Join就是广播的方式进行Join。以下图为例,假设Join操作为SELECT A JOIN B ON A.id=B.id,Broadcast Join就是将B表(rhs)数据广播到所有扫描了A表的节点中,每一个扫描A表数据的impalad都会用自己持有的部分数据与接收到的完整的B表进行Join,随后将结果聚合得到完整的Join结果(如下图所示)。

这种Join方式适合于体积较大的表与体积较小的表进行关联,如下图这种情况,一个100多G的表与几十KB的表进行Join(绿框内显示BROADCAST即为广播Join),对小表进行广播的网络传输代价几乎可忽略不计,在内存中的哈希计算开销也很小,但如果是采用Partitioned Join,则会增加许多网络中的通信传输代价,下面对其进行简要介绍。

Partitioned Join
区别于Broadcast Join,Partitioned Join更适合两个较大的表进行关联(两个小表无所谓哪种Join一般都不会很慢)。其原理图如下图所示,仍假设SELECT A JOIN B ON A.id=B.id,当两进行Partitioned Join时,对AB两表的Join key进行分区,具有相同key的数据分布到相同的impalad,此时各impalad内的数据相当于被打散的AB两表(shuffle),再在所有impalad内进行小数据块的Hash Join,完成后进行结果聚合(如下图所示)。

下图为一个使用Partitioned Join的例子,相比Broadcast Join,Partitioned Join多了一个EXCHANGE,这是由于Partitioned Join不是单独将一个表发送到网络中,而是两个表要把shuffle后的数据全部发送出去。从图中也可看出,两个表的体积相对接近,因此Impala采用了分区JOIN的方式。

极端情况下,假如错误地对大表进行了Broadcast,将会对网络造成极大的负担,而且相关查询会非常慢,耗时过久的慢查询也会影响队列内其他查询的正常执行。
Broadcast vs Partitioned如何选择
对于一个大数据查询引擎,任何一步操作均需要最大化考虑性能的影响,否则在数据量极大的条件下可能出现不可预估的后果,Impala有一套CBO(Cost-based Optimizer,基于代价的优化)机制用来指导执行计划的生成,不仅在JOIN策略的选择上,在整个执行计划的生成上都有CBO的影子。本文接下来先介绍执行计划中对JOIN策略的取舍。
CBO对于JOIN策略的影响
对于JOIN策略的判断,Impala有基于代价的一系列计算,通过分别计算两种JOIN的网络传输代价和内存代价的和来判断最优的策略。
广播Join的cost计算
Impala中广播JOIN的代价计算可总结为以下公式:
cost_broadcast = 2 × size_rhs × instNum_lhs
其中,size_rhs为根据右表基数和每行数据序列化后的预估大小计算得到,意为右表在网络中传输的数据大小;instNum_lhs为左表所在impalad的个数,由MT_DOP(多线程处理参数,线程个数)和扫描左表的impalad的个数确定,意为所有参与左表扫描的impalad总个数;两者相乘为一次网络传输中右表需要传输的数据量;内存代价与网络代价相同,也为size_rhs与impalad个数的乘积,因此乘2就是总代价。在几种情况下,广播代价将无法正确计算,置为-1:
1)右表统计信息缺失
计算代价前,Impala会直接获取右表的基数进行判断,由于右表可能为子查询得到的中间结果或数据表:假如为直接扫描到的数据表,那么直接获取表的基数,再判断是否为-1。假如为子查询,无论子查询中SQL写了哪种JOIN,只要有一张表的统计信息缺失,那么Impala均会把子查询的结果基数置为-1,广播代价也会直接置为-1。左表的统计信息缺失不影响广播代价的计算,如果当前也是子查询,结果的基数将为-1。(基数:Impala用来判断表或数据大小的重要指标,一般是从数据总行数和所有列的数据类型计算得到并存入metastore,使用时从metastore库中获取,Impala会随着数据插入/删除进行动态调整,统计信息缺失的表基数为-1)
2)左表的SCAN节点数获取失败
在1)的条件满足的情况下,假如没有正确获取到size_rhs,broadcast的代价也会置为-1。
分区Join的cost计算
计算分区JOIN代价的计算公式可总结如下:
cost_partition = NetworkCost_lhs + NetworkCost_rhs + size_rhs
NetworkCost = Cardinality × AvgSerializedRowSize
其中NetWorkCost_lhs和NetWorkCost_rhs分别为lhs和rhs的网络代价,rhs_size仍为rhs的大小,即内存代价,网络代价由基数和平均序列化后的行大小相乘(根据统计信息预估)。在计算代价前,需要先进行一些判断:
1)两边表或子执行计划的结果统计信息未缺失,然后判断2);
2)根据分区和Join key判断是否需要经过网络传输数据,如果为否,则网络代价为0;
随后进行代价计算,如果2)的判断均使lhs和rhs的网络代价为0,那么总代价则直接为内存代价;反之,lhs和rhs的网络代价均为表大小的估计值,通过基数与平均表序列化后每行数据大小相乘得到。最终两者相加为总代价。
由于Impala一般在两个大小相对接近大表Join时选择Partitioned Join,因此直接取一个表的大小作为内存代价。结合两种代价的计算公式可看出,同样的两个表进行Join,当impalad数量不多时,Broadcast Join和Partitioned Join的代价可能会较为接近,但在参与处理的impalad数量较多时,进行Broadcast Join的代价可能就会超过Partitioned Join,因此对于两者的选择不应一成不变,还需要根据实际情况判断。
策略选择
在计算得到广播Join和分区Join的代价后,就可以通过对比来选择更优的策略,但这里有一些特别的处理:
1)当Join类型为右外连接/右半连接/右反连接/全外连接时,直接选择分区Join;
2)当Join类型为NULL AWARE LEFT ANTI JOIN(无感知的左反连接)时,直接选择广播Join;
3)发现有Hint时,采用Hint中的Join方式;
4)当广播Join与分区Join的代价相同或两者任意一个为-1时,采用默认配置的Join方式,可在配置文件或通过set修改;
随后则通过广播和分区JOIN的代价进行判断,当分区JOIN的代价更小时,采用分区JOIN;反之若广播JOIN的代价更小,且同时满足:
1)mem_limit无限制或rhs的大小小于mem_limit,mem_limit可在配置文件或通过set修改;
2)broadcast_bytes_limit参数无限制或rhs大小小于broadcast_bytes_limit(该参数可在配置文件或通过set修改,用来防止Broadcast Join过程中传输过大的数据到网络中,默认约为34GB);
则选择广播JOIN。
注意,广播和分区JOIN的JOIN key均必须为等值Join,否则将进行NESTED LOOP JOIN。
JOIN key的顺序
Impala的FE端在生成单节点执行计划时,对每个操作(如SQL中的各种运算符、AND/OR、[NOT] IN等等)均内置了每种操作的代价数值(如下图所示),无论是子查询得到的中间结果还是数据表,均可通过特定的算法计算出目前的代价,再通过排序来优化执行顺序。JOIN两边的不仅仅是表,也可能是子查询的中间结果,因此需要对所有基本操作进行代价的计算。需要注意的是,如果检测到目前只有1个impalad,那么将直接执行单节点执行计划,不会生成分布式执行计划。
每种操作的代价计算通过内置的值和筛选率(selectivity)进行计算,筛选率可理解为经过这个操作之后,筛选数据/原数据的值,实际数值通过统计信息来计算得到。默认的筛选率为0.1,如果表的统计信息缺失,那么将进行修正:
selectivity = exp{ln0.1 / num}
其中num为缺失统计信息的表个数。计算代价时,遍历目前查询的所有操作,每次遍历选出当前cost最小的操作添加到结果list中,然后进行筛选率的修正,如此直到所有操作遍历完成,其中cost计算可描述为:
cost_total = cost_currentOp + cost_otherOp × selectivity_fixed
selectivity_fixed = selectivity^(1/n)
其中cost_total为当前操作的代价,cost_currentOp为操作自有的代价,cost_otherOp为其他所有操作的代价,selectivity_fixed为当前的筛选率,n为当前遍历的次数。Join key作为SQL中的一部分,也会参与排序优化,但为使得优化的效果最好,需要参与扫描的表具有统计信息,否则可能出现性能更坏的情况。
综合2和3的流程,可将JOIN方式的选择总结如下:

