压缩算法之算术编码浅析与实现
- 简介
- 实现思路
- 实现代码
- 参考资料
简介
算术编码,属于熵编码的范畴,常用于各种信息压缩场合,如图像、视频、音频压缩领域。
基本原理:
- 核心原则:出现频率高的信息,分配少的比特,频率低的信息则分配多的比特
- 简单来讲:将一串信息压缩到
[0, 1]区间的一个浮点值
算法效果:

举个例子
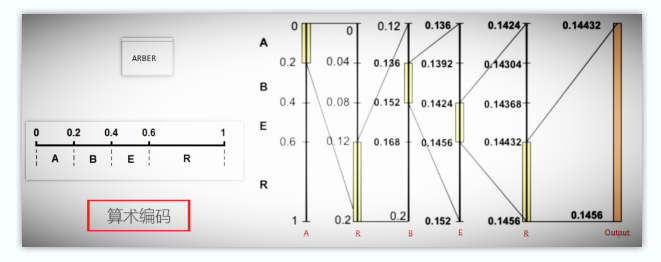
解释:
- 假设输入为
ARBER,每个符号对应概率为上图 - 将之一字排开到0-1实数轴上
- 对ARBER编码,最终输出一个具体的小数值[0, 1],解码是逆运算
-
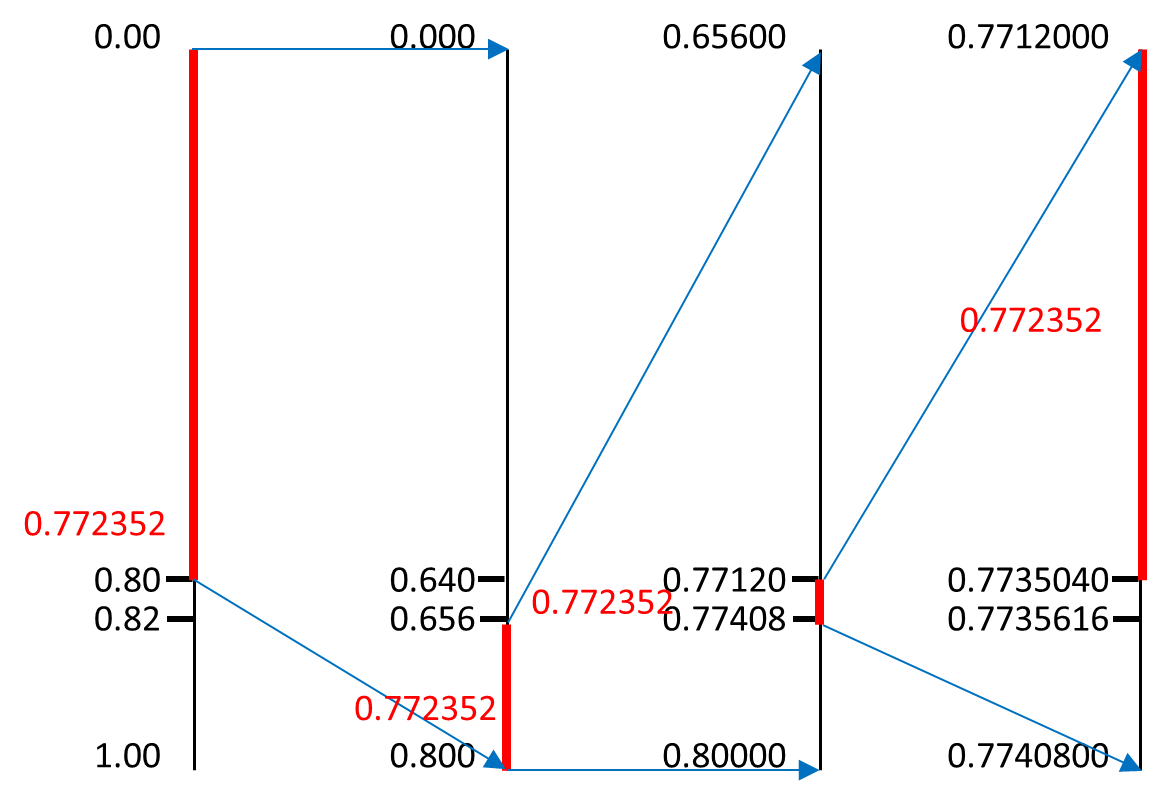
- 第一个A,得到0-0.2区间,对其按ABER符号的比例继续划分
- 第二个R,得到0.12-2区间,继续按比例划分
- 第三个B,得到0.136-0.152区间,重复以上过程
- 最终输出:0.14432-0.1456区间,任意一个值都可以表达ARBER字符串
参考自:https://segmentfault.com/a/1190000011561822
实现思路
步骤如下:
- 1)计算字符串的次数,除以总次数得到频率
- 2)分区
- 3)编码,将每个字符与码表对应,得到区间,再进行划分
- 4)直到读取完字符串,然后输出编码结果
- 5)逆过程解码,先判断该值在那个区,然后输出一个字符,再按比例划分区域,再判断,再输出
- 6)直到划分至该值所对应的区间,区间除以2是其值结束
过程debug:
问题1:区间1迭代到第二个区间就对应不上了**

根源:
- 公式迭代时编码bug,顺序执行后,选取了更新后的low
改前:
low = low + (high - low) * pp[pos];
high = low + (high - low) * pp[pos + 1];
改后:
int low_tmp = low;
low = low_tmp + (high - low_tmp) * pp[pos];
high = low_tmp + (high - low_tmp) * pp[pos + 1];
问题2**:区间迭代到第二个区间仍有问题**
根因:
- 单步迭代时,发现low_tmp是int类型,一直被截断成0了。
改正:将int 改为 double,即 double low_tmp = low;
实现代码
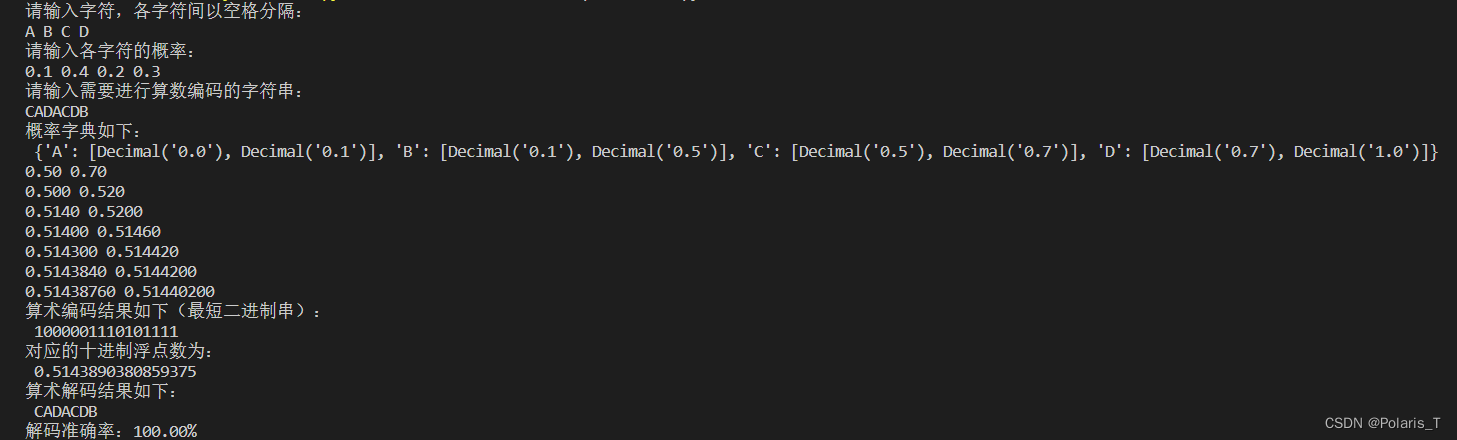
该算法用C++语言实现,代码如下:
#include <iostream>
#include <vector>
#include <string.h>
#include <algorithm>
#include <stdio.h>
#include <stdlib.h>
#include <queue>
#include <hash_map>using namespace std;// Algorithm Coding Test
int main(int argc, const char *argv[])
{
