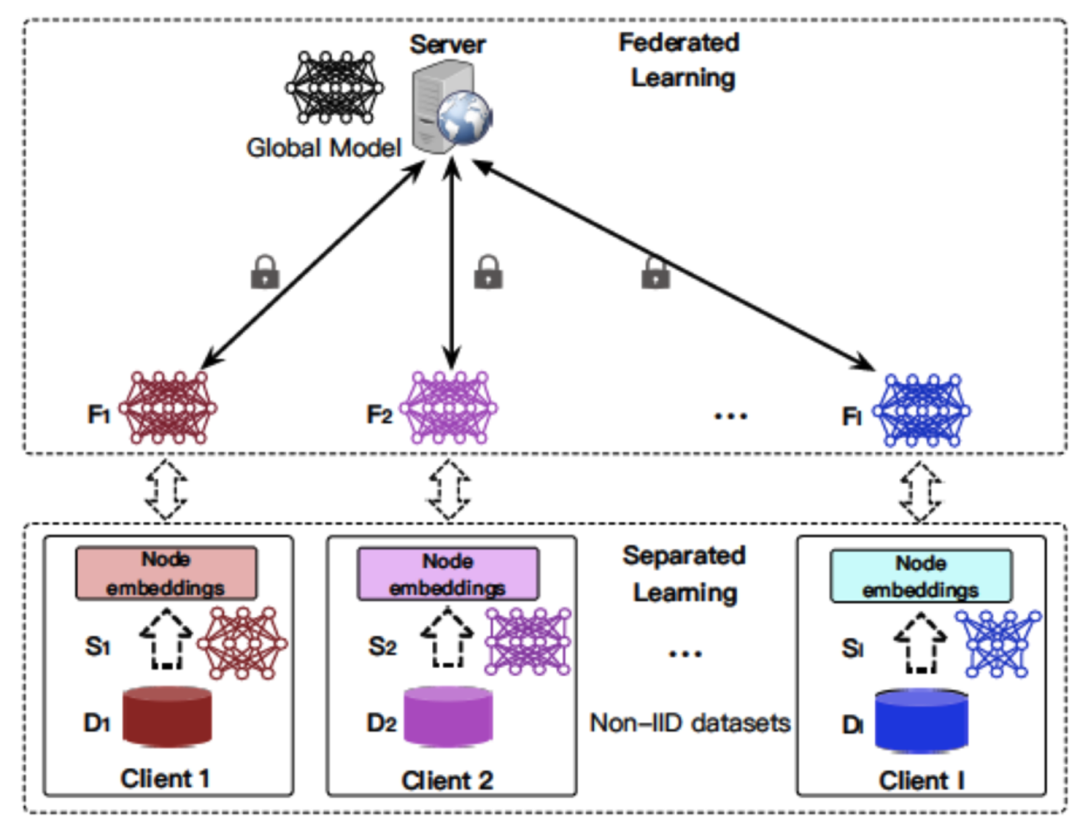
在这篇blog中我们一起来阅读一下 On the convergence of FedAvg on non-iid data 这篇 ICLR 2020 的paper.
主要目的
本文的主要目的是证明联邦学习算法的收敛性。与之前其他工作中的证明不同,本文的证明更贴近于实际联邦学习的场景。特别的,
- 所有用户的数据non-iid分布;
- 每次只有一部分用户参与FedAvg.
系统模型
考虑一个联邦学习系统 with N N N 用户和一个PS. 每用户有一些local data,训练发生在用户处,每隔一段时间用户上传自己学习的模型来做FedAvg.
