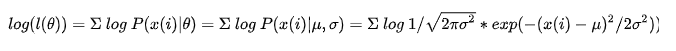更多干货内容,请移步公众号:隐语的小剧场
一、引言
本文针对联邦学习中遇到的Non-IID问题进行探讨,介绍Non-IID产生的原因,分析Non-IID对联邦学习的影响,以及调研了近年来针对该问题的解决方案,并进行分类总结。
1.1背景介绍
在联邦学习中,拥有不同数据集的client进行联合训练。根据本系列之前的文章《联邦学习之基本方法》可知,由于client数据集所对应的样本不同,样本所处地域可能不同,以及数据采集的时间窗口不同等原因,因此多个client在进行联合联邦训练时,这些数据集之间往往具有不同的特征分布或标签分布,同时特征之间并非相互独立,联邦学习中的这种场景被称之为非独立同分布(Non-IID(Identically and Independently Distributed))场景 [1]。
1.2Non-IID的影响
通过ATA《联邦学习之基本方法》可知,FedAVG基于独立同分布假设进行联合建模训练,因此对于Non-IID的client数据集,直接进行模型聚合往往影响模型的整体性能 [2],此外全局统一的模型无法实现对各个client数据的个性化表征 [3]。我们分别从定量和定性两个角度,具体分析Non-IID数据集对FedAVG算法的影响。
定性分析 [4]
首先我们通过一个简单的分类任务来分析一下Non-IID对模型训练的影响。如图1(a)左图所示,我们有四个样本,每个样本包含两个特征和一个标签(x0,x1,label):样本1(6,2,+)、样本2(6,6,-)、样本3(2,2,-),样本4(2,6,+)。在中心化训练中,可以很容易的根据特征x0,x1的取值范围进行分类,如图1(a)右图所示。