总结
Impala通过基于代价的优化,来动态判断当前SQL的Join策略应如何在广播和分区Join中选择,以及各种子句的排序优化。当参与Join的两个表一大一小时,一般将考虑广播Join;两个大表Join时,则使用分区Join。广播Join的开销取决于右表的大小和节点数,分区Join的开销取决于两表的大小。当统计信息缺失时,如果误将大表进行了Join,将对集群的计算性能和网络环境造成严重影响。综合来看,表的统计信息对执行计划的优劣有着重要的影响,因此在执行SQL前,应尽可能先计算所有被查询表的统计信息,且应先通过EXPLAIN查看执行计划是否为最优。
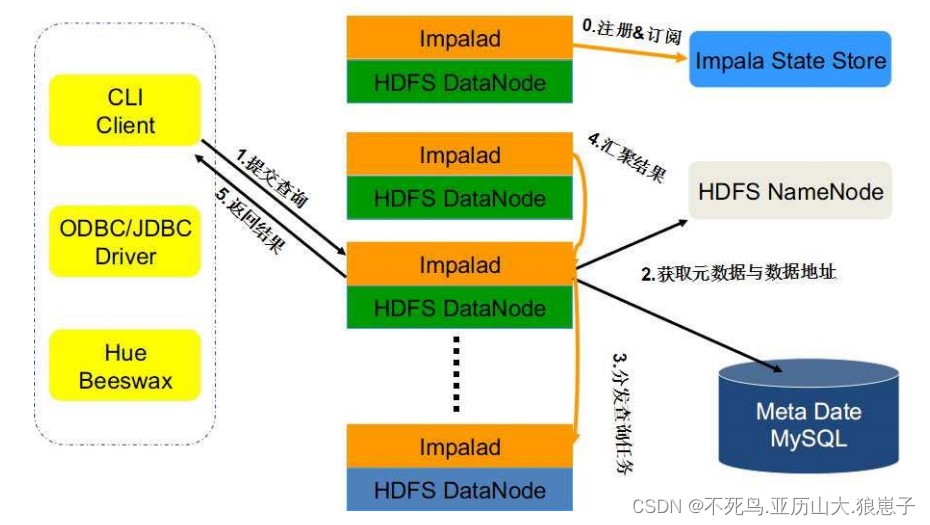
Impala 如何确定 Join 策略
如何确定 Join 策略
与主流的数据库和数仓查询引擎一样,Impala 也是基于代价模型进行执行计划优化(CBO)。只有获取足够的统计信息,才能支撑 Impala 选取较优的执行计划。
本节分析 Join 的计算方式,以解文章开始提出的问题。对于这两种 join 类型,总成本计算为通过网络发送的数据量,加上插入到哈希表中的数据量。
1. 计算两种 join 成本:
能计算的前提是有统计信息,否则都是 -1.
broadcast:将右侧 Fragment 输出发送到左侧的每个节点,并在节点构建哈希表。
计算:(右侧Fragment 数据大小 + 哈希表大小)* 左侧实例数
————————————————