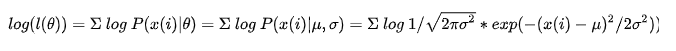文章目录
- 改进项目背景
- 量化函数的改进
- non-iid数据集的设置
- Fedlab划分数据集的踩雷
改进项目背景
在前面的项目中,虽然对联邦学习中,各个ue训练出来的模型上传的参数进行了量化,并仿真的相关结果。但是仍有一些俺不是非常符合场景的情况,需要改进的方向如下:
- 量化函数需要重写,将前面的只对小数点后进行0~1的量化改成自适应的在一段范围之内的数组量化。
- 信道仿真函数,在真实的通信环境中,一个信道的速率模拟可以由一个基于正态分布的初始速率,每隔一定时间加减均匀分布的变化值。
- 根据量化的程度不同,模型分为基础值和增量值,先传数据量较少的基础值,如果通信条件好的画
- 需要模仿接收方BS的接收规则:首先应该计算传输过程中的耗时,如果耗时超过了一个等待的门限,那么这个模型就不会被纳入聚合的model们里。如果接收了基础值之后,BS还会等待一段时间,如果增量值没到达,那只能用基础值去参与聚合了。这样对于BS来说就陷入一个博弈:是采用更精确的量化模型去提高自己模型的准确度呢,还是采用更少的量化程度的模型来保证在信道上能够正确传输。而我正是要仿真这样一个场景。
- 联邦学习框架的使用:PySyft在自己一个电脑上的仿真完全没用!完全可以抛弃框架自己写代码去模拟模型聚合与信道上的传输过程。
- 急需一个能够仿真出non-iid数据集的库,方便后续的仿真代码编写。
量化函数的改进
对原始数组进行线性变化,映射在一定范围内:
V q = Q × ( V x − min ( V x ) ) V_q=Q\times(V_x-\min(V_x)) Vq=Q×(Vx−min(Vx))
V x ′ = V q / Q + min ( V x ) V_x'=V_q/Q+\min(V_x) Vx′=Vq/Q+min(Vx)
Q = S / R , R = max ( V x ) + m i n ( V x ) , S = 1 < < b i t s − 1 Q=S/R,R=\max(V_x)+min(V_x),S=1<<bits-1 Q=S/R,R=max(Vx)+min(Vx),S=1<<bits−1
其中 V x V_x Vx表示原浮点数, V q V_q Vq表示量化后的定点数值, V x ′ V_x' Vx′表示根据量化参数还原出的浮点数,bits为量化比特位数。
传输的时候只需要传输低比特矩阵 V q V_q Vq和参数 Q , S , R Q,S,R Q,S,R等,在接收端即可还原成浮点数。
总而言之,举例:一个正弦函数值数组,经过4bit量化后呈现如下效果:

而神经网络中同一个层的tensor,数值分布恰好在同一个数量范围内,适合这样的数组量化:我们选择这个tensor中的最大值和最小值,以此为范围进行量化。
#4bit量化前:
tensor([ 0.0201, 0.0059, 0.0153, -0.0319, -0.0419, 0.0025, -0.0467, -0.0022,0.0106, 0.0512, -0.0321, -0.0190, -0.0409, 0.0128, 0.0191, 0.0479,-0.0289, -0.0515, -0.0237, -0.0473, -0.0420, -0.0156, -0.0371, 0.0184,0.0014, 0.0103, -0.0436, -0.0375, 0.0042, -0.0070, 0.0027, 0.0168])
#4bit量化后:
tensor([ 0.0215, 0.0072, 0.0143, -0.0287, -0.0430, 0.0000, -0.0502, 0.0000,0.0072, 0.0502, -0.0287, -0.0215, -0.0430, 0.0143, 0.0215, 0.0502,-0.0287, -0.0502, -0.0215, -0.0502, -0.0430, -0.0143, -0.0359, 0.0215,0.0000, 0.0072, -0.0430, -0.0359, 0.0072, -0.0072, 0.0000, 0.0143])
具体的函数如下:
def Quant(Vx, Q, RQM):return round(Q * Vx) - RQMdef QuantRevert(VxQuant, Q, RQM):return (VxQuant + RQM) / Qdef ListQuant(data_list, quant_bits):# 数组范围估计data_min = min(data_list)data_max = max(data_list)# 量化参数估计Q = ((1 << quant_bits) - 1) * 1.0 / (data_max - data_min)RQM = (int)(np.round(Q*data_min))# 产生量化后的数组quant_data_list = []for x in data_list:quant_data = Quant(x, Q, RQM)quant_data_list.append(quant_data)quant_data_list = np.array(quant_data_list)return (Q, RQM, quant_data_list)def ListQuantRevert(quant_data_list, Q, RQM):quant_revert_data_list = []for quant_data in quant_data_list:# 量化数据还原为原始浮点数据revert_quant_data = QuantRevert(quant_data, Q, RQM)quant_revert_data_list.append(revert_quant_data)quant_revert_data_list = np.array(quant_revert_data_list)return quant_revert_data_listnon-iid数据集的设置
信道变化->BS接收到ue的模型数量变化->聚合时用于平均的model数量变化
⬆️只有数据集是non-iid的时候,model数量变化才能明显表现出对性能的影响。
如果各个ue在相同数据集上训练相同batch,再进行聚合平均,聚合的model数量对性能影响不大。
我寻找到了一个由本校学长参与开发的一个联邦学习函数库Fedlab,除了数据集的处理,库还提供了别的很多在联邦学习中非常有用的函数,如BS和客户机的交流通信函数等,在这里把Github上的repo贴一下:
https://github.com/SMILELab-FL
点开才发现,这个repo居然是同校计算机学院的一位博士学长创建和维护的,后来还在飞书上联系到了他。各位如果有兴趣的话,非常建议在repo的issue上提出问题,他们都会即使解答的。
另外,如果不想下载Fedlab这个库,或者对Dirichlet划分是数学原理感兴趣的,可以参考下面这个:
https://zhuanlan.zhihu.com/p/468992765
按Dirichlet分布划分Non-IID数据集

由于Dataloader在每次加载时数据的索引不变,因此在多轮测试的时候,每个ue上的数据分布不会变(区别于完全随机)。
Fedlab划分数据集的踩雷
一开始,我是直接按照这个文档来的:https://zhuanlan.zhihu.com/p/411308268,刚好我也需要采用CIFAR10数据集,但是在其中有这样一句导入包:from fedlab.utils.dataset.sampler import SubsetSampler,是错误的,检查源码也发现dataset里面根本就没有sampler,这让我十分抓狂。后面询问之后才知道,原来sampler的效率太低了,他们已经在新版本放弃不用了,新的划分方案直接看github中的tutorial文件夹部分。于是我找到了如下:
partitioned_cifar10的用法
class PartitionedCIFAR10(root, path, dataname, num_clients, download=True, preprocess=False, balance=True, partition=‘iid’, unbalance_sgm=0, num_shards=None, dir_alpha=None, verbose=True, seed=None, transform=None, target_transform=None)
我们就需要先实例化这一个类,然后利用这个类提供的几个函数来实现数据集的划分与加载。这个类有如此多的参数,那么具体每个参数什么含义,我们在使用的时候又该如何设置呢?
-
root (str) – Path to download raw dataset.
和pytorch的datasets一样,填'/cifar10' -
path (str) – Path to save partitioned subdataset.
预训练好的.pkl文件名,我填'/cifar10_hetero_dir.pkl' -
dataname (str) – “cifar10” or “cifar100”
填‘/cifar10’ -
num_clients (int) – Number of clients.
要分成几份,对应ue的个数 -
download (bool) – Whether to download the raw dataset.
同pytorch里的datasets -
preprocess (bool) – Whether to preprocess the dataset.
是否预划分,这个第一次必须填true,后面就可以填false了 -
balance (bool, optional) – Balanced partition over all clients or not. Default as True.
false -
partition (str, optional) – Partition type, only “iid”, shards, “dirichlet” are supported. Default as “iid”.