将第 k k k 个用户的数据记为 x = { x k , 1 , x k , 2 , x k , 3 , . . . , x k , n k } \bm{x}=\{x_{k,1},x_{k,2},x_{k,3},...,x_{k,n_k}\} x={xk,1,xk,2,xk,3,...,xk,nk}, 每个人都有一个学习目标,即最小化 loss 函数
F k ( w ) = ∑ j = 1 n k ℓ k ( w , x k , j ) (1) F_k(\bm{w})=\sum_{j=1}^{n_k}\ell_k(\bm{w},x_{k,j}) \tag{1} Fk(w)=j=1∑nkℓk(w,xk,j)(1)
其中 ℓ k ( w , x k , j ) \ell_k(\bm{w},x_{k,j}) ℓk(w,xk,j) 是每个训练数据的 loss. F k ( w ) F_k(\bm{w}) Fk(w) 相当于是每个人所有数据上的loss,如果仅仅做local training, 那最终每个用户会 arrive at
Local minimum : F k ∗ = min w F k \text{Local minimum}:~~~~F_k^*=\min_{\bm{w}} F_k Local minimum: Fk∗=wminFk
而FL考虑的是一种分布式的优化,即我们要minimize的目标函数
Global minimum : F ∗ = min w ∑ k = 1 N p k F k ( w ) \text{Global minimum}:~~~~F^*=\min_{\bm{w}} \sum_{k=1}^{N} p_k F_k(\bm{w}) Global minimum: F∗=wmink=1∑NpkFk(w)
其中 p k p_k pk 是一个distribution用来表示每个用户所占的权重。换句话说,我们最终想找到一个共同的 w \bm{w} w 来最小化每个用户 loss 的一个加权和。
To this end, 本文考虑FedAvg, 并证明其能收敛到 global optimum.
FedAvg 的具体步骤描述如下:首先,我们按单次SGD为一个时间刻度把时间轴分为离散的slot t = 1 , 2 , 3 , . . . , T t=1,2,3,...,T t=1,2,3,...,T, 即总共进行 T T T 次 local SGD, 每次 SGD每个用户从自己的数据集中随机均匀的采样出一个数据来进行训练。特别的,每隔 E E E slots, 所有 active users 把自己的本地参数发送给PS进行 FedAvg,之后PS会把avg后的参数发还给各个用户。以上模型用数学语言可以写为以下两步:
Local training
每个用户在第 t t t 个时刻基于 w t k \bm{w}^k_t wtk 进行 SGD, 得到
v t + 1 k = w t k − η t ∇ ℓ k ( w t k , ξ t k ) (2) \bm{v}^k_{t+1}=\bm{w}^k_t-\eta_{t}\nabla \ell_k(\bm{w}^k_t,\xi^k_t) \tag{2} vt+1k=wtk−ηt∇ℓk(wtk,ξtk)(2)
其中 ξ t k \xi^k_t ξtk 是从本地数据中随机采样出的一个sample。注意,这样单步SGD得到的 v t + 1 k \bm{v}^k_{t+1} vt+1k 只是一个中间变量而不是下一时刻的 w t + 1 k \bm{w}^k_{t+1} wt+1k,因为我们还有可能做 FedAvg。 更具体地说,在 E E E 的非整数倍slot上,
w t + 1 k = v t + 1 k , if t + 1 ∉ J E = { n E : n = 1 , 2 , . . . } . \bm{w}^k_{t+1}=\bm{v}^k_{t+1},~~~~\text{if}~~t+1\notin\mathcal{J}_E=\{nE:n=1,2,...\}. wt+1k=vt+1k, if t+1∈/JE={nE:n=1,2,...}.
而在 E E E 的整数倍slot上,我们还得额外做 FedAvg.
FedAvg
若下一时刻是 E E E的整数倍周期,即 t + 1 ∈ J E = { n E : n = 1 , 2 , . . . } t+1\in\mathcal{J}_E=\{nE:n=1,2,...\} t+1∈JE={nE:n=1,2,...},我们进行FedAvg,此时
w t + 1 k = ∑ k = 1 N p k v t + 1 k (3) \bm{w}^k_{t+1}=\sum_{k=1}^N p_k \bm{v}^k_{t+1} \tag{3} wt+1k=k=1∑Npkvt+1k(3)
注意,这里面我们假设每个人都参与更新,稍后我们会release这个条件允许PS按照某种分布采样一部分人进行更新。
小结
如果我们从每个用户的角度看,它的参数变化可以用下图归纳 ( E = 3 E=3 E=3)。

几个假设
本文的推导基于以下假设。
Assumption 1 ( L L L-smoothness). 所有用户的 loss 函数 { F k : k = 1 , 2 , . . . , N } \{F^k:k=1,2,...,N\} {Fk:k=1,2,...,N} 都是 L-smooth.