假设在联邦学习中,样本2和样本4在client1中,样本1和样本3在client2中,数据分布为Non-IID。在client进行本地训练时,根据特征x0,x1的取值范围进行分类,得到对应的分类模型。如图1(b)所示,client1和client2的分类模型成完全相反的预测结果,因此联邦训练的聚合模型在对应区域相互抵消,模型性能必然很差。

图1Non-IID 分类简化模型
(2)定量分析 [5]

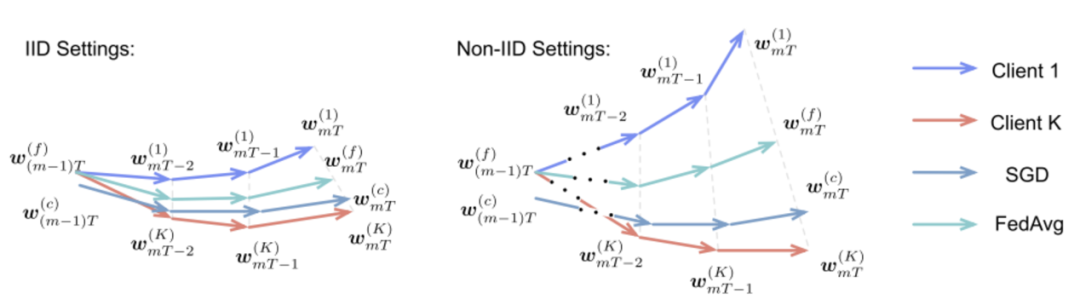
图2IID与Non-IID数据集收敛示意图
联邦训练模型与中心训练模型的差异可由下面公示表示:
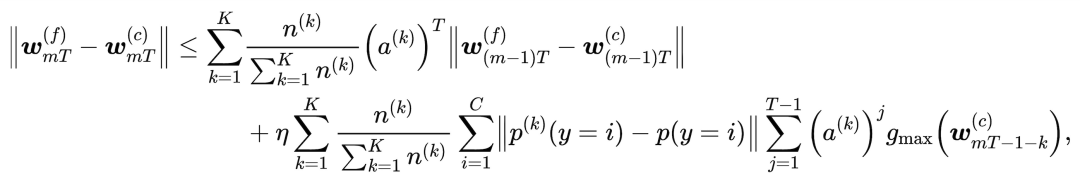
其中
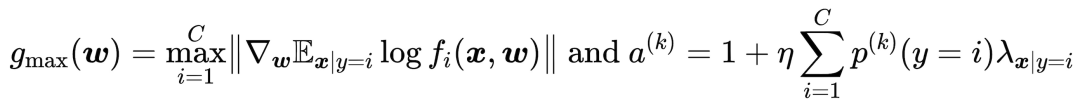
- 推论1
二者的差异主要由两部分组成:一部分是模型在上次训练时的差异,另一部分是由clientk的分布与整体分布差异引起的。
- 推论2
所有client进行相同的模型初始化有助于减少联邦训练模型与中心训练模型之间的差异。
- 推论3
当采用相同的初始化模型时,联邦训练模型与中心训练模型的差异主要由数据分布差异引起,具体的大小还与学习率_η_联邦训练每次更新时client端训练迭代次数T和梯度_g__max__有关。_
二、优化方法
近年来,针对联邦学习Non-IID问题的研究越来越多,我们调研了最近几年的相关paper发现,目前的算法优化主要分为三个方向:数据优化、模型更新优化和模型训练优化。
2.1数据优化
基于数据的优化算法直接针对数据分布进行优化,使得client的数据分布与整体数据分布尽可能相似。具体方法如下:首先利用公开数据集或者client脱敏部分本地数据,在server端生成一个公共数据集;然后server将部分数据集下发到client中,与client原数据进行混合,从而使得各个client端的数据分布尽可能相似,从而降低Non-IID对于模型整体性能的影响 [5][6]。
