文章首发于我的个人博客
前言
这篇博客主要总结大二下课程《信息论》实验的内容。主要包含固定模式的算数编码以及自适应模式的算术编码。我将首先介绍这两种算术编码的基本思想和实现思路,然后给出具体的python代码并对代码中的一些关键点进行解释说明。
固定模式的算术编码
问题
设信源可能输出的符号是26个字母,且每个字母出现的概率为:a, b, c, d, e, f 均为0.1,其它是等概的,试编写程序可以对任意字母序列(如presentation)进行固定模式的算术编码,并进行相应的译码。
算法原理
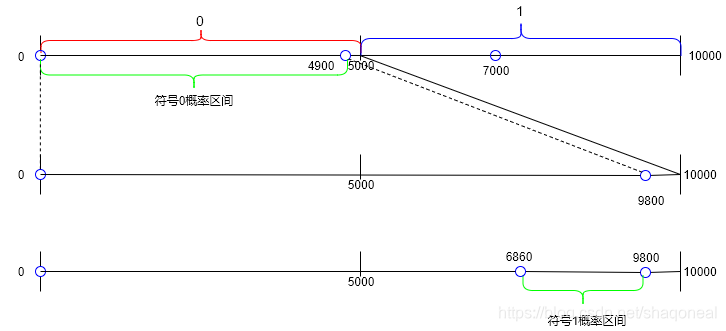
以上图为例说明固定模式算术编码的原理。首先,假设有A、B、C、D四个字符,这四个字符出现的概率分别为0.2、0.2、0.2、0.4,要求对字符序列“ADBCD”进行编码。开始编码时,概率空间为[0,1],当我们首先对A进行编码时,我们的概率空间将会缩小到字符A的区间,即[0,0.2],然后在缩小的区间内根据各个字符的概率重新分配概率空间。依次类推,当进行到最后一个字符时,我们将最后一个字符对应的概率空间作为编码区间,并且在编码区间内选择一个靠近区间上界的概率作为编码概率,利用公式 l i = l o g r 1 p ( s i ) {l_i = log_r}\frac{1}{p(s_i)} li=logrp(si)1
得到**码长。**之后将编码概率转换为与码长等长的二进制序列,即为编码的结果。
译码时,首先将二进制编码序列转换为浮点数,即还原出编码概率。然后顺序遍历编码时存储的字符概率空间改变序列与还原出的编码概率进行比较,选择相应字符概率空间对应的字符即可。这样就可以得到原字符序列。
代码
import math
from decimal import *def float2bin(x, n):'''x : float typen : bins numsreturn : list type'''bins = []while n > 0:x = x * 2if x >= 1.0:bins.append(1)else:bins.append(0)x -= int(x)n -= 1# print(bins)return binsdef bin2float(bins):'''bins: list typereturn : float type'''c = []f = -1for i in range(len(bins)):c.append(f)f -= 1num = Decimal(0.0)for i in range(len(bins)):num += Decimal(bins[i] * 2**c[i])# print(num)return numdef fixed_AC_encode(str, char, char_list):'''固定模式算术编码str: 要进行编码的字符串序列char:编码字符初始概率空间char_list: 编码过程中概率空间的变化序列return : code_length: 编码长度bins: 编码序列'''cha = char.copy()char_list.append(char.copy()) # 将初始概率空间添加进序列i = 0for s in str: # 根据字符序列中字符出现顺序不断更改概率空间p = Decimal(cha.get(s)[1] - cha.get(s)[0]) # 求概率# print('概率:', p)if i == (len(str) - 1): # 遍历到最后一个跳出# print(s)breakfront = cha.get(s)[0]for key in char:# 概率空间重新分配关键步骤cha[key] = [front + (p * char[key][0]), front + (p * char[key][1])]i += 1 # print(cha.items())char_list.append(cha.copy()) # 将更改后的概率空间添加进序列#print(cha.items())# 计算编码区间跨度,求码长interval = char_list[-1].get(str[-1])[1] - char_list[-1].get(str[-1])[0]# 选择编码概率encode_prob = interval * Decimal(0.8) + char_list[-1].get(str[-1])[0] #print(interval * Decimal(0.9), char_list[-1].get(str[-1])[0])#print(interval * Decimal(0.9)+char_list[-1].get(str[-1])[0])print('编码概率:',encode_prob) # 计算码长code_length = math.ceil(math.log2(Decimal(1) / interval))# print(code_length)bins = float2bin(encode_prob, code_length)return code_length, binsdef fixed_AC_decode(bins, char_list):'''固定模式算数解码bins:编码序列char_list:编码过程中概率空间的变化序列return: 源码'''decode_char_list = [] # 解码字符序列num = bin2float(bins) # 将编码序列转换为概率# 解码for char in char_list: # 遍历概率空间序列for key in char:if num >= char[key][0] and