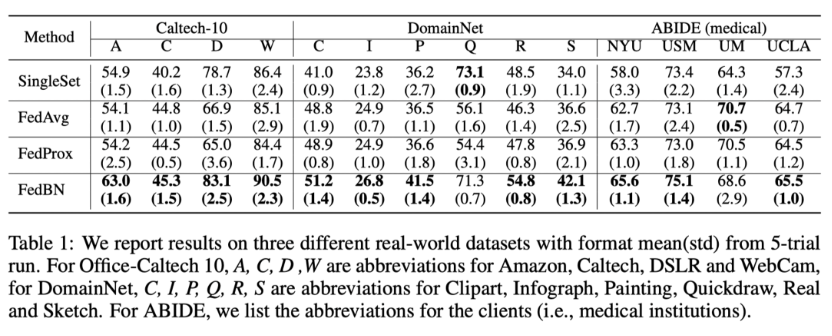
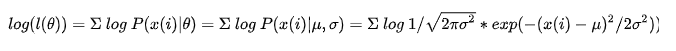本文提出联邦学习中的由于Non-IID数据分布而精度降低是因为权重分散(weight divergence),而权重散度可以用搬土距离(EMD)量化,最后提出了一种策略:通过创建一个在所有边缘设备之间全局共享的数据子集来改进Non-IID数据的训练以此来提高模型精度。。 |
论文地址:Federated Learning with Non-IID Data
联邦学习使资源受限的边缘计算设备(如移动电话和物联网设备)能够学习用于预测的共享模型,同时保持训练数据的本地性。这种分散的训练模型方法提供了隐私、安全、监管和经济效益。在这项工作中,我们关注的是当本地数据是Non-IID时,联邦学习的统计挑战。我们首先看到,对于为高度倾斜的Non-IID数据训练的神经网络来说,联合学习的准确性显著降低,降低高达55%,其中每个客户端设备只对一类数据进行训练。我们进一步证明,这种精度降低可以用权重分散来解释,权重分散可以通过每个设备上的类分布和总体分布之间的搬土距离(EMD)来量化。作为解决方案,我们提出了一种策略,通过创建一个在所有边缘设备之间全局共享的数据子集来改进Non-IID数据的训练。实验表明,对于只有5%的全局共享数据的CIFAR-10数据集,准确率可以提高30%。
文章目录
- 一、introduction
- 二、FedAvg on Non-IID Data
- 三、Weight Divergence due to Non-IID Data
- 1.Mathematical demonstration
- 2 Experimental Validation
- 四、Weight Divergence due to Non-IID Data
一、introduction
近年来,移动设备数量和由这些设备生成的数据大大增加,但是这些数据由于隐私、安全、监管或者经济,这些数据不能传输到服务器。因此提出了联邦学习,使得数据可以在本地进行训练并共享模型。但联邦学习有两个挑战:
1.联邦学习的通信。如如何传递深层网络权值,由网络连通性、功耗和计算限制而导致的意外丢失或同步延迟。
解决办法:开发了一个高效的安全聚合协议,允许服务器从移动设备执行高维数据的计算;提出结构化更新和草图更新,将通信成本降低两个数量级;提出了深度梯度压缩(DGC)将通信带宽降低两个数量级来训练高质量的模型。
2.每个边缘设备上的数据是IID。
解决办法:提出了多任务学习(MTL)框架,并开发了MOCHA来解决MTL中的系统挑战;FedAvg可以处理某些Non-IID数据。
对于高度倾斜的Non-IID数据,FedAvg训练的卷积神经网路精度大大降低,对于MNIST,CIFAR-10和关键字识别(KWS)数据集的准确率分别高达11%、51%和55%。对于这问题,在第三节指出精度降低是因为权重分散,权重分散量化了在初始权重相同的情况下两个不同训练过程中权重的差异。然后作者证明了训练中的权重散度是由每个设备(或客户端)上的类的分布和总体分布之间的搬土距离所限定的。这个界限受学习速率、同步步数和梯度的影响。最后,在第4节中,我们提出了一种数据共享策略,通过分配少量的全局共享数据(包含每个类中的示例)来改进非IID数据的FedAvg。这就需要在准确性和集中性之间进行权衡。实验表明,在CIFAR-10上,如果我们愿意集中和分发5%的共享数据,则准确率可以提高30%。
二、FedAvg on Non-IID Data
数据集
1.MNIST
2.CIFAR-10
3.Speech commands datasets。该数据集由35个单词组成,每个单词持续1秒。为了使其一致,我们使用一个包含10个关键字的数据子集作为关键字定位(KWS)数据集。对于每个音频片段,我们提取了10个MFCC特征,每帧30ms,步长为20ms,生成50x10个特征,用于神经网络训练。
数据分布设置
训练集被均匀地分为10个客户机。对于IID设置,每个客户端随机分配10个类的统一分布。对于Non-IID设置,数据按类排序并划分为两种极端情况:(a)1类非IID,每个客户端仅从单个类接收数据分区;(b)2类非IID,其中排序的数据被分成20个分区,每个客户端从2个类中随机分配2个分区。
参数设置
B,batch 大小;E,本地epoch的数量;
对于MMIST:B=10或100,E=1,learning rate=0.1,dacay rate=0.995;
对于CIFAR-10:B=10或100,E=1和5,learning rate=0.1,dacay rate=0.992;
对于KWS:B=10和50,E=1和5,learning rate=0.05,dacay rate=0.992
对于SGD: 学习率和衰减率是相同的,但B是10倍大。这是因为FedAvg的全局模型在每次同步时平均分布在10个客户机上。
实验结果
对于IID实验,三个数据集的FedAvg收敛曲线和SGD的大部分相同。
对于Non-IID实验,FedAvg模型的精度大幅度降低。其中1类Non-IID降得最多。使用更多的Epoch(E-5)不能减少降低。FedAgv对Non-IID数据进行预训练时,精度仍然下降。