该方法虽然在一定程度上降低了client之间分布的差异性,但是却在各个参数方之间进行样本数据的共享,会造成隐私数据的泄漏,使用场景受限,近年来该方向的研究越来越少。
2.2模型更新优化
基于模型更新的优化算法针对联邦学习中client端的模型更新过程和server端的模型聚合过程进行优化:
(1)优化client模型更新算法
ASFGNN [7]根据client和server端的样本分布得到对应的JS散度,并以JS散度作为client端模型更新时的权重系数,如下面公式所示,其中P和Q分别为client和server端的样本分布:
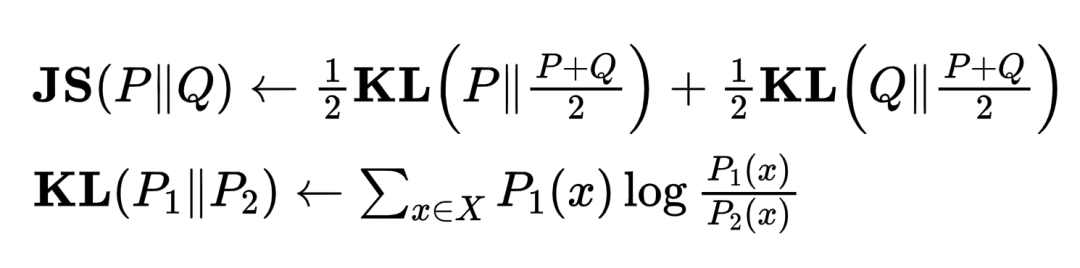
在每次联邦训练的round中,对server端模型和client端模型进行加权平均,更新模型参数:
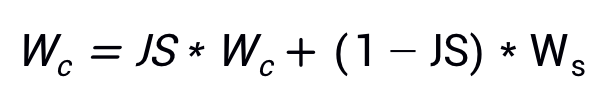
APFL [8]在每次联邦训练round中根据client端模型和server端模型的差异,对权重系数进行迭代更新,然后采用与ASFGNN中类似的方法对client端的个性化模型进行加权平均,如下面公式所示。
Personalized model:
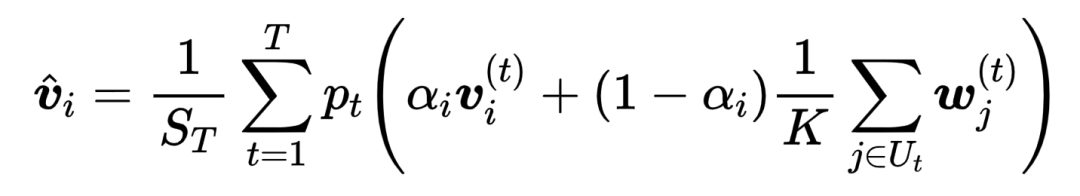
Global model:
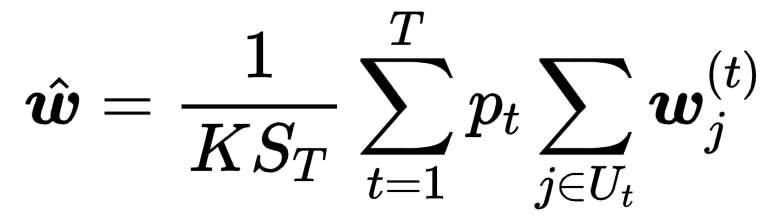
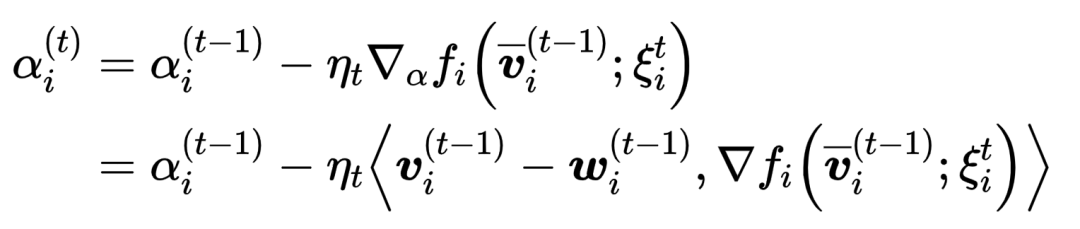
(2)优化模型聚合算法