F k ( x 2 ) − F k ( x 1 ) ≤ ∇ f ( x 1 ) ⊤ ( x 2 − x 1 ) + L 2 ∥ x 2 − x 1 ∥ 2 F^k(\bm{x_2})-F^k(\bm{x_1})\leq \nabla f(\bm{x_1})^\top (\bm{x_2-x_1}) + \frac{L}{2}\|\bm{x_2-x_1}\|^2 Fk(x2)−Fk(x1)≤∇f(x1)⊤(x2−x1)+2L∥x2−x1∥2
Assumption 2 ( μ \mu μ-strongly convex). 所有用户的 loss 函数 { F k : k = 1 , 2 , . . . , N } \{F^k:k=1,2,...,N\} {Fk:k=1,2,...,N} 都是 μ \mu μ-strongly convex.
F k ( x 2 ) − F k ( x 1 ) ≥ ∇ f ( x 1 ) ⊤ ( x 2 − x 1 ) + μ 2 ∥ x 2 − x 1 ∥ 2 F^k(\bm{x_2})-F^k(\bm{x_1})\geq \nabla f(\bm{x_1})^\top (\bm{x_2-x_1}) + \frac{\mu}{2}\|\bm{x_2-x_1}\|^2 Fk(x2)−Fk(x1)≥∇f(x1)⊤(x2−x1)+2μ∥x2−x1∥2
以上两个假设对 loss 函数的基本性质做了一些要求。即,函数变化的速度不会太快 ( L L L-smooth) 也不会太慢 ( μ \mu μ-strongly convex). 这两个假设下函数更详细的属性可参考 [1]. 等下证明时用到了哪个定义或者属性我们会再提及。
一般文献用这两个定义的原因是,我们可以把 bound " F F F 和最优 F ∗ F^* F∗ 之间距离" 的问题转化为 bound " w w w 和最优 w ∗ \bm{w}^* w∗ 之间距离" 的问题。即,只要明确了 w w w 和 w ∗ \bm{w}^* w∗ 之间距离,就可以相应的把 F F F 和 F ∗ F^* F∗ 之间的距离大概确定。
Assumption 3 (bounded variance of the stochastic gradients). 每个用户进行 SGD 时,其均匀采样的sample的随机梯度的 variance is bounded by σ k 2 \sigma^2_k σk2:
E ∥ ∇ ℓ k ( w k , ξ k ) − ∇ F k ( w ) ∥ 2 ≤ σ k 2 \mathbb{E}\| \nabla \ell_k(\bm{w}^k,\xi^k) - \nabla F^k(\bm{w}) \|^2\leq \sigma^2_k E∥∇ℓk(wk,ξk)−∇Fk(w)∥2≤σk2
Assumption 4 (bounded stochastic gradient). 每个用户的随机梯度的模值也是bounded:
E ∥ ∇ ℓ k ( w k , ξ k ) ∥ 2 ≤ G 2 \mathbb{E}\| \nabla \ell_k(\bm{w}^k,\xi^k) \|^2\leq G^2 E∥∇ℓk(wk,ξk)∥2≤G2
Full device participation
一些定义
作者首先证明了 FedAvg 在所有用户共同参与下的收敛性。
首先,基于上图 v k \bm{v}^k vk 和 w k \bm{w}^k wk 两个序列,我们定义两个虚拟序列
v ˉ t = ∑ k = 1 N p k v t k , w ˉ t = ∑ k = 1 N p k w t k . \bar{\bm{v}}_t=\sum_{k=1}^N p_k \bm{v}^k_{t},~~~~~~~~\bar{\bm{w}}_t=\sum_{k=1}^N p_k \bm{w}^k_{t}. vˉt=k=1∑Npkvtk, wˉt=k=1∑Npkwtk.
实际上这两个序列是 v k \bm{v}^k vk 和 w k \bm{w}^k wk 自身在所有用户上的加权和。特别的, v ˉ t = w ˉ t \bar{\bm{v}}_t =\bar{\bm{w}}_t vˉt=wˉt, 因为在非 n E nE nE slot他们完全相等,在 n E nE nE slot, 所有人的 w n E k \bm{w}^k_{nE} wnEk 都是相等的且等于 v ˉ n E \bar{\bm{v}}_{nE} vˉnE, 即
w n E 1 = w n E 2 = . . . = w n E N = w ˉ n E = v ˉ n E \bm{w}^1_{nE}=\bm{w}^2_{nE}=...=\bm{w}^N_{nE}=\bar{\bm{w}}_{nE}=\bar{\bm{v}}_{nE} wnE1=wnE2=...=wnEN=wˉnE=vˉnE.