填'dirichlet' -
unbalance_sgm (float, optional) – Log-normal distribution variance for unbalanced data partition over clients. Default as 0 for balanced partition.
可选项,没填 -
num_shards (int, optional) – Number of shards in non-iid “shards” partition. Only works if partition=“shards”. Default as None.
可选项,没填 -
dir_alpha (float, optional) – Dirichlet distribution parameter for non-iid partition. Only works if partition=“dirichlet”. Default as None.
0.3 -
verbose (bool, optional) – Whether to print partition process. Default as True.
可选项,没填 -
seed (int, optional) – Random seed. Default as None.
2022 -
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version.
同pytorch里的datasets,对图像进行预处理,然后转化为tensor -
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
可选项,没填
其中一个非常容易错的点。PartitionedCIFAR10这个类中的preprocess实际上就是按照所选的划分模式,对整个数据集贴标签形成一个字典,标注每条数据属于哪个ue,保存在一个.pkl文件中。后面在训练加载数据的时候,就按照这个字典从数据集中取数据,就完成了non-iid的划分啦。
同时transform里面和pytorch的写法一样的,可以对图片进行大小的更改,进行normalize等操作,当然一定别忘记了必须Totensor()将图片转化为tensor,然而我发现忘记totensor,改了之后,发现还是报错!仔细以看才知道,原来是改了transform,但是忘记了重新preprocess一下,导致还是按照旧的方式去加载,自然错啦。
后面的使用,PartitionedCIFAR10提供了两个比较有用的函数;
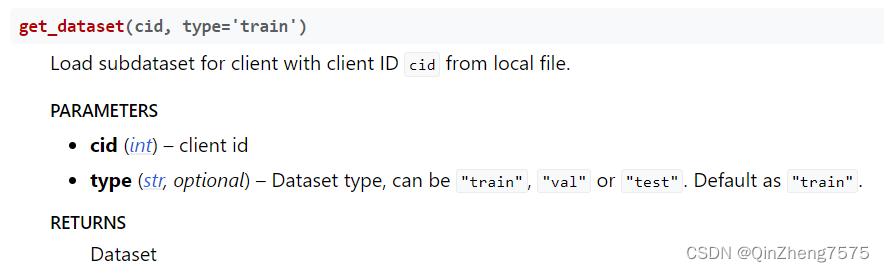
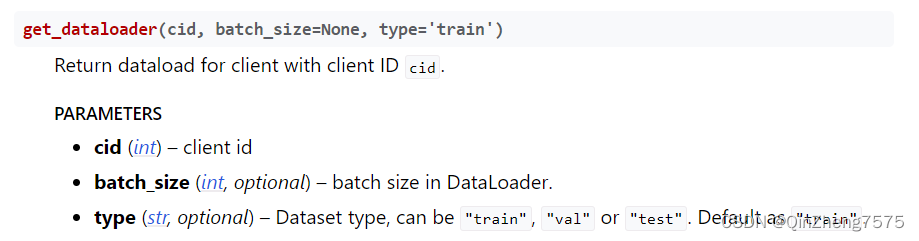
他们的返回值就是pytorch中的dataset和dataloader了。用法也和pytorch中的一样:
hetero = PartitionedCIFAR10(root='/cifar10',path='/cifar10_hetero_dir.pkl',dataname="cifar10",num_clients=train_args['num_clients'],download=False,preprocess=False,balance=False,partition="dirichlet",seed=2022,dir_alpha=0.3,transform=transforms.Compose([transforms.Resize((32, 32)),transforms.ToTensor(),transforms.Normalize(mean=[0.4750, 0.4750, 0.4750], std=[0.2008, 0.2008, 0.2008])]),target_transform=transforms.ToTensor()
)for id, ue in enumerate(UE_list):train_loader = hetero.get_dataloader(id, batch_size=train_args['batch_size'])for batch_idx, (data, target) in enumerate(train_loader):# if batch_idx > 100:# breakue_data = data.to(device)ue_target = target.to(device)loss = ue.train(ue_data, ue_target)
后面的就是按照正常方式去训练啦,最后也是成功得到了一个不同bit压缩的联邦学习训练效果对比图: