目录
- 1. 原理部分:
- 2. 香农界理论分析:
- 3. 代码实现:
- 4.实验结果
1. 原理部分:
原理部分参考什么是算术编码
一个从信源序列到不可压缩二元序列的一个可逆映射,假设序列 { X 1 … X n } \{X_{1} \ldots X_{n}\} {X1…Xn}, X n X_{n} Xn有m个取值,将这个序列进行算术编码,即利用m个取值对应的概率,对这个符号序列编码成二进制序列 { Y 1 … Y k } \{Y_{1} \ldots Y_{k}\} {Y1…Yk}的过程。
2. 香农界理论分析:
算术编码比起Haffman编码更逼近于香农极限
香农第一定理/无失真信源编码定理/变长信源编码定理:
无损情况下,数据压缩的临界值为这段信息的信息熵(编码后平均码长逼近信源信息熵),编码后的输出序列中每个新符号是接近等概的
可以通过仿真查看随着序列长度n的增大,算术编码的平均码长对信息熵的逼近过程,但n越大编解码速度也会快速提升(编解码算法复杂度没去研究):

平均码长-序列长度n曲线:
(应该是因为仿真用的文件不够大,导致n变大时后面出现波动)

3. 代码实现:
参考github
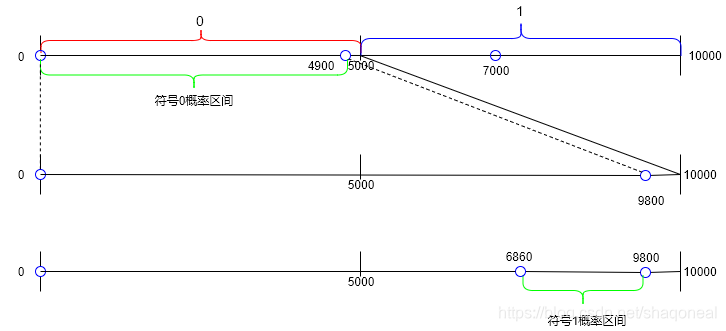
编码过程:
- 计算符号频数,将符号序列截断依次编码
- 根据符号序列中的次序和符号频数划分区间和映射区间
- 在最终目标区间中选取一个二进制表示最短的小数,去掉0和小数点后完成二进制编码
read_encode.py
import os
import math# 以二进制的方式读取文件,结果为字节
def fileload(filename):file_pth = os.path.dirname(__file__) + '/' + filenamefile_in = os.open(file_pth, os.O_BINARY | os.O_RDONLY)file_size = os.stat(file_in)[6]data = os.read(file_in, file_size)os.close(file_in)return data# 计算文件中不同字节的频数和累积频数
def cal_pr(data):pro_dic = {}data_set = set(data)for i in data_set:pro_dic[i] = data.count(i) # 统计频数sym_pro = [] # 频数列表accum_pro = [] # 累积频数列表keys = [] # 字节名列表accum_p = 0data_size = len(data)for k in sorted(pro_dic, key=pro_dic.__getitem__, reverse=True):sym_pro.append(pro_dic[k])keys.append(k)for i in sym_pro:accum_pro.append(accum_p)accum_p += iaccum_pro.append(data_size)tmp = 0for k in sorted(pro_dic, key=pro_dic.__getitem__, reverse=True):pro_dic[k] = [pro_dic[k], accum_pro[tmp]]tmp += 1return pro_dic, keys, accum_pro# 小数十进制转二进制
def dec2bin(x_up, x_down, L):bins = ""while ((x_up != x_down) & (len(bins) < L)):x_up *= 2if x_up > x_down:bins += "1"x_up -= x_downelif x_up < x_down:bins += "0"else:bins += "1"return bins# 编码
def encode(data, pro_dic, data_size):C_up = 0A_up = A_down = C_down = 1for i in range(len(data)):C_up = C_up * data_size + A_up * pro_dic[data[i]][1]C_down = C_down * data_sizeA_up *= pro_dic[data[i]][0]A_down *= data_sizeL = math.ceil(len(data) * math.log2(data_size) - math.log2(A_up)) # 计算编码长度bin_C = dec2bin(C_up, C_down, L)amcode = bin_C[0:L] # 生成编码return C_up, C_down, amcode解码过程:
- 根据该小数找到符号频数对应区间
- 从区间映射到符号次序
decode_save.py
import os
import math
from fnmatch import fnmatch# 二分法搜索
def binarysearch(pro_list, target):low = 0high = len(pro_list) - 1if pro_list[0] <= target <= pro_list[-1]:while high >= low:middle = int((high + low) / 2)if (pro_list[middle] < target) & (pro_list[middle + 1] < target):low = middle + 1elif (pro_list[middle] > target) & (pro_list[middle - 1] > target):high = middle - 1elif (pro_list[middle] < target) & (pro_list[middle + 1] > target):return middleelif (pro_list[middle] > target) & (pro_list[middle - 1] < target):return middle - 1elif (pro_list[middle] < target) & (pro_list[middle + 1] == target):return middle + 1elif (pro_list[middle] > target) & (pro_list[middle - 1] == target):return middle - 1elif pro_list[middle] == target:return middlereturn middleelse:return False# 译码
def decode(C_up, C_down, pro_dic, keys, accum_pro, byte_num, data_size):byte_list = []for i in range(byte_num):k = binarysearch(accum_pro, C_up * data_size / C_down) # 二分法搜索编码所在频数区间if k == len(accum_pro) - 1:k -= 1key = keys[k]byte_list.append(key)C_up = (C_up * data_size - C_down * pro_dic[key][1]) * data_sizeC_down = C_down * data_size * pro_dic[key][0]return byte_list # 返回译码字节列表# 整数二进制转十进制