而且,我们还可以把连续的两个 slots t t t 和 t + 1 t+1 t+1 联系起来,因为我们知道
v t + 1 k = w t k − η t ∇ ℓ ( w t k , ξ t k ) (4) \bm{v}^k_{t+1}=\bm{w}^k_{t} - \eta_t \nabla \ell(\bm{w^k_t}, \xi^k_t) \tag{4} vt+1k=wtk−ηt∇ℓ(wtk,ξtk)(4)
定义单次SGD每个用户 gradient 的加权和
g t = ∑ k = 1 N p k ∇ ℓ ( w t k , ξ t k ) (5) \bm{g}_t=\sum_{k=1}^{N}p_k \nabla\ell(\bm{w^k_t}, \xi^k_t) \tag{5} gt=k=1∑Npk∇ℓ(wtk,ξtk)(5)
和单次steepest gradient descent (使用所有data) 每个用户 gradient 的加权和
g ˉ t = ∑ k = 1 N p k ∇ F k ( w t ) = ∑ k = 1 N p k 1 n k ∑ j = 1 n k ∇ ℓ ( w t k , x k , j ) = E [ g t ] (6) \bar{\bm{g}}_t=\sum_{k=1}^{N}p_k \nabla F^k(\bm{w_t}) =\sum_{k=1}^{N}p_k \frac{1}{n_k}\sum_{j=1}^{n_k}\nabla \ell(\bm{w^k_t}, x_{k,j}) =\mathbb{E} [\bm{g}_t] \tag{6} gˉt=k=1∑Npk∇Fk(wt)=k=1∑Npknk1j=1∑nk∇ℓ(wtk,xk,j)=E[gt](6)
其中 E \mathbb{E} E averages over 所有用户选择的sample。
给定 g t \bm{g}_t gt, 我们可以把 (4) 两边用 p k p_k pk 加权和
v ˉ t + 1 = w ˉ t − η t g t (7) \bar{\bm{v}}_{t+1}=\bar{\bm{w}}_{t} - \eta_t \bm{g}_t \tag{7} vˉt+1=wˉt−ηtgt(7)
Lemmas
我们跟随作者的思路,先证明一些 lemmas.
Lemma 1 (Results of one-step SGD). Assuming assumptions 1 and 2. If η t ≤ 1 4 L \eta_t\leq \frac{1}{4L} ηt≤4L1, we have
E ∥ v ˉ t + 1 − w ∗ ∥ 2 ≤ ( 1 − η t μ ) E ∥ w ˉ t − w ∗ ∥ 2 + η t 2 E ∥ g t − g ˉ t ∥ 2 + 6 L η t 2 Γ + 2 E ∑ k = 1 N p k ∥ w ˉ t − w k t ∥ 2 (8) \mathbb{E}\|\bar{\bm{v}}_{t+1}-\bm{w}^* \|^2 \leq (1-\eta_t\mu)\mathbb{E}\|\bar{\bm{w}}_t-\bm{w}^* \|^2 + \eta^2_t\mathbb{E}\|\bm{g}_t-\bar{\bm{g}}_t \|^2+6L\eta^2_t\Gamma+2\mathbb{E}\sum_{k=1}^N p_k\|\bar{\bm{w}}_t-\bm{w}^t_k\|^2 \tag{8} E∥vˉt+1−w∗∥2≤(1−ηtμ)E∥wˉt−w∗∥2+ηt2E∥gt−gˉt∥2+6Lηt2Γ+2Ek=1∑Npk∥wˉt−wkt∥2(8)where Γ = F ∗ − ∑ k = 1 N p k F k ∗ ≥ 0 \Gamma=F^*-\sum_{k=1}^{N} p_k F^*_k\geq 0 Γ=F∗−∑k=1NpkFk∗≥0.
Lemma 1 显然是很重要的,理解它对于后面的证明大有帮助。我们首先来看看其中的变量. 在某个slot t t t,
- 每个用户的参数为 w t k \bm{w}^k_t wtk, 平均参数为 w ˉ t \bar{\bm{w}}_t wˉt (averaged over all users).
- 每个用户SGD更新的方向是 ∇ ℓ ( w t k , ξ t k ) \nabla\ell(\bm{w^k_t},\xi^k_t) ∇ℓ(wtk,ξtk), 平均方向是 g t k \bm{g}^k_t gtk (averaged over all users), 再 average over all data 的平均方向是 g ˉ t \bar{\bm{g}}_t gˉt.