// 算术编码实现// Test Data Only UpperCase Letter// string str1 = "ARBER";// string str1 = "ABCDEFJKJA";// string str1 = "ABACDAAB";// string str1 = "HELLOWORLDIAMCOMING"; // 只能解析到IAMCO// string str1 = "WEAREHAPPYTOSOLVEIT"; // 当输入字符的类型和长度多了后,码表变大,区间变小,精度要求更高,不断细分后编码值会越来越小string str1 = "WEAREARBERREBWAEWRRRRRRW"; // 当前算法最多只能解码长度为24的字符串// variablestring outStr;vector<int> cnt(26);vector<int> p1(26);// initint i = 0;while (str1[i]) {cnt[str1[i] - 'A']++;i++;}int sum = 0;int len = 0;for(i = 0; i < 26; i++) {if (cnt[i] != 0) {sum += cnt[i];len++;}// cout << cnt[i] << endl;}// processing, calculation probability and partitionstd::cout << "CodeBook is displayed as below." << std::endl;double *pb = new double[len](); //probabilitychar *strMap = new char[len]();double *pp = new double[len + 1](); //probability partition 前后 0 1区间点数对应double *pp_tmp = new double[len + 1]();int j = 0;for (i = 0; i < len; i++) {while (cnt[j] == 0) {j++;}pb[i] = (double)cnt[j] / (double)sum;strMap[i] = 'A' + j;pp[i + 1] = pp[i] + pb[i];pp_tmp[i + 1] = pp[i + 1];j++;cout << pb[i] << " " << pp[i] << " " << strMap[i] << endl;}// codingdouble low = 0.0;double high = 1.0;i = 0;while (str1[i]) {int pos = -1;for (int j = 0; j < len; j++) {char ch = str1[i];if (strMap[j] == ch) {pos = j;break;}}if (pos >= 0) {double low_tmp = low;low = low_tmp + (high - low_tmp) * pp[pos];high = low_tmp + (high - low_tmp) * pp[pos + 1];// cout << low << " " << high << endl;}i++;}double output = (low + high) / 2;// cout << low << " " << high << " " << output << endl;// decodinglow = 0;high = 1;while (abs(output - (low + high) / 2) > 1e-15) { //double 精度是 15-16位有效数字// 解码一个字符i = 0;while (output > pp_tmp[i] && i < len + 1) { // 可用二分法查找来优化, 概率区间数组的长度比码表大1i++;}if (i == len + 1) { cout << "Decoding Fail!" << endl;return 0;} else {low = pp_tmp[i - 1];high = pp_tmp[i];outStr.push_back(strMap[i - 1]);}// update pp_tmppp_tmp[0] = low;pp_tmp[len] = high;for (i = 1; i < len; i++) {pp_tmp[i] = low + (high - low) * pp[i];// cout << pp_tmp[i] << " " << endl;}}// printfcout << endl;cout << "Source: " << str1 << endl;cout << "Coded : " << output << endl;cout << "Decode: " << outStr << endl;delete []pb;delete []strMap;delete []pp;delete []pp_tmp;system("pause");return 0;
}
上述代码可以利用二分查找法改进,优化后的代码段:
// 上下文连接// decodinglow = 0;high = 1;while (abs(output - (low + high) / 2) > 1e-15) { //double 精度是 15-16位有效数字// 二分法的前提是序列有序, 由于pp_tmp是pp概率累加得来的,所以是递增的,可用二分法查找来优化。short pos0 = 0;short pos1 = len;short cur = (pos0 + pos1) / 2;while (pos1 - pos0 > 1) {if (output < pp_tmp[cur]) { // output是区间的中间值,一定不等于某区间端点pos1 = cur;cur = (pos0 + pos1) / 2;} else {pos0 = cur;cur = (pos0 + pos1) / 2;}}if (pos1 - pos0 == 1) {low = pp_tmp[pos0];high = pp_tmp[pos1];outStr.push_back(strMap[pos0]);}// 上下文连接// update pp_tmppp_tmp[0] = low;pp_tmp[len] = high;}
参考资料
- 思否:算数编码原理解析






![[图像处理]14.分割算法比较 OTSU算法+自适应阈值算法+分水岭](https://img-blog.csdnimg.cn/c02140900dfe4b1f93edc608877901a4.jpeg)