Alex、Hinton等人在2012年的NIPS论文《ImageNet Classification with Deep Convolutional Neural Networks》中将LRN应用于深度神经网络中(AlexNet)。论文见:http://www.cs.toronto.edu/~hinton/absps/imagenet.pdf ,截图如下:

公式解释:
:ReLU处理后的神经元,作为LRN的输入;
:LRN的输出,LRN处理后的神经元;
N:kernal总数或通道数;
k、n、、
:为常量,是超参数,k类似于bias,n对应于Caffe中的local_size,在论文中这几个值分别为2、5、
、0.75。
LRN(Local Response Normalization):局部响应归一化,此层实现了” lateral inhibition”(侧抑制),通过对局部输入区域进行归一化来执行一种”侧抑制”。在AlexNet中,处理ReLU神经元时,LRN很有用,因为ReLU的响应结果是无界的,可以非常大,所以需要归一化。当处理具有无限激活(unbounded activation)的神经元时(如ReLU),可以通过LRN对其归一化(normalize),因为它允许检测具有大神经元响应的高频特征(high-frequency features),同时衰减局部周围(local neighborhood)均匀大(uniformly large)的响应。它是一种正则化类型。一般应用在激活、池化后进行的一种处理方法。该层的输出维数始终等于输入维数。
在神经生物学有一个概念叫做侧抑制(lateral inhibition),指的是被激活的神经元抑制相邻的神经元。归一化的目的是”抑制”,局部响应归一化就是借鉴侧抑制的思想来实现局部抑制。LRN层模仿生物神经系统的侧抑制机制,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其它反馈较小的神经元,增强了模型泛化能力。
后来研究者发现LRN起不到太大作用,LRN的作用已被正则化技术(regularization techniques,例如dropout and batch normalization)、更好的初始化和训练方法所取代。
在Caffe的caffe.proto中,LRN参数内容如下:分为通道间归一化(local_size*1*1)和通道内归一化(1*local_size*local_size)
// Message that stores parameters used by LRNLayer
message LRNParameter {optional uint32 local_size = 1 [default = 5];optional float alpha = 2 [default = 1.];optional float beta = 3 [default = 0.75];enum NormRegion {ACROSS_CHANNELS = 0;WITHIN_CHANNEL = 1;}optional NormRegion norm_region = 4 [default = ACROSS_CHANNELS];optional float k = 5 [default = 1.];enum Engine {DEFAULT = 0;CAFFE = 1;CUDNN = 2;}optional Engine engine = 6 [default = DEFAULT];
}各参数介绍见:http://caffe.berkeleyvision.org/tutorial/layers/lrn.html
注:以上内容主要来自网络整理。
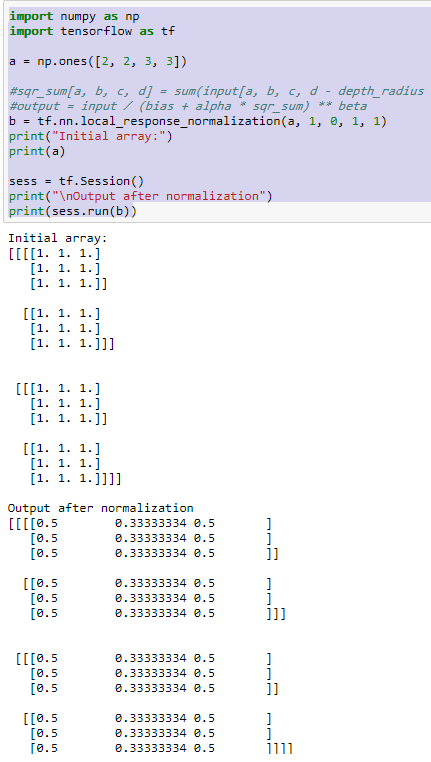
以下是实现的测试代码,仅实现通道间归一化,包括C++和tensorflow:
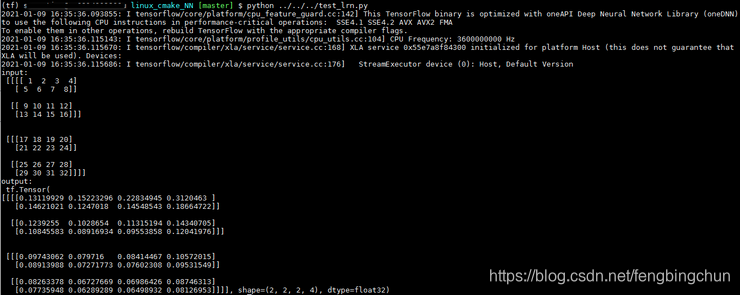
tensorflow的实现如下:
import tensorflow as tf
import numpy as np
x = np.array([i for i in range(1, 33)]).reshape([2, 2, 2, 4])
y = tf.nn.lrn(input=x, depth_radius=2, bias=1, alpha=1, beta=0.75)
print("input:\n", x)
print("output:\n", y)C++代码实现如下:
lrn.hpp:
#ifndef FBC_NN_LRN_HPP_
#define FBC_NN_LRN_HPP_namespace ANN {enum class NormRegion {ACROSS_CHANNEL = 0,WITHIN_CHANNEL
};template<typename T = float>
class LRN {
public:LRN() = default;LRN(unsigned int local_size, T alpha, T beta, T bias, NormRegion norm_region) :local_size_(local_size), alpha_(alpha), beta_(beta), bias_(bias), norm_region_(norm_region) {}int run(const T* input, int batch, int channel, int height, int width, T* output) const;private:int across_channel(const T* input, int batch, int channel, int height, int width, T* output) const;int within_channel(const T* input, int batch, int channel, int height, int width, T* output) const;unsigned int local_size_ = 5; // nT alpha_ = 1.;T beta_ = 0.75;T bias_ = 1.; // kNormRegion norm_region_ = NormRegion::ACROSS_CHANNEL;