FedAT [9]根据网络延迟和网络通信情况,将参与的client分成多组,每组内部进行同步联邦学习,得到该组的聚合模型;不同组之间进行异步联邦学习,依次更新server模型,更新次数越少的组,更新系数越大。
Semi-FL [10]对client分成多组,每组内部进行串行方式的训练;在每组中对client模型按照编号进行依次训练,当前模型的初始模型为上个模型训练后更新的模型;每组最后一个client输出模型为该组上传至server端进行聚合的模型,如图3所示。除此之外还有其他几种动态分组联邦训练的方法,例如FedFMC [11]等。
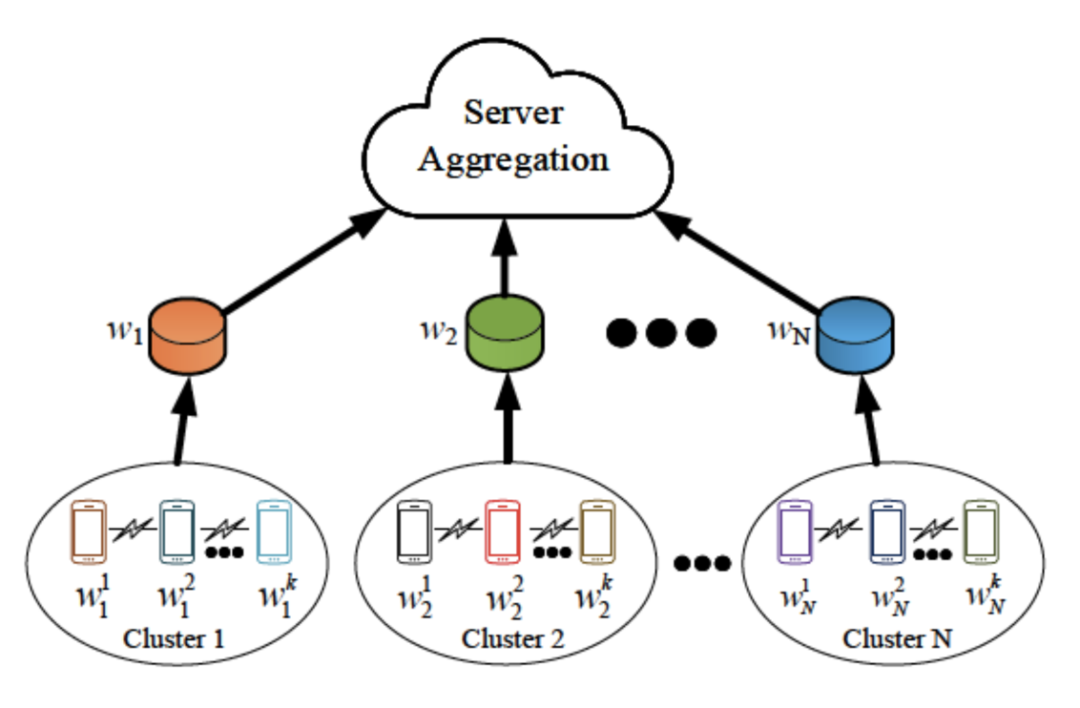
图3Semi-FL 算法架构图
FedCD [12]在进行server端模型聚合时,将client模型在client验证集上的score而非样本数量作为该模型的权重进行聚合。
TfdpFL [13]提供了一些偏实用性的问题解决方法,对于TOC场景下的实际落地有一定的参考价值。例如部分成员没有完成全部本地训练轮数是否参与聚合过程,不活跃成员是否需要从联邦训练中移除,client离线又恢复如何处理,训练过程中有新加入的client如何处理等问题。
**(3)**多模型优化算法
LG-FedAVG [17]、APFL [8]在client端创建多个模型,分别进行本地训练和联邦训练,从而实现联邦聚合的统一性与client模型的个性化表征。
2.3模型训练优化
基于模型训练的优化算法针对client端的模型训练过程进行优化,主要分为如下几种:
(1)优化机器学习模型
FedProx [14]在原始的loss函数中增加模型差异的l2norm,限制client端模型和server模型的差异,如下面公式所示。
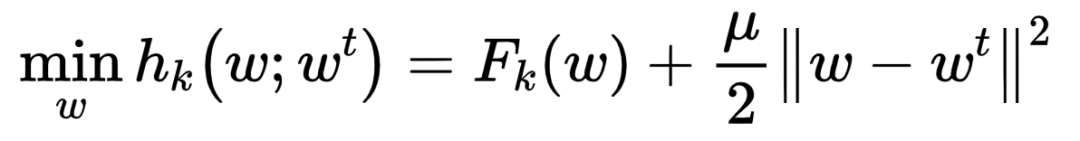