三、Weight Divergence due to Non-IID Data
测试精度取决于训练的权重,另一种比较FedAvg和SGD的方法是在相同的权重初始化的情况下,查看相对于SGD的权重的差异。它被称为重量发散,可通过以下公式计算:

如图下所示,随着数据变得越来越Non-IID,从IID到2级Non-IID再到1级Non-IID,所有层的权重发散都会增大。

1.Mathematical demonstration
下面给出权重分散的数学分析。给定紧致空间 X X X,类别空间 Y = [ C ] Y=[C] Y=[C],其中 [ C ] = 1 , . . . , C [C]={1,...,C} [C]=1,...,C。点对 x , y {x,y} x,y的分布是 P P P。函数 f : X → S f:X \rightarrow S f:X→S为 X X X到对应概率单纯型 S S S 的映射,其中 S = { z ∣ Σ i = 1 C z i = 1 , z i ≥ 0 , ∀ i ∈ [ C ] } S=\{{z|\Sigma^{C}_{i=1}z_{i}=1,z_{i}\geq 0,\forall i\in[C]}\} S={z∣Σi=1Czi=1,zi≥0,∀i∈[C]}, f i f_{i} fi表示第 i 类的概率, f f f 在假设类别 w w w上参数化处理,例如神经网络的权重。基于广泛应用的交叉熵损失损失函数 l(w) 为:

忽略泛化误差,直接优化种群损失,则学习问题变为:

使用 SGD 循环优化计算 w 值。中心化的 SGD 执行以下更新, w t ( c ) w^{(c)}_{t} wt(c)表示中央服务器第i次更新后的权重。

在联邦学习问题中,假设有 K 个客户端,在每个客户端本地执行单独的 SGD 优化。 n t n_{t} nt表示k客户端的本地数据集, w t k w_{t}^{k} wtk表示客户端k第t轮更新后的权值。

每执行 T 轮优化后在中央服务器端进行一次同步处理,其中 w m T ( f ) w^{(f)}_{mT} wmT(f)表示全局模型第T次同步后的权值

w m T ( f ) w^{(f)}_{mT} wmT(f)和 w m T ( c ) w^{(c)}_{mT} wmT(c)之间的权重分散可以用下图理解。如果数据集是IID,对于每个客户端K,本地的权值分散 w m T ( f ) w^{(f)}_{mT} wmT(f)和中央服务器的权值分散 w m T ( c ) w^{(c)}_{mT} wmT(c)的差距是很小的。如果数据是Non-IID,由于数据分布问题,客户端权重分散和中央服务器的权值分散的差距随着迭代次数的增加会加大。

为了正式约束 w m T ( f ) w^{(f)}_{mT} wmT(f)和 w m T ( c ) w^{(c)}_{mT} wmT(c)之间的权重分散,作者提出以下建议:
Proposition 3.1. 对于 K 个客户端,每个客户端都有 n ( k ) n^{(k)} n(k)个 IID 样本,第 k 个客户端数据分布为 p ( k ) p^{(k)} p(k)。如果有对于每一类 i 都为 
每隔 T 步骤进行一次同步处理,则 m 次同步后的权重散度有如下不等式