};} // namespace ANN#endif // FBC_NN_LRN_HPP_lrn.cpp:
#include "lrn.hpp"
#include <algorithm>
#include <cmath>namespace ANN {template<typename T>
int LRN<T>::run(const T* input, int batch, int channel, int height, int width, T* output) const
{if (norm_region_ == NormRegion::ACROSS_CHANNEL)return across_channel(input, batch, channel, height, width, output);elsereturn within_channel(input, batch, channel, height, width, output);
}template<typename T>
int LRN<T>::across_channel(const T* input, int batch, int channel, int height, int width, T* output) const
{int size = channel * height * width;for (int p = 0; p < batch; ++p) {const T* in = input + size * p;T* out = output + size * p;// N = channel; n = local_size_; k = bias_for (int i = 0; i < channel; ++i) {for (int y = 0; y < height; ++y) {for (int x = 0; x < width; ++x) {T tmp = 0;for (int j = std::max(0, static_cast<int>(i - local_size_ / 2)); j <= std::min(channel - 1, static_cast<int>(i + local_size_ / 2)); ++j) {tmp += std::pow(in[j * height * width + width * y + x], 2);}out[i * height * width + width * y + x] = in[i * height * width + width * y + x] / std::pow(bias_ + alpha_ * tmp, beta_);}}}}return 0;
}template<typename T>
int LRN<T>::within_channel(const T* input, int batch, int channel, int height, int width, T* output) const
{fprintf(stderr, "not implemented\n");return -1;
}template class LRN<float>;} // namespace ANNtest_lrn.cpp:
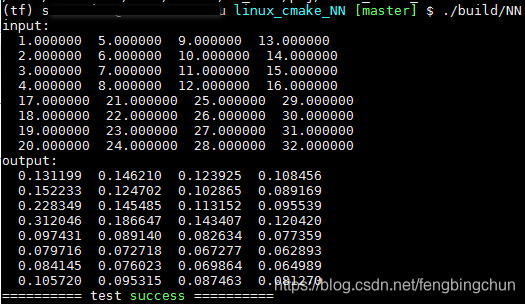
int test_lrn()
{int batch = 2, channel = 4, height = 2, width = 2;std::vector<float> input{ 1., 5., 9., 13., 2., 6., 10., 14., 3., 7., 11., 15., 4., 8., 12., 16.,17., 21., 25., 29., 18., 22., 26., 30., 19., 23., 27., 31., 20., 24., 28., 32.};CHECK(batch * channel * height * width == input.size());std::unique_ptr<float[]> output(new float[input.size()]);ANN::LRN<> lrn;lrn.run(input.data(), batch, channel, height, width, output.get());auto print = [height, width](const float* data, int length) {int size = height * width;for (int i = 0; i < length / size; ++i) {const float* p = data + i * size;for (int j = 0; j < size; ++j) {fprintf(stdout, " %f", p[j]);}fprintf(stdout, "\n");}};fprintf(stdout, "input:\n"); print(input.data(), input.size());fprintf(stdout, "output:\n"); print(output.get(), input.size());return 0;
}执行结果如下图所示:由结果可知,C++实现与tensorflow一致
tensorflow执行结果如下:
C++执行结果如下:
GitHub:https://github.com/fengbingchun/NN_Test