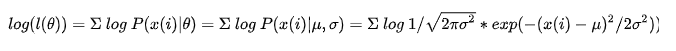特征值分解
特征值分解是将一个方阵A分解为如下形式:
A = Q Σ Q − 1 A=Q\Sigma Q^{-1} A=QΣQ−1
其中,Q是方阵A的特征向量组成的矩阵, Σ \Sigma Σ是一个对角矩阵,对角线元素是特征值。
通过特征值分解得到的前N个特征向量,表示矩阵A最主要的N个变化方向。利用这前N个变化方向,就可以近似这个矩阵(变换) 。
奇异值分解
奇异值分解(Singular Value Decomposition,SVD)是在机器学习领域广泛应用的算法,它不仅可以用于降维算法中的特征分解,还可以用于推荐系统,以及自然语言处理等领域。 它能适用于任意的矩阵的分解。
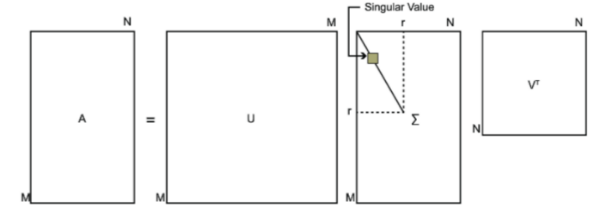
SVD是将m*n的矩阵A分解为如下形式:
A = U S V T A=USV^T A=USVT
其中,U和V是正交矩阵,即 U T U = I , V T V = I U^TU=I,V^TV=I UTU=I,VTV=I,U是左奇异矩阵, U ϵ R m × m U \epsilon R^{m\times m} UϵRm×m,S是 m × n m\times n m×n的对角阵(对角线上的元素是奇异值,非对角线元素都是0), V T V^T VT右奇异向量, V ϵ R n × n V \epsilon R^{n\times n} VϵRn×n。
特征值用来描述方阵,可看做是从一个空间到自身的映射。奇异值可以描述长方阵或奇异矩阵,可看做是从一个空间到另一个空间的映射。
奇异值和特征值是有关系的,奇异值就是矩阵 A ∗ A T A*A^T A∗AT的特征值的平方根。
步骤
输入:样本数据
输出:左奇异矩阵,奇异值矩阵,右奇异矩阵
-
计算特征值:特征值分解 A A T AA^T AAT,其中 A ϵ R m × n A \epsilon R^{m\times n} AϵRm×n为原始样本数据
A A T = U Σ Σ T U T AA^T=U\Sigma \Sigma^TU^T AAT=UΣΣTUT
得到左奇异矩阵 U ϵ R m × m U\epsilon R^{m\times m} UϵRm×m和奇异值矩阵 Σ ′ ϵ R m × m \Sigma^{'}\epsilon R^{m\times m} Σ′ϵRm×m -
间接求部分右奇异矩阵:求 V ϵ R m × n V\epsilon R^{m\times n} VϵRm×n
利用 A = U Σ ′ V ′ A=U\Sigma^{'}V^{'} A=UΣ′V′可得
V ′ = ( U Σ ′ ) − 1 A = ( Σ ) − 1 U T A V^{'}=(U\Sigma^{'})^{-1}A=(\Sigma)^{-1}U^TA V′=(UΣ′)−1A=(Σ)−1UTA -
返回 U , Σ ′ , V ′ U,\Sigma^{'},V^{'} U,Σ′,V′,分别为左奇异矩阵,奇异值矩阵,右奇异矩阵。
python实现
调用eig和svd方法
import numpy as npdata = np.array([[1, 0, 4], [2, 2, 0], [0, 0, 5]]) # 数组
# 调用np.linalg.eig()对data*data'进行特征值分解
eig_value, eig_vector = np.linalg.eig(data.dot(data.T))