- 每个用户更新完后得到 v t + 1 k \bm{v}^k_{t+1} vt+1k, 平均参数是 v ˉ t + 1 \bar{v}_{t+1} vˉt+1 (averaged over all users).
因此,如果 E = 1 E=1 E=1 即每个时刻都做 FedAvg 的话,global 参数的演变历程其实就是 w ˉ t \bar{\bm{w}}_t wˉt 沿着 g t \bm{g}_t gt 的方向演变成 v ˉ t + 1 \bar{v}_{t+1} vˉt+1 的过程:
w ˉ t + 1 = v ˉ t + 1 = ∑ k = 1 N p k v t + 1 k = ∑ k = 1 N p k ( w t k − η t ∇ ℓ k ) = ∑ k = 1 N p k w t k − η t ∑ k = 1 N p k ∇ ℓ k = w ˉ t − η t g t \bar{\bm{w}}_{t+1}=\bar{\bm{v}}_{t+1}=\sum_{k=1}^{N}p_k\bm{v}^k_{t+1}=\sum_{k=1}^{N}p_k(\bm{w}^k_{t}-\eta_t\nabla \ell_k) =\sum_{k=1}^{N}p_k\bm{w}^k_{t}-\eta_t\sum_{k=1}^{N}p_k \nabla \ell_k=\bar{\bm{w}}_{t}-\eta_t{\bm{g}_t} wˉt+1=vˉt+1=k=1∑Npkvt+1k=k=1∑Npk(wtk−ηt∇ℓk)=k=1∑Npkwtk−ηtk=1∑Npk∇ℓk=wˉt−ηtgt
当 E > 1 E>1 E>1 时, 虽然我们并不是在每个时刻 averaging, 但是想象中这个平均的更新轨迹依然存在。而Lemma就是在bound这个平均运动轨迹每次更新后的 v ˉ \bar{\bm{v}} vˉ 与最优参数 w ∗ \bm{w}^* w∗ 的距离。
基于以上的定义,Lemma 1在干什么尼?显然,作者想基于 t t t 时刻的所有信息预测经过一步SGD之后 v ˉ t + 1 \bar{\bm{v}}_{t+1} vˉt+1 与 w ∗ \bm{w}^* w∗ 的距离。这个距离可以用以下4项来bound (分别对应Lemma 1中的4项):
- t t t 时刻,即SGD之前, w ˉ t \bar{\bm{w}}_{t} wˉt 与 w ∗ \bm{w}^* w∗ 的距离;
- 单步SGD的更新方向的variance;
- heterogeneity Γ \Gamma Γ;
- t t t 时刻所有用户参数的variance。
Proof. 整个证明比较tedious,建议理解为重。
为了证明这个bound,我们从 (8) 式左侧开始推:
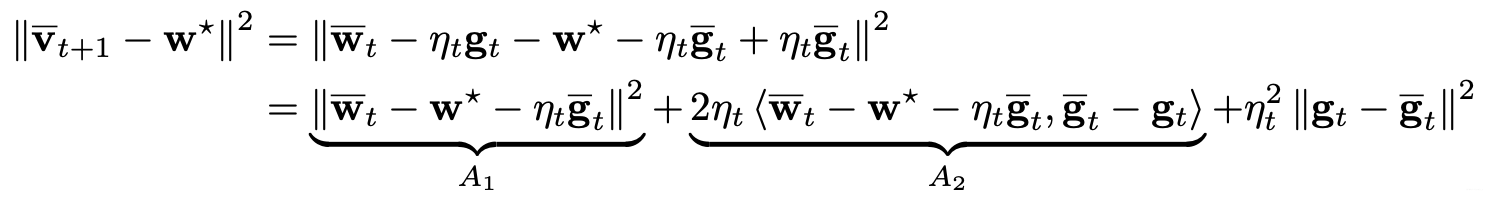
其中第一步直接由定义得出。特别的,作者引入了真实梯度 g ˉ t \bar{\bm{g}}_t gˉt (gradient averaged over users and all data) 来替换掉随机梯度 g t \bm{g}_t gt (stochastic gradient averaged only over users),因为 g ˉ t \bar{\bm{g}}_t gˉt更好处理。第二步由向量模的基本运算得到 (想回顾的同学 [2] 中有)。特别的,因为 E ( g t − g ˉ t ) = 0 \mathbb{E}(\bm{g}_t -\bar{\bm{g}}_t)=0 E(gt−gˉt)=0, 所以中间项 A 2 A_2 A2 的均值为0.