def int_bin2dec(bins):dec = 0for i in range(len(bins)):dec += int(bins[i]) * 2 ** (len(bins) - i - 1)return dec# 保存文件
def filesave(data_after, filename):file_pth = os.path.dirname(__file__) + '/' + filename# 保存译码文件if (fnmatch(filename, "*_am.*") == True):file_open = os.open(file_pth, os.O_WRONLY | os.O_CREAT | os.O_BINARY)os.write(file_open, data_after)os.close(file_open)# 保存编码文件else:byte_list = []byte_num = math.ceil(len(data_after) / 8)for i in range(byte_num):byte_list.append(int_bin2dec(data_after[8 * i:8 * (i + 1)]))file_open = os.open(file_pth, os.O_WRONLY | os.O_CREAT | os.O_BINARY)os.write(file_open, bytes(byte_list))os.close(file_open)return byte_num # 返回字节数测试函数(main):amcode.py
from read_encode import *
from decode_save import *
from datetime import datetime# 计算编码效率
def code_efficiency(pro_dic, data_size, bit_num):entropy = 0# 计算熵for k in pro_dic.keys():entropy += (pro_dic[k][0] / data_size) * (math.log2(data_size) - math.log2(pro_dic[k][0]))# 计算平均码长ave_length = bit_num / data_sizecode_efficiency = entropy / ave_lengthprint("The code efficiency is %.3f%%" % (code_efficiency * 100))# 主函数
def amcode():filename = ["1","2"]filetype = [".txt",".jpg"]for i in range(1): # 预留多个文件一块处理print(60 * "-")print("Loading file:", filename[i] + filetype[i])t_begin = datetime.now()# 读取源文件data = fileload(filename[i] + filetype[i])data_size = len(data)print("Calculating probability of bytes..")# 统计字节频数pro_dic, keys, accum_pro = cal_pr(data)amcode_ls = ""C_upls = []C_downls = []byte_num = 1000 # 每次编码的字节数integra = math.ceil(data_size / byte_num) # 迭代次数print("\nEncoding begins.")# 编码for k in range(integra):C_up, C_down, amcode = encode(data[byte_num * k: byte_num * (k + 1)], pro_dic, data_size)amcode_ls += amcodeC_upls.append(C_up)C_downls.append(C_down)# 保存编码文件,返回编码总字节数codebyte_num = filesave(amcode_ls, filename[i] + '.am')t_end = datetime.now()print("Encoding succeeded.")print("Saved encoding file: " + filename[i] + '.am')print("The compressing rate is %.3f%%" % ((data_size / codebyte_num) * 100)) # 压缩比code_efficiency(pro_dic, data_size, len(amcode_ls)) # 编码效率print("Encoding lasts %.3f seconds." % (t_end - t_begin).total_seconds()) # 编码时间print("Encoding speed: %.3f Kb/s" % (data_size / ((t_end - t_begin).total_seconds() * 1024))) # 编码速率print()decodebyte_ls = []print("Decoding begins.")# 译码t_begin = datetime.now()for k in range(integra):if (k == integra - 1) & (data_size % byte_num != 0):decodebyte_ls += decode(C_upls[k], C_downls[k], pro_dic, keys, accum_pro, data_size % byte_num,data_size)else:decodebyte_ls += decode(C_upls[k], C_downls[k], pro_dic, keys, accum_pro, byte_num, data_size)# 保存译码文件filesave(bytes(decodebyte_ls), filename[i] + '_am' + filetype[i])t_end = datetime.now()print("Decoding succeeded.")print("Saved decoding file: " + filename[i] + '_am' + filetype[i])# 计算误码率errornum = 0for j in range(data_size):if data[j] != decodebyte_ls[j]:errornum += 1print("Error rate: %.3f%%" % (errornum / data_size * 100)) # 误码率print("Decoding lasts %.3f seconds." % (t_end - t_begin).total_seconds()) # 译码时间print("Decoding speed: %.3f Kb/s" % (codebyte_num / ((t_end - t_begin).total_seconds() * 1024))) # 译码速率if __name__ == "__main__":amcode()
4.实验结果

解码生成的图片和文件可在代码文件中看到,通过过程中的文件大小也能看出编码后文件变小了:



![[图像处理]14.分割算法比较 OTSU算法+自适应阈值算法+分水岭](https://img-blog.csdnimg.cn/c02140900dfe4b1f93edc608877901a4.jpeg)