num <= char[key][1]:# print(key)decode_char_list.append(key)# print(len(char_list))decode_chars = "".join(decode_char_list)return decode_charsdef init():char = {}chars = "abcdefghijklmnopqrstuvwxyz"for i in range(len(chars)):if i <= 5:char[chars[i]] = [Decimal(i) * Decimal(0.1), Decimal(i + 1) * Decimal(0.1)]else:char[chars[i]] = [Decimal(0.6) + (i - 6) * (Decimal(0.4 / 20)), \Decimal(0.6) + (i - 5) * (Decimal(0.4 / 20))]return charif __name__ == '__main__':strList = input("请输入字符序列:").lower()print('字符序列长度:', len(strList))# 根据源码长度动态调整浮点位数getcontext().prec = math.ceil(len(strList) * 5)char = init()char_list = [] # 编码过程中概率空间的变化序列code_length, bins = fixed_AC_encode(strList, char, char_list)print('码长:',code_length)bins_new = [str(x) for x in bins]print('编码结果: ' + "".join(bins_new))decode_chars = fixed_AC_decode(bins, char_list)print('解码结果: ' + decode_chars)
运行结果如下
在代码中有几个需要注意的点我在此强调一下。
首先,代码第二行引入了python内置的decimal库,主要是为了解决python内置的浮点型精度丢失的问题(python内置浮点型保留小数点后17位)。因为当要编码的字符序列长度过长时,在计算各个字符的概率空间时由于浮点数精度的限制在更新过几轮之后遍不再改变,会导致编码错误,因此可以在在代码中看到使用了Decimal()将普通的浮点型转换为高精度的浮点型。需要注意的是,Decimal可以自定义浮点数的位数,基于这一点,我们可以根据输入的码长来动态的调整浮点数的位数,即在代码的122行getcontext().prec = math.ceil(len(strList) * 5),在这里我设置浮点位数为码长的五倍(也可自己通过输入一些测试序列来得到更为合适的值)。
其次,代码第4行和第22行定义了两个函数,分别为浮点数转二进制和二进制转浮点数函数。注意函数内部也需要将普通浮点型转为Decimal型。
下面附一张算法流程图,帮助理解代码
自适应模式的算术编码
问题
设信源可能输出的符号是26个字母,且每个字母出现的概率为:a, b, c, d, e, f 均为0.1,其它是等概的,试编写程序可以对任意字母序列(如presentation)进行固定模式的算术编码,并进行相应的译码。
算法原理
由上图说明自适应算数编码的算法原理。首先,假设有a、b、c三个字符,编码之前每个信源符号出现的频率相等,例如都等于1,利用字符出现频率除以总字符频率即可得到每个字符的概率。如果从输入字符序列读取一个字符,则该字符的频率加1,并且更新该字符的概率以及所有字符的概率空间。以上图为例,有a、b、c三个字符,要对字符序列“bccb”进行编码,初始信源字符频率都为1,概率都为1/3。当读入第一个字符’b’时,字符’b’的频率变为2,概率变为2/4,然后将所有字符的概率空间缩小到字符原’b’的概率空间内,并重新分分配每个字符的概率及概率区间。依次类推,当读取到最后一个字符时,直接取出该字符的概率区间作为编码区间,然后选择靠近区间上界的概率作为编码概率, 利用公式 l i = l o g r 1 p ( s i ) {l_i = log_r}\frac{1}{p(s_i)} li=logrp(si)1
得到**码长。**之后将编码概率转换为与码长等长的二进制序列,即为编码的结果。
译码时,与固定模式的算数编码思想相同。首先将二进制编码序列转换为浮点数,即还原出编码概率。然后顺序遍历编码时存储的字符概率空间改变序列与还原出的编码概率进行比较,选择相应字符概率空间对应的字符即可。这样就可以得到原字符序列。
代码
import math
from decimal import *def float2bin(x, n):'''x : float typen : bins numsreturn : list type'''bins = []while n > 0:x = x * 2if x >= 1.0:bins.append(1)else:bins.append(0)x -= int(x)n -= 1# print(bins)return binsdef bin2float(bins):'''bins: list typereturn : float type'''c = []f = -1for i in range(len(bins)):c.append(f)f -= 1num = Decimal(0.0)for i in range(len(bins)):num += Decimal(bins[i] * 2**c[i])# print(num)return numdef