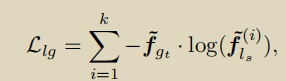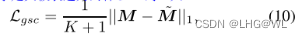Weakly-Supervised Semantic Segmentation via Sub-category Exploration
- Abstract
- 问题
- 1.Introduction
- 2. Related Work
- 2.1weakly-supervised semantic segmentation(WSSS)弱监督语义分割的初始预测。---Initial Prediction for WSSS.
- 2.2 、Response Refinement for WSSS:WSSS(弱监督语义分割)的响应细化
- 2.3 Unsupervised Representation Learning.---无监督学习表示
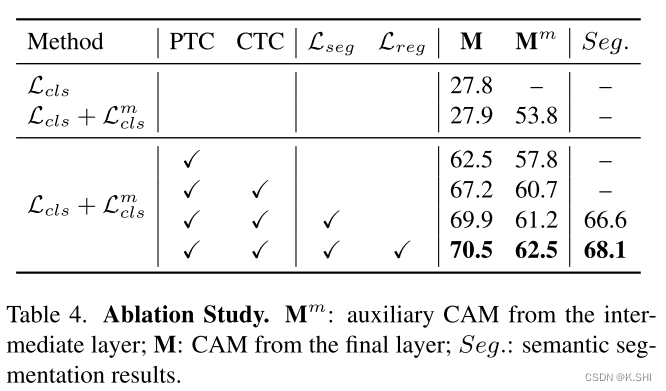
- 3. Weakly-supervised Semantic Segmentation
- 3.1. Algorithm Overview
- 3.1.1 Preliminaries: Initial Response via CAM.---初步反应:通过CAM的初步反应。
Abstract
现有的使用图像级标注的弱监督语义分割方法通常依赖于初始响应来定位目标区域。然而,分类网络生成的这种响应图通常集中在有区别的对象部分,因为网络不需要优化目标函数的整个对象。为了强制网络关注对象的其他部分,我们提出了一种简单而有效的方法,通过利用子类别信息引入一个自我监督任务。具体来说,我们对图像特征进行聚类,在每个标注的父类内生成伪子类别标签(pseudo sub-categories labels),并构造子类别目标,为网络分配更具有挑战性的任务。通过迭代聚类图像特征,训练过程不局限于最具区别性的目标部分,从而提高了响应图的质量。我们进行了广泛的分析,以验证所提出的方法,并表明我们的方法优于最先进的方法。
问题
本论文是否只有进行了分析,而没有进行实验呢?
1.Introduction
语义分割的目的是为图像中的每个像素指定一个语义类别。它已经成为计算机视觉中最重要的任务之一,有着广泛的应用,如图像编辑和场景识别。近年来,基于深度卷积神经网络(deep convolutional neural network, CNN)的方法[16,5,42]已经发展成为语义分割的方法,并取得了显著的进展。然而,这种方法依赖于学习监督模型,需要像素级的注释,这需要大量的工作和时间。为了减少像素级地面真实标签标注的ef- fort,提出了使用图像级[1,22,29,32]、视频级[6,45,35]、边界框(bounding box)[28,8,20]、点级[2]和基于涂鸦的[26,37]等不同类型标签的数量弱监督方法。在这项工作中,我们的重点是使用可以毫不费力地获得的图像级标签,在弱监督情景下,也是一个更具挑战性的案例。
现有的图像级标签弱监督训练算法主要包括3个顺序步骤:
1)预测初始类别响应图对目标进行定位;
2)将初始响应细化为伪地面真实;