Remark3.2. 第m次同步后权重分散主要来自两个地方。1.第m-1次同步后的权重分散;2.客户端 k 上数据分布的概率距离相对于实际整体分布的权重散度。
Remark 3.3. 第(m-1) 次同步后的权重分散以下式的强度增强:
因为 a ( k ) ≥ 0 a^{(k)} \geq0 a(k)≥0,所以上式 ≥ 0 \geq0 ≥0。因此,如果联邦学习中不同的客户端从不同的初始 权值开始,那么即使数据遵循 IID 仍然会遇到较大的权重差异,从而导致精度下降。
Remark 3.4. 当所有客户端从相同的权值初始化,那权值分散的的根本原因是
该值为客户端 k 上的数据分布和中央服务器端总体分布之间的搬土距离(EMD)。EMD 受学习速率、同步前步数 T 和梯度的影响。
2 Experimental Validation
该实验设置个8个EMD值,每个EMD生成5种分布,计算这种5分布权重分散的平均值和变化。
WeightDivergencevs. EMD 对于这三个数据集,每一层的权重散度随着EMD的增加而增加,如下图所示。对于每个数据集上的所有SGD、IID和Non-IID实验,初始权重相同。因此,根据Remark3.2,1次同步后的权重散度不受(m−1)次权值分散的影响,因为当m=1时, ∣ ∣ w m − 1 f − w m − 1 c ∣ ∣ ||w_{m-1}^{f}-w_{m-1}^{c}|| ∣∣wm−1f−wm−1c∣∣为0。因此,图4中的结果支持Proposition 3.1,即权重发散的界受EMD的影响。这种影响在第一个卷积层和最后一个完全连接层中更为显著。

Test Accuracy vs. EMD 对于每个EMD,在相同的5个分布上计算测试精度的平均值和标准差,结果汇总在下表中。
对于这三个数据集,随着数据 Non-IID 程度加强,下降速度也越来越快。因此,在平衡IID数据和提高FedAvg的准确性之间存在一种权衡。
为了更仔细地观察测试精度变化,当EMD=1.44时,箱线图显示了5次运行的测试精度。此外,表2显示,MNIST、CIFAR-10和KWS的最大变化分别小于0.086%、2%和1%。因此,精度受EMD的影响,而不是受潜在分布的影响。结果表明,在给定数据分布的情况下,EMD可以用来估计FedAvg的精度。

四、Weight Divergence due to Non-IID Data
从上图,当EMD超过一定阈值时,测试精度急剧下降。作者提出一个数据共享策略:由各类数据的统一分布组成的全局共享数据集G集中在云中。在FedAvg初始化阶段,将用数据集G的模型和G的随机 α \alpha α部分分发给每个客户端。每个客户机的本地模型根据G的子集和私有数据进行训练。然后,云从客户端聚合本地模型,用FedAvg训练一个全局模型。

这个策略有两个参数调节准确度:
1.测试准确度和G大小之间的权衡, β = ∣ ∣ G ∣ ∣ ∣ ∣ D ∣ ∣ ∗ 100 % \beta=\frac{||G||}{||D||}*100\% β=∣∣D∣∣∣∣G∣∣∗100%,其中 D D D是全部客户端数据的大小。
2.测试精度和 α \alpha α之间的权衡。 α \alpha α为分发给一个客户端的数据占整个共享数据G的比例。
本实验中将 CIFAR-10 训练集分为两部分,其中客户端 D 包含 40000 个样本数据,剩余部分 H 包含 10000 个样本。D 划分为 10 个 1 类 Non-IID 数据分区,H 生成 10 个随机的(belta=2.5% 至 25%) G s ′ G^{'}_{s} Gs′子集。实验结果见下图

随着 belta 值的增大,测试准确度不断提升,最高达到 78.72%。即使 belta 取值较小( β \beta β=10%),对于 1 类 Non-IID 数据的准确度也能达到 74.12%,而在没有使用数据共享策略的情况下,准确度仅为 44%。此外,图 7(b)的实验表明,在进行数据分发时并不需要将 G 整体分发到客户端,相反,只需要将 G 的一个随机部分分发给每个客户端就可以获得很好的效果。