Bound A 1 A_1 A1: A 1 A_1 A1 可以进一步写为
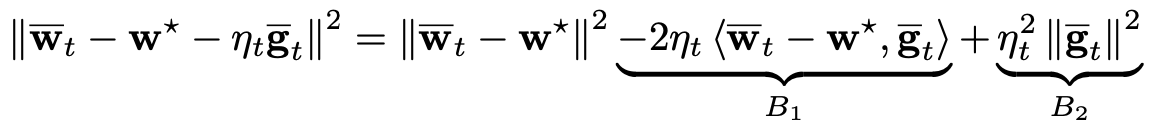
好,我们现在已经成功剥离出上一时刻的 w ˉ t \bar{\bm{w}}_t wˉt 与 w ∗ \bm{w}^* w∗ 的距离了 (即第一项)。接下来继续 bound B 1 {B}_1 B1 and B 2 {B}_2 B2.
Bound B 2 B_2 B2: B 2 B_2 B2 可以写为
η t 2 ∥ g ˉ t ∥ 2 = η t 2 ∥ ∑ k = 1 N p k ∇ F k ( w t k ) ∥ 2 ≤ η t 2 ∑ k = 1 N p k ∥ ∇ F k ( w t k ) ∥ 2 \eta^2_t\|\bar{\bm{g}}_t \|^2 = \eta^2_t\left\| \sum_{k=1}^N p_k \nabla F_k(\bm{w}^k_t) \right\|^2 \leq \eta^2_t \sum_{k=1}^N p_k \left\| \nabla F_k(\bm{w}^k_t) \right\|^2 ηt2∥gˉt∥2=ηt2∥∥∥∥∥k=1∑Npk∇Fk(wtk)∥∥∥∥∥2≤ηt2k=1∑Npk∥∥∇Fk(wtk)∥∥2
因此我们需要 bound ∥ ∇ F k ( w t k ) ∥ 2 \left\| \nabla F^k(\bm{w}^k_t) \right\|^2 ∥∥∇Fk(wtk)∥∥2, 即任意一个用户 loss 函数 (所有数据的loss) 的梯度. 假设1和2中,我们用俩二次函数bound了每个用户loss的梯度 (即 μ \mu μ strongly convex 和 L L L smooth), 这里我们可以用 L L L smoothness 来bound ∥ ∇ F k ( w t k ) ∥ 2 \left\| \nabla F^k(\bm{w}^k_t) \right\|^2 ∥∥∇Fk(wtk)∥∥2.
 此式成立原因见 Definition 4.1 in [1]. 因此, B 2 B_2 B2 可以被 bound 为
此式成立原因见 Definition 4.1 in [1]. 因此, B 2 B_2 B2 可以被 bound 为

Bound B 1 B_1 B1: B 1 B_1 B1 可以写为

这里作者引入一个中间变量 w t k \bm{w}^k_t wtk。这样一来, 我们便可以从分析 w ˉ t − w ∗ \bar{\bm{w}}_t-\bm{w}^* wˉt−w∗ 转变为分析 w ˉ t − w t k \bar{\bm{w}}_t-\bm{w}^k_t wˉt−wtk 和 w t k − w ∗ \bm{w}^k_t-\bm{w}^* wtk−w∗.
TBD.