3)训练基于伪标签的分割网络。虽然最近的方法已经取得了有希望的结果[1,18,38,40],但大多数方法都集中在改进第二和第三步。因此,这些方法可能会受到第一步(即初始反应)中产生的不准确预测的影响。在这里,我们的目的是改善初始预测的性能,这将有利于后续步骤。
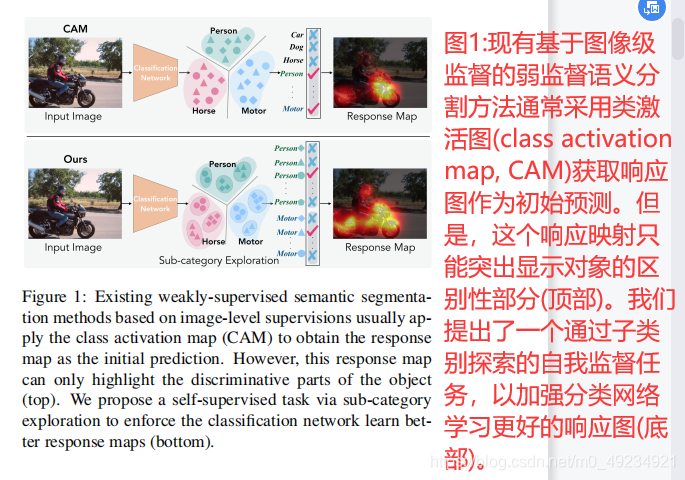
为了预测每个类别的初始响应图,已经开发了许多基于类激活图(CAM)模型[46]的方法。最初,这些方法训练一个分类网络,并使用其在分类器中学习到的权重作为线索来计算特征图的加权和,可视为响应图。然而,这样的响应映射可能只关注对象的一部分,而不是定位整个对象(见图1的顶部)。一种解释是,分类器的目标不需要看到整个对象来优化损失函数。这损害了分类器定位物体的能力。
我们技术的核心是在不损害最初的目标的前提下,对网络施加(impose)更具有挑战性的任务,为了网络有更好的学习表现。为此,我们提出了一种简单而有效的方法,即引入一个自我监督任务,该任务以无监督的方式发现子类别,如图1底部所示。具体地说,我们的任务包括两个步骤:
1)对图像进行聚类特征提取分类网络为每个注释的父类(例如,20 2012年帕斯卡VOC父类数据集[11])
(另一种翻译:从分类网络中提取图像特征,对每个标注的父类进行聚类)
2)使用集群任务为每个图像伪标签优化子范畴的目标。
(不另一种翻译:利用每个图像的聚类分配作为伪标签,优化子类别目标。)
一方面,父分类器通过监督训练建立的特征空间作为无监督子类别聚类的指导; 另一方面,子类别目标提供了额外的梯度来增强特征表示,并利用原始特征空间的子空间来获得更好的结果。因此,分类模型采取了更具有挑战性的任务,而不是局限于更容易的目标,只学习父分类器。此外,为了保证在实践中更好地收敛(convergence:会聚 趋同 收敛 衔接),我们(iteratively:迭代地 ;反复的)迭代改变了特征聚类和伪训练子类别目标这两个步骤。
我们在PASCAL VOC 2012数据集[11]上进行了大量实验,以证明我们的方法在生成更好的初始响应映射来定位对象方面的有效性。因此,我们的方法导致了良好的性能,最终的语义分割结果相对于最先进的弱监督方法。此外,我们提供了广泛的消融研究和分析来验证我们方法的稳健性。有趣的是,我们注意到网络能够根据对象大小/类型、上下文以及与其他类别的共存情况来区分子类别。本工作的主要贡献总结如下:
1、我们提出了一种简单而有效的方法,通过自监督任务来增强分类网络中的特征表示。这也改进了初始类激活映射用于弱监督语义分割。
2、我们通过迭代进行无监督聚类和用自监督的方式对子类别目标进行伪训练来探索子类别发现的思想。
3、我们提出了广泛的研究和分析,以显示提出的方法的有效性,显著提高了初始响应图的质量,并导致更好的语义切分结果。
2. Related Work
在这项工作的背景下,我们讨论了使用图像级标签的弱监督语义分割weakly-supervised semantic segmentation(WSSS)的方法,包括专注于生成伪地面真实的初始预测和细化的方法。此外,本节将讨论与无监督表示学习相关的算法。
2.1weakly-supervised semantic segmentation(WSSS)弱监督语义分割的初始预测。—Initial Prediction for WSSS.