adaptive_AC_encode(strList, char, char_frequence, char_list):'''自适应模式算术编码strList: 要进行编码的字符串序列char: 编码字符初始概率空间char_frequence : 字符出现频率char_list : 编码过程中概率空间的变化序列return : code_length: 编码长度bins: 编码序列'''sum_length = 26 # 字符累计频率,初始为26cha = char.copy()char_list.append(char.copy()) # 将初始概率空间添加进序列i = 0for s in strList: # 根据字符序列中字符出现顺序不断更改概率空间p = Decimal(cha.get(s)[1] - cha.get(s)[0]) # 求概率char_frequence[s] += 1 # 字符频率增加sum_length += 1if i == (len(strList) - 1): # 遍历到最后一个跳出# print(s)breakfront = cha.get(s)[0]for key in char:# 概率空间重新分配关键步骤cha[key] = [front, front + p * Decimal(char_frequence[key] / sum_length)]front += p * Decimal(char_frequence[key] / sum_length)i += 1 char_list.append(cha.copy()) # 将更改后的概率空间添加进序列# 计算编码区间跨度,求码长interval = char_list[-1].get(strList[-1])[1] - char_list[-1].get(strList[-1])[0]# 选择编码概率encode_prob = interval * Decimal(0.9) + char_list[-1].get(strList[-1])[0] print("编码概率:", encode_prob) # 计算码长code_length = math.ceil(math.log2(Decimal(1) / interval))# print("码长:", code_length)bins = float2bin(encode_prob, code_length)return code_length, binsdef adaptive_AC_decode(bins, char_list):'''自适应模式算数解码bins:编码序列char_list:编码过程中概率空间的变化序列return: 源码'''num = bin2float(bins) # 将编码序列转换为概率decode_char_list = [] # 解码字符序列# 解码for char in char_list: # 遍历概率空间序列for key in char:if num >= char[key][0] and num <= char[key][1]:# print(key)decode_char_list.append(key)# print(len(char_list))decode_chars = "".join(decode_char_list)# print(decode_chars)return decode_charsdef init():char = {}char_frequence = {}chars = "abcdefghijklmnopqrstuvwxyz"for i in range(len(chars)):char[chars[i]] = [Decimal(i) * Decimal(1 / 26), Decimal(i + 1) * Decimal(1 / 26)]char_frequence[chars[i]] = 1return char, char_frequenceif __name__ == '__main__':strList = input("请输入字符序列:").lower()print('字符序列长度:', len(strList))# 根据源码长度动态调整浮点位数if len(strList) <=15:getcontext().prec = math.ceil(len(strList) * 5)else:getcontext().prec = math.ceil(len(strList) * 1.7)char, char_frequence = init()char_list = [] # 编码过程中概率空间的变化序列code_length, bins = adaptive_AC_encode(strList, char, char_frequence, char_list)print('码长:',code_length)bins_new = [str(x) for x in bins]print('编码结果: ' + "".join(bins_new))decode_chars = adaptive_AC_decode(bins, char_list)print('解码结果: ' + decode_chars)
运行结果如下
自适应模式的算术编码与固定模式的算术编码的代码结构大体上相同,主要是更新字符概率空间的方法不同,在该处注意即可。
下面附一张算法流程图,帮助理解代码



![[图像处理]14.分割算法比较 OTSU算法+自适应阈值算法+分水岭](https://img-blog.csdnimg.cn/c02140900dfe4b1f93edc608877901a4.jpeg)