Lemma 2. Assuming assumption 3, we have
E ∥ g t − g ˉ t ∥ 2 ≤ ∑ k = 1 N p k 2 σ k 2 \mathbb{E}\|\bm{g}_t-\bar{\bm{g}}_t \|^2\leq \sum_{k=1}^{N}p^2_k\sigma^2_k E∥gt−gˉt∥2≤k=1∑Npk2σk2
Lemma 3. Assume assumption 4. If η t \eta_t ηt is non-increasing and η t ≤ 2 η t + E \eta_t\leq 2 \eta_{t+E} ηt≤2ηt+E, then
E ∑ k = 1 N p k ∥ w ˉ t − w k t ∥ 2 ≤ 4 η t 2 ( E − 1 ) 2 G 2 \mathbb{E}\sum_{k=1}^N p_k\|\bar{\bm{w}}_t-\bm{w}^t_k\|^2 \leq 4 \eta^2_t(E-1)^2G^2 Ek=1∑Npk∥wˉt−wkt∥2≤4ηt2(E−1)2G2
Theorem 1: Convergence
将 Lemmas 2, 3 的结果代入 Lemma 1,我们即可得到
E ∥ w ˉ t + 1 − w ∗ ∥ 2 ≤ ( 1 − η t μ ) E ∥ w ˉ t − w ∗ ∥ 2 + η t 2 B (9) \mathbb{E}\|\bar{\bm{w}}_{t+1}-\bm{w}^* \|^2 \leq (1-\eta_t\mu)\mathbb{E}\|\bar{\bm{w}}_t-\bm{w}^* \|^2 + \eta^2_t B \tag{9} E∥wˉt+1−w∗∥2≤(1−ηtμ)E∥wˉt−w∗∥2+ηt2B(9)
其中
B = ∑ k = 1 N p k 2 σ k 2 + 6 L Γ + 8 ( E − 1 ) 2 G 2 B= \sum_{k=1}^{N}p^2_k\sigma^2_k+6L \Gamma+8(E-1)^2G^2 B=k=1∑Npk2σk2+6LΓ+8(E−1)2G2
换句话说,如果我们看 w ˉ t \bar{\bm{w}}_{t} wˉt 这个虚拟序列,它距离最优 w ∗ \bm{w}^* w∗ 的距离可以由 (9) 式 recursively 刻画。那么下面我们唯一需要做的,就是证明这个距离序列是逐渐减小的即可。
令 Δ t = E ∥ w ˉ t − w ∗ ∥ 2 \Delta_{t}=\mathbb{E}\|\bar{\bm{w}}_{t}-\bm{w}^* \|^2 Δt=E∥wˉt−w∗∥2, (9) 式可简写为
Δ t + 1 ≤ ( 1 − η t μ ) Δ t + η t 2 B \Delta_{t+1}\leq (1-\eta_t\mu)\Delta_t +\eta^2_t B Δt+1≤(1−ηtμ)Δt+ηt2B
此式成立的两个条件: 1) η t ≤ 1 4 L \eta_t\leq \frac{1}{4L} ηt≤4L1; 2) η t \eta_t ηt is non-increasing and η t ≤ 2 η t + E \eta_t\leq 2 \eta_{t+E} ηt≤2ηt+E. 下面,我们来选取一组符合这两个条件的 η t \eta_t ηt 来证明 Δ t \Delta_t Δt 是随时间逐渐减小的。
首先,选取 η t = β t + γ \eta_t=\frac{\beta}{t+\gamma} ηt=t+γβ. 它是decreasing的,所以额外两个参数 β , γ \beta,\gamma β,γ 需要确保 η 1 = β 1 + γ ≤ 1 4 L \eta_1=\frac{\beta}{1+\gamma}\leq\frac{1}{4L} η1=1+γβ≤4L1 和 β t + γ < 2 β t + E + γ \frac{\beta}{t+\gamma}<2\frac{\beta}{t+E+\gamma} t+γβ<2t+E+γβ 才行。我们额外还希望 0 < η 1 μ < 1 0<\eta_1\mu<1 0<η1μ<1 这样 Δ t \Delta_t Δt 前的系数就小于 1 1 1 了.
先不给出 β , γ \beta,\gamma β,γ 的具体取值,作者先用归纳法证明
Δ t ≤ v t + γ , v = max { β 2 B β μ − 1 , ( γ + 1 ) Δ 1 } \Delta_t\leq\frac{v}{t+\gamma}, ~~~~v=\max\{\frac{\beta^2 B}{\beta\mu-1},(\gamma+1)\Delta_1\} Δt≤t+γv, v=max{βμ−1β2B,(γ+1)Δ1}
- t = 1 t=1 t=1时,自然成立;
- 假设任意时刻 t t t 成立,则 t + 1 t+1 t+1 时刻
Δ t + 1 ≤ ( 1 − η t μ ) Δ t + η t 2 B \Delta_{t+1}\leq (1-\eta_t\mu)\Delta_t +\eta^2_t B Δt+1≤(1−ηtμ)Δt+ηt2B
Reference
[1] https://blog.csdn.net/Lyn_S/article/details/119706754
[2] https://blog.csdn.net/Lyn_S/article/details/119744549