初始线索对分割任务至关重要,它可以为分割图的生成提供可靠的先验信息。(class activation map)类激活映射[46]是一种广泛用于( localizing the object.)定位目标的技术。它可以突出作为初始线索的类特定区域。然而,由于CAM模型是由分类任务训练的,它倾向于激活对象的小的有区别的部分,导致不完整的初始掩模(leading to incomplete initial masks.)。
已经发展了几种方法来缓解这个问题。许多方法[34,39]故意隐藏或抹去对象的区域,迫使模型寻找更多的不同部分。然而,这些方法要么随机隐藏固定大小的补丁,要么需要重复的模型训练和响应聚合步骤。许多变体[44,25]被提出通过端到端训练方式的对抗擦除策略来扩展初始反应,但这种策略可能会逐渐将注意力扩展到非物体区域,导致不准确的注意地图。最近,SeeNet方法[17]采用了自丢弃策略,鼓励网络同时使用对象和背景线索,这阻止了注意包含更多的背景区域。与使用擦除方案相比,FickleNet方法[24]引入了随机特征选择,以获得feature maps上不同的位置组合。通过聚合定位地图,它们获得包含物体更大区域的初始提示。
不同于通过迭代删除步骤或巩固注意图来发现互补区域来缓解问题的方法,我们提出的方法旨在通过自我监督的子类别探索,使网络在更具有挑战性的任务上学习更困难,从而增强特征表示并改进响应地图。
2.2 、Response Refinement for WSSS:WSSS(弱监督语义分割)的响应细化
通过扩大注意地图区域, 大量的方法被提出来细化初始线索。SEC方法[22]提出了一个同时约束全局加权秩池和低边界的损失函数来扩展定位地图。MCOF方案[38]采用自底向上和自顶向下的框架交替扩展目标区域并优化分割网络,而MDC方法[40]通过使用不同扩张速率的卷积层的多个分支来扩展种子。DSRG方法[18]在对分割网络进行训练时,采用种子区域生长的方法对初始定位地图进行细化。其他方法是通过亲和学习开发的。例如,AffinityNet[1]考虑像素级亲和,将局部响应传播到附近区域,而[12,13]探索跨图像关系,以获得可推断预测的互补信息。
然而,最初的种子仍然从CAM方法获得。如果这些种子只来自于物体的有区别的部分,则很难将区域扩展到非有区别的部分。此外,如果初始预测产生错误的注意区域,应用细化步骤将覆盖更不准确的区域。在本文中,我们重点改进了初始预测,这使目标定位更准确,有利于细化步骤。
2.3 Unsupervised Representation Learning.—无监督学习表示
无监督学习在计算机视觉领域得到了广泛的研究。一个优点是可以学习更好的图像表示,并将学习到的特性应用到不总是可用注释的任何特定领域或数据集上。Selfsupervised learning[9]利用一个借口任务,用直接从原始输入数据计算出来的“伪标签”来替换人类标注的标签。许多方法[27,30,31]已经被开发出来,但需要专家知识来精心设计一个可能导致良好翻译的借口任务ferable特征。为了减少对领域知识的需求ment, Coates和Ng[7]验证了带有K-means的特征学习系统tems可以成为一个可扩展的无监督学习ing模块,该模块可以训练无标记数据的模型,以提取有意义的特征。此外,最近的ap方法[3]采用了一个聚类框架,通过在im年龄描述符聚类和通过预测聚类分配更新CNN的权重之间切换来提取全视觉特征,以学习特定于缺少标注的领域的深度表示。在这项工作中,我们提出学习一种自我监督的方法来探索分类网络中的子类别,即使用无监督信号来增强特征表示,同时改进初始反应图来进行弱监督语义分割。
3. Weakly-supervised Semantic Segmentation
在本节中,我们将描述弱监督语义切分的框架,包括我们如何探索子类别来改进初始响应映射和生成最终语义切分结果的细节。
3.1. Algorithm Overview
为了获得初始响应,我们遵循训练分类网络的一般做法,利用CAM方法[46]来获得我们的基线模型。CAM方法通常只激活有区别的物体部分,这对于图像分类任务是不够的。为了解决这个问题,我们提出将一个更具挑战性的任务集成到目标中:自我监督子类别发现,以强制网络从更多的对象部分学习。
首先,对每个标注的父类,通过对图像特征进行K-means聚类,确定K个子类;根据聚类结果,我们给每个图像分配一个伪标签,作为子类别的索引。最后,我们构造一个子类别目标来联合训练分类网络。通过迭代更新特征提取器、两个分类器和子类别伪标签,增强的特征表示导致更好的分类,从而逐步产生响应映射,达到更完整的对象区域。整个过程如图2所示。然后利用[1]中的方法扩展响应图,将响应图作为伪地形图训练分割网络。还需要注意的是,我们的方法侧重于初始预测,所以并不局限于某些区域扩展或分割训练方法。