FedMo [15]参考动量梯度下降算法,将client模型上传至server中,并在server对进行动量累加,利用动量更新模型;此外该文章还提供了一种改进算法,对client梯度中各个元素位置的符号进行累加,小于某个门限值则将该元素的学习率设为0,否则依然为原始学习率,如下面公式所示。
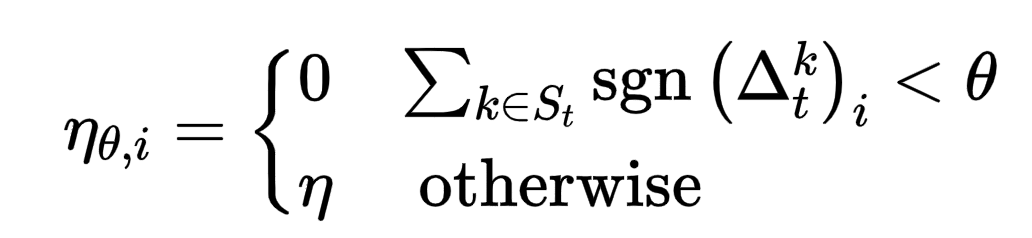
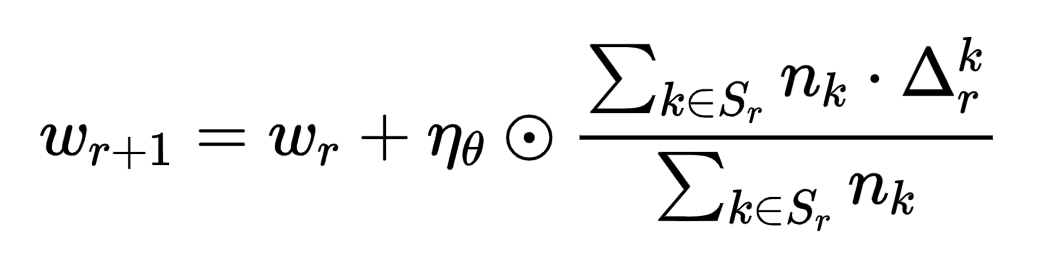
(2)部分联邦训练
ASFGNN [7]将GNN模型中前面的embedding层在client本地进行训练更新,表征client本地数据的个性化信息,后面的预测层进行联邦学习,如图4所示。
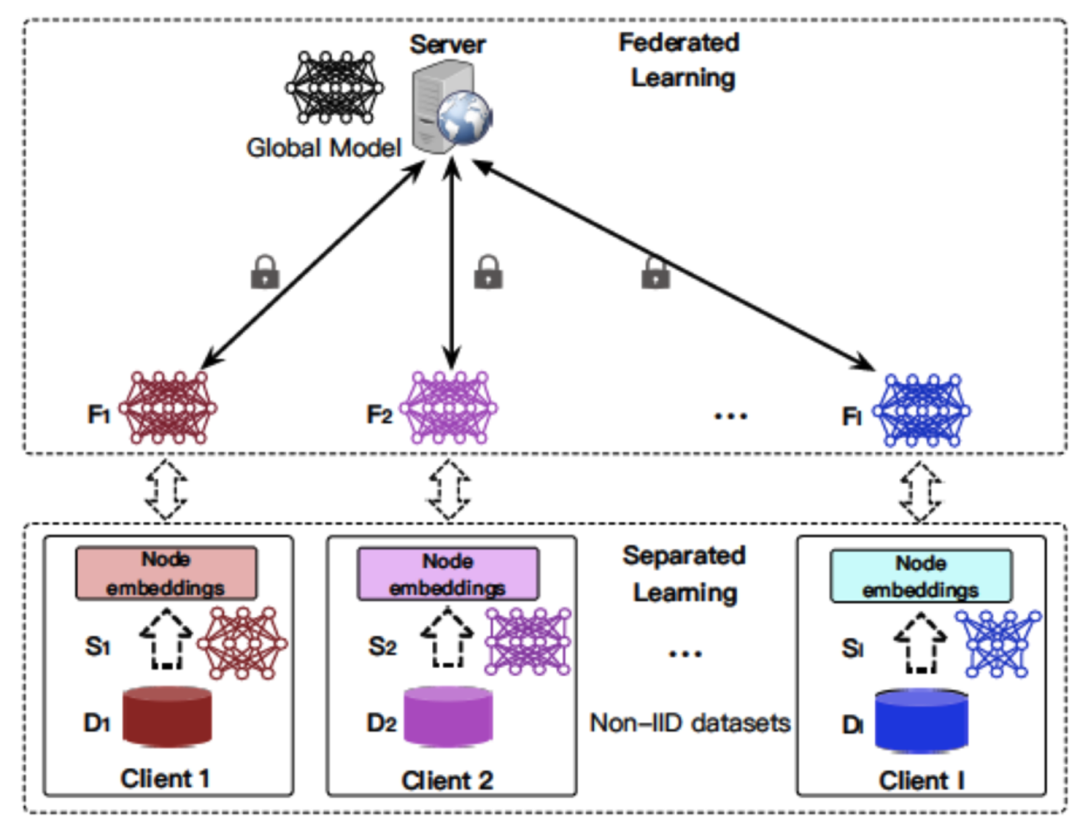
图4SFGNN算法架构图
FedPer [16]针对计算机视觉的应用场景,提出将模型前面的部分层作为基础层进行联邦训练更新,剩余后面的层作为个性化层进行本地训练更新。
(3)Meta-learning
[18] [19] [20]等文献中将meta-learning与联邦学习进行结合,从而实现对client模型的个性化学习,有兴趣的同学可以结合这几篇文献进行深入了解。
三、结语
后续我们会根据逐渐涌现出来的新方法,在本公众号“隐语的小剧场”更新文章,为算法研究和业务落地提供新的参考方向,欢迎探讨交流。
Reference
[1] KairouzP, McMahan H B, Avent B, et al. Advances and open problems infederated learning[J]. arXiv preprint arXiv:1912.04977, 2019.
