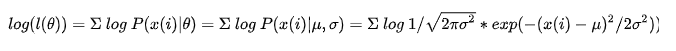《Data-Free Knowledge Distillation for Heterogeneous Federated Learning》ICML 2021
最近出现了利用知识蒸馏来解决FL中的用户异构性问题的想法,具体是通过使用来自异构用户的聚合知识来优化全局模型,而不是直接聚合用户的模型参数。然而,这种方法依赖于proxy dataset,如果没有这proxy dataset,该方法便是不切实际的。此外,集成知识没有被充分利用来指导局部模型的训练,这可能反过来影响聚合模型的性能。
基于上述挑战,这篇文章提出了一种data-free知识蒸馏法来处理FL中的异构性问题,该方法称为FeDGen(Federated Distillation via Generative Learning)。其中服务器学习一个轻量级生成器,以data-free的方式集成用户信息,然后广播给用户,使用学习到的知识作为"归纳偏置"来调节局部训练。("归纳偏置"就是基于先验知识对目标模型的判断,将无限可能的目标函数约束在一个有限的假设类别之中)
文章简介
FeDGen学习一个仅从用户模型的预测规则导出的生成模型(在给定目标标签的情况下,该模型可以产生与用户预测的集合一致的特征表示)。该生成器随后被广播给用户,用从“潜在空间”(生成器产生的分布空间)采样得到的增广样本escort他们的模型训练(该潜在空间体现从其他对等用户提取的知识)。
给定一个比输入空间小得多的潜在空间,FeDGen所学习的生成器可以是轻量级的,给当前的FL框架带来最小的开销。
创新点
- 算法只从用户局部模型的预测层提取知识,不依赖于用户的其他数据。
- 不同于其他仅优化全局模型的方法,该算法使用提取的知识对局部模型施加归纳偏置,直接调节局部模型的更新,使模型在Non-IID下具备更好的泛化性能。
- 与现有技术相比,该方法通过更少的通信轮次却能产生具备更好泛化性能的全局模型。
算法理解
该文章讨论了一个用于监督学习的典型FL设置,即多类别分类的一般问题。
1、公式及符号定义
X ⊂ R p R^p Rp为样本空间,Z⊂ R d R^d Rd(d < p)为潜在的特征空间,T代表由X的数据分布D和真值标签函数c* : X → y 组成的域T := <D, C*>。(域T可以理解为用户端的任务T。)
模型参数θ := [ θ f θ^f θf, θ p θ^p θp]包含两个部分:一个是由 θ f θ^f θf参数化的特征提取器f : X→Z,另一个是由 θ p θ^p θp参数化的预测函数h : Z→ Δ y Δ^y Δy, Δ y Δ^y Δy is the simplex over y。
给定一个非负凸损失函数L : Δ y Δ^y Δy × y → R,由θ参数化的模型在域T上的损失定义为 L T L_T LT(θ) := E x D E_{x~D} Ex D[L(h(f(x; θ f θ^f θf); θ p θ^p θp), c*(x))]。
2、知识蒸馏
知识蒸馏是一个teacher-student模式,目的是通过从一个或多个强大的teacher模型提取的知识来学习一个轻量的student模型。一种典型的方法是利用proxy dataset来最小化来自techer模型 θ T θ^T θT和student模型 θ s θ^s θs的logits输出。(logits就是最终的全连接层的输出,通常神经网络中都是先有logits,而后通过sigmoid函数或者softmax函数得到概率P)
目前已有将知识蒸馏应用于FL的方法,该方法将用户模型 θ k θ^k θk作为teacher,student(global)模型θ通过聚合 θ k θ^k θk的信息来提高泛化性能。优化目标如下:
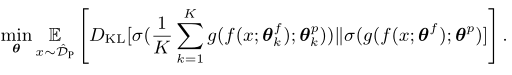
上述方法的一个主要限制在于其对proxy dataset的依赖,proxy dataset的选择在蒸馏性能中起着关键作用。
为应对这一限制,这篇文章提出以data-free的方式将知识蒸馏应用于FL。
3、FeDGen
3.1、知识提取
文章的核心思想是提取关于“the global view of data distribution”的知识(这些知识是传统FL无法观察到的),并将这些知识提取到本地模型中以指导他们的学习。
- 首先考虑学习一个条件分布Q* : y → x 来描述这一知识:
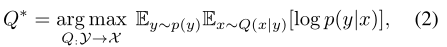
其中p(y)和p(y|x)分别是真值标签的先验分布和后验分布,两者都是未知的。但这一条件分布Q*,在高维度的样本空间X的情况下将导致计算过载,并可能造成用户相关数据配置的泄露。 - 因此,文章提出另一个可行的想法:恢复潜在空间上的induced distribution G* : Y→Z(潜在空间也就是全局数据的特征分布,比原始数据空间更紧凑,并且可以减少某些隐私泄露的风险):
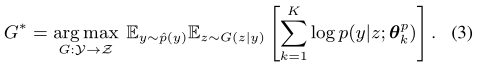
基于上述推导,文章旨在通过学习一个条件生成器G来执行知识提取(恢复一个潜在空间),该生成器由w参数化,在服务端进行优化,优化目标如下:
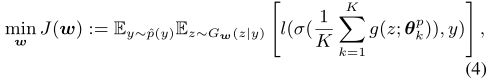
其中g是logit输出,σ是激活函数。对于任意标签y,优化(4)只需要用户模型的预测模块 θ k p θ^p_k θkp。具体来说,为了使G(· | y)的输出多样化,文章向生成器 G w G_w Gw引入了一个噪声向量ε ~ N(0, i)(3.4部分有具体的学习过程展示,类似于重参数化)。
这样一来,给定任意的目标标签y,生成器 G w G_w Gw 可以产生“特征表示” z ~ G w G_w Gw(· | y),该特征表示(潜在空间)可以根据所有用户模型引导理想的预测。
3.2、知识蒸馏
将完成学习的生成器 G w G_w Gw广播给各个用户,使每个用户模型都可以从 G w G_w Gw中进行采样以获得特征空间上的增广表示:z ~ G w G_w Gw(· | y)。用户模型 θ k θ_k θk的优化目标也变为“最大化其为增广样本产生理想预测的概率”:
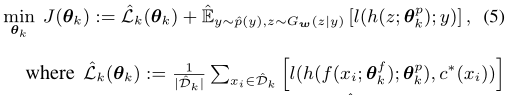
(5)中第一项是用户数据 D k D_k Dk-hat的经验风险。增广样本可以向用户引入归纳偏置,强化模型训练。
经过以上步骤,FeDGen通过交互学习一个依赖于用户模型预测规则的轻量级生成器 G w G_w Gw,并利用该生成器向用户传递一致的知识,已经实现了data-free的知识蒸馏。
3.3、FeDGen中灵活的参数共享
FeDGen仅共享用户模型的预测层 θ k p θ^p_k θkp, θ k f θ^f_k θkf则保留在用户本地。与共享整个模型的策略相比,这种部分共享模式更有效,同时更不容易发生数据泄漏。
3.4、FeDGen伪代码及学习过程