# 将特征值降序排列
eig_value = np.sort(eig_value)[::-1]
print("特征值:", eig_value) # 特征值
print("特征值的平方根:", np.sqrt(eig_value)) # 特征值的平方根# 调用np.linalg.svd()对data进行奇异值分解
U, S, V = np.linalg.svd(data)
# 降到两维,计算U*S*V 结果应该和data几乎相同
recon_data = np.round(U[:,:2].dot(np.diag(S[:2])).dot(V[:2,:]), 0).astype(int)
print("奇异值:", S) # 奇异值
print("data:\n",data)
print("U*S*V的结果:\n",recon_data)
从结果上验证了奇异值就是矩阵 A ∗ A T A*A^T A∗AT的特征值的平方根。结果如下:
特征值: [41.44423549 8.26378188 0.29198263] 特征值的平方根: [6.43771974 2.87467944 0.54035417] 奇异值: [6.43771974 2.87467944 0.54035417] data:[[1 0 4][2 2 0][0 0 5]] U*S*V的结果:[[1 0 4][2 2 0][0 0 5]]
按SVD原理实现
import numpy as np# 1.调用np.linalg.eig()计算特征值和特征向量
eig_val, u_vec = np.linalg.eig(data.dot(data.T))
s_val = np.sqrt(eig_val) # 奇异值:是特征值的平方根
# 将向量u_vec对应排好序
s_val_sort_idx = np.argsort(s_val)[::-1]
u_vec = u_vec[:, s_val_sort_idx]
# 奇异值降序排列
s_val = np.sort(s_val)[::-1]
# 2.计算奇异值矩阵的逆
s_val_inv = np.linalg.inv(np.diag(s_val))
# 3.计算右奇异矩阵
v_vec = s_val_inv.dot((u_vec.T).dot(data))# 降到两维,计算U*S*V 结果应该和data几乎相同
recon_data = np.round(u_vec[:,:2].dot(np.diag(s_val[:2])).dot(v_vec[:2,:]),0).astype(int)
print("左奇异矩阵U:\n", u_vec)
print("奇异值Sigma:\n", s_val)
print("右奇异矩阵V:\n", v_vec)
print("data:\n",data)
print("U*S*V的结果:\n",recon_data)
运行结果
左奇异矩阵U:[[ 0.63464303 -0.12919086 0.76193041][ 0.03795231 -0.97952798 -0.19769816][ 0.77187295 0.15438478 -0.61674751]]
奇异值Sigma:[6.43771974 2.87467944 0.54035417]
右奇异矩阵V:[[ 0.11037257 0.01179061 0.99382034][-0.72642772 -0.68148675 0.08876135][ 0.67832195 -0.73173546 -0.06665242]]
data:[[1 0 4][2 2 0][0 0 5]]
U*S*V的结果:[[1 0 4][2 2 0][0 0 5]]
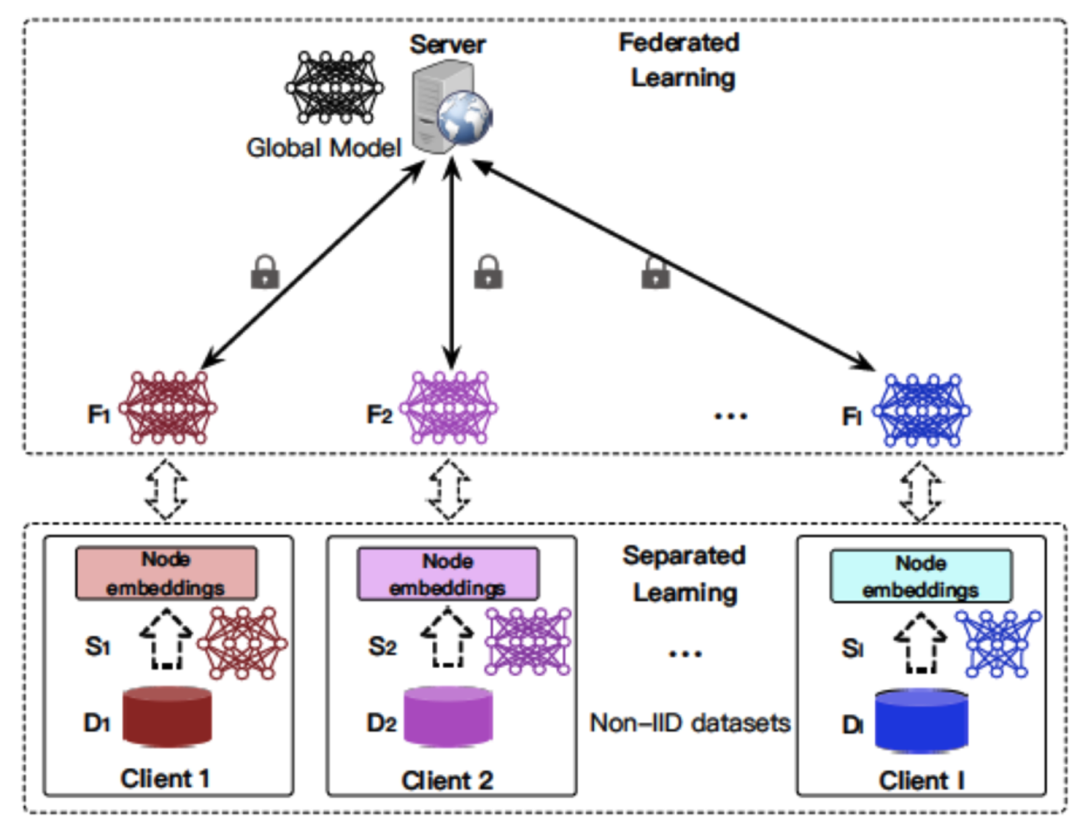
基于SVD的图像压缩
基于SVD图片压缩: :图片其实就是数字矩阵,通过SVD将该矩阵降维,只使用其中的重要特征来表示该图片从而达到了压缩的目的。
path = 'Andrew Ng.jpg'
data = io.imread(path,as_grey=True)
print(data.shape)
data = np.mat(data) # 需要mat处理后才能在降维中使用矩阵的相乘
U, sigma, VT = np.linalg.svd(data)
count = 30 # 选择前30个奇异值
# 重构矩阵
dig = np.diag(sigma[:count]) # 获得对角矩阵
# dim = data.T * U[:,:count] * dig.I # 降维 格外变量这里没有用 dig.I:是求dig的逆矩阵
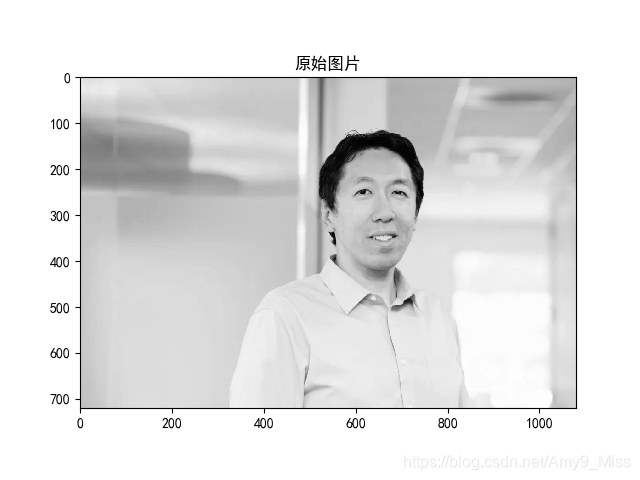
redata = U[:, :count] * dig * VT[:count, :] # 重构后的数据plt.imshow(data, cmap='gray') # 取灰
plt.title("原始图片")
plt.show()
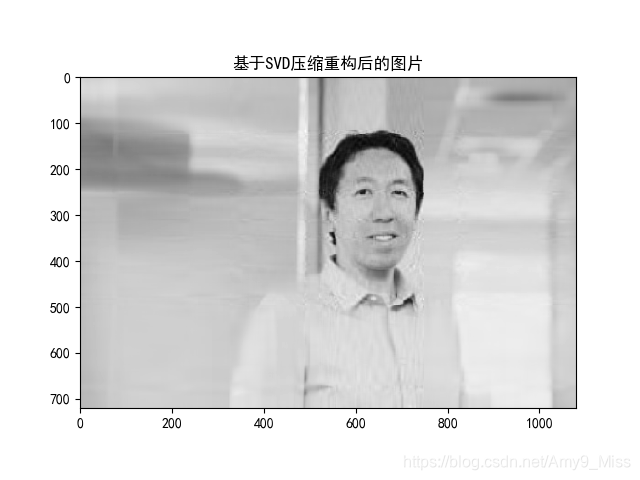
plt.imshow(redata, cmap='gray') # 取灰
plt.title("基于SVD压缩重构后的图片")
plt.show()原图片为720x1080,保存像素点值为720x1080 = 777600,使用SVD算法,取前30个奇异值则变为(720+1+1080)*30=54030,达到了几乎15倍的压缩比,极大的减少了存储量。
结果如下
附录
方阵
方阵:是一种特殊的矩阵。方阵是n*n的矩阵
特征值和特征向量
设A是n阶方阵,若存在n维非零向量 v ⃗ \vec v v,使得
A v ⃗ = λ v ⃗ A\vec{v}=\lambda \vec{v} Av=λv
则称常数 λ \lambda λ为A的特征值, v ⃗ \vec v v为A的对应于 λ \lambda λ的特征向量。
np.diag()
np.diag(array)参数说明:
array是一个1维数组时,结果形成一个以一维数组为对角线元素的矩阵;
array是一个二维矩阵时,结果输出矩阵的对角线元素
import numpy as np# 输入是1维数组时,结果形成一个以一维数组为对角线元素的矩阵
data_1 = np.array([1,2,3])
print("输入是1维数组时的结果:\n",np.diag(data_1))# 输入是二维矩阵时,结果输出矩阵的对角线元素
data_2 = np.array([[1,0,4],[2,2,0],[0,0,5]])
print("输入是2维数组时的结果:\n",np.diag(data_2))
运行结果
输入是1维数组时的结果:[[1 0 0][0 2 0][0 0 3]] 输入是2维数组时的结果:[1 2 5]
相关链接
SVD分解原理
机器学习实战–SVD
机器学习实战——SVD(奇异值分解)