[2] LiT, Sahu A K, Zaheer M, et al. Federated optimization in heterogeneousnetworks[J]. arXiv preprint arXiv:1812.06127, 2018.
[3] HuangY, Chu L, Zhou Z, et al. Personalized federated learning: Anattentive collaboration approach[J]. arXiv preprint arXiv:2007.03797,2020.
[4] SafaOzdayi M, Kantarcioglu M, Iyer R. Improving Accuracy of FederatedLearning in Non-IID Settings[J]. arXiv e-prints, 2020: arXiv:2010.15582.
[5]ZhaoY, Li M, Lai L, et al. Federated learning with non-iid data[J]. arXivpreprint arXiv:1806.00582, 2018.
[6] WangT, Zhu J Y, Torralba A, et al. Dataset distillation[J]. arXivpreprint arXiv:1811.10959, 2018.
[7] ZhengL, Zhou J, Chen C, et al. ASFGNN: Automated separated-federated graphneural network[J]. Peer-to-Peer Networking and Applications, 2021:1-13.
[8] DengY, Kamani M M, Mahdavi M. Adaptive personalized federatedlearning[J]. arXiv preprint arXiv:2003.13461, 2020.
[9] ChaiZ, Chen Y, Zhao L, et al. Fedat: A communication-efficient federatedlearning method with asynchronous tiers under non-iid data[J]. arXivpreprint arXiv:2010.05958, 2020.
[10] ChenZ, Li D, Zhao M, et al. Semi-Federated Learning[C]//2020 IEEEWireless Communications and Networking Conference (WCNC). IEEE, 2020:1-6.
[11] KopparapuK, Lin E. FedFMC: Sequential Efficient Federated Learning on Non-iidData[J]. arXiv preprint arXiv:2006.10937, 2020.
[12] KopparapuK, Lin E, Zhao J. FedCD: Improving Performance in non-IID FederatedLearning[J]. arXiv preprint arXiv:2006.09637, 2020.
[13] RuanY, Zhang X, Liang S C, et al. Towards flexible device participationin federated learning for non-iid data[J]. arXiv preprintarXiv:2006.06954, 2020.
[14] LiT, Sahu A K, Zaheer M, et al. Federated optimization in heterogeneousnetworks[J]. arXiv preprint arXiv:1812.06127, 2018.
[15] OzdayiM S, Kantarcioglu M, Iyer R. Improving Accuracy of Federated Learningin Non-IID Settings[J]. arXiv preprint arXiv:2010.15582, 2020.
[16] ArivazhaganM G, Aggarwal V, Singh A K, et al. Federated learning withpersonalization layers[J]. arXiv preprint arXiv:1912.00818, 2019.
[17] LiangP P, Liu T, Ziyin L, et al. Think locally, act globally: Federatedlearning with local and global representations[J]. arXiv preprintarXiv:2001.01523, 2020.
[18] ChenF, Luo M, Dong Z, et al. Federated meta-learning with fastconvergence and efficient communication[J]. arXiv preprintarXiv:1802.07876, 2018.
[19] FallahA, Mokhtari A, Ozdaglar A. Personalized federated learning: Ameta-learning approach[J]. arXiv preprint arXiv:2002.07948, 2020.
[20] ZhangX, Hong M, Dhople S, et al. FedPD: A federated learning frameworkwith optimal rates and adaptivity to non-IID data[J]. arXiv preprintarXiv:2005.11418, 2020.
隐语官网:
https://secret-flow.antgroup.com
隐语社区:
https://github.com/secretflow
https://gitee.com/secretflow
联系我们:
公众号:隐语的小剧场
B站:隐语secretflow
邮箱:secretflow-contact@service.alipay.com