微信公众号
关键字全网搜索最新排名
【机器学习算法】:排名第一
【机器学习】:排名第一
【Python】:排名第三
【算法】:排名第四
前言
奇异值分解(Singular Value Decomposition,简称SVD)是在机器学习领域广泛应用的算法,它不光可以用于降维算法中的特征分解,还可以用于推荐系统,以及自然语言处理等领域,是很多机器学习算法的基石。本文就对SVD的原理做一个总结,并讨论在在PCA降维算法中是如何运用运用SVD的。
特征值与特征向量
首先回顾下特征值和特征向量的定义如下:
Ax=λx
其中A是一个n×n的矩阵,x是一个n维向量,则我们说λ是矩阵A的一个特征值,而x是矩阵A的特征值λ所对应的特征向量。
求出特征值和特征向量有什么好处呢? 我们可以将矩阵A特征分解。如果我们求出了矩阵A的n个特征值λ1≤λ2≤...≤λn,以及这n个特征值所对应的特征向量{w1,w2,...wn},那么矩阵A就可以用下式的特征分解表示:
A=WΣW^−1
其中W是这n个特征向量所张成的n×n维矩阵,而Σ为这n个特征值为主对角线的n×n维矩阵。一般会把W的这n个特征向量标准化,即满足||wi||^2=1, 或者说wi^Twi=1,此时W的n个特征向量为标准正交基,满足W^TW=I,即W^T=W^−1, 也就是说W为酉矩阵。这样特征分解表达式可以写成
A=WΣW^T
注意到要进行特征分解,矩阵A必须为方阵。那么如果A不是方阵,即行和列不相同时,我们还可以对矩阵进行分解吗?
SVD定义
SVD也是对矩阵进行分解,但和特征分解不同,SVD并不要求要分解的矩阵为方阵。假设矩阵A是一个m×n的矩阵,那么我们定义矩阵A的SVD为:
A=UΣV^T
其中U是一个m×m的矩阵,Σ是一个m×n的矩阵,除了主对角线上的元素以外全为0,主对角线上的每个元素都称为奇异值,V是一个n×n的矩阵。U和V都是酉矩阵,即满足U^TU=I,V^TV=I。下图可以很形象的看出上面SVD的定义:
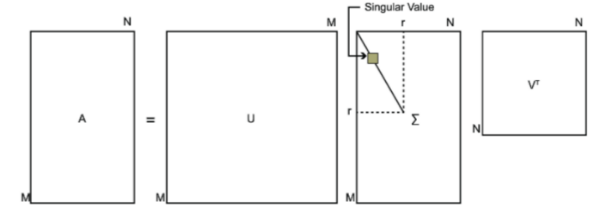
那么如何求出SVD分解后的U,Σ,V这三个矩阵呢?