进一步理解知识蒸馏
1、知识蒸馏与归纳偏置
G w G_w Gw基于用户模型的预测规则进行学习,目的是融合来自用户模型的聚合信息来估计全局数据分布 r(x|y)。接着用户从 G w G_w Gw(x | y)进行采样,采样结果作为自身的归纳偏置,进而调整决策边界。如下图所示,在知识蒸馏KD之后,一个用户的准确率从81.2%提高到了98.4%

2、知识蒸馏与分布匹配
FEDGEN和先前研究的主要区别在于:知识被蒸馏至用户模型,而不是全局模型。因此,蒸馏出来的知识(向用户传递的归纳偏置)可以通过在潜在空间Z上进行分布匹配,直接调节用户的学习。
3、知识蒸馏与泛化性能
用户异构性越高,用户间的数据分布差异也越高,这会降低全局模型的质量;而通过向本地用户提供与全局分布一致的增广数据,则可以提高泛化性能。
实验
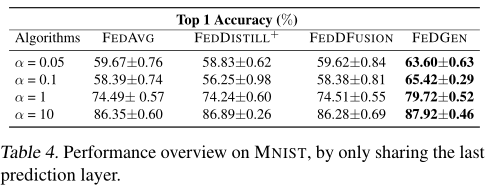
文章对FeDGen的多项性能进行了实验分析:预测精度(Table 1)、学习效率(Figure 6)、对游离用户的敏感度(Figure 5b,6a,6b)、对不同模型结构的敏感度(Figure 5d,5c),对通信延迟的敏感度(Table 1)、对生成器的网络结构和采样大小的敏感度(Table 2,Table 3,Figure 7)、灵活参数共享的扩展性分析(Table 4,figure 8)
Figure 4是数据集MNIST在(迪利克雷分布)参数a的不同取值下的异构性可视化。

预测精度、对通信延迟的敏感度(EMNIST)

学习效率(Figure 6)、对游离用户的敏感度(Figure 5b)、对不同模型结构的敏感度(5c、5d)

对生成器的网络结构(Table 2)和采样大小的敏感度(Table 3,Figure 7)