前言:Local Response Normalization(LRN)技术主要是深度学习训练时的一种提高准确度的技术方法。其中caffe、tensorflow等里面是很常见的方法,其跟激活函数是有区别的,LRN一般是在激活、池化后进行的一种处理方法。LRN归一化技术首次在AlexNet模型中提出这个概念。通过实验确实证明它可以提高模型的泛化能力,但是提升的很少,以至于后面不再使用,甚至有人觉得它是一个“伪命题”,因而它饱受争议。
一、诞生灵感以及背景介绍
1.1 局部归一化的灵感来源
在神经生物学中,有一个概念叫做侧抑制(lateral inhibitio ),指的是被激活的神经元会抑制它周围的神经元,而归一化(normalization)的的目的不就是“抑制”吗,两者不谋而合,这就是局部归一化的动机,它就是借鉴“侧抑制”的思想来实现局部抑制,当我们使用RELU损失函数的时候,这种局部抑制显得很有效果。
1.2 归一化的好处
(1)为了后面数据处理的方便,归一化的确可以避免一些不必要的数值问题。
(2)为了程序运行时收敛加快。 下面图解。
(3)同一量纲。样本数据的评价标准不一样,需要对其量纲化,统一评价标准。这算是应用层面的需求。
(4)避免神经元饱和。啥意思?就是当神经元的激活在接近0或者1时会饱和,在这些区域,梯度几乎为0,这样,在反向传播过程中,局部梯度就会接近0,这会有效地“杀死”梯度。
(5)保证输出数据中数值小的不被吞食。
1.3 实验总结
由于LRN模仿生物神经系统的侧抑制机制,对局部神经元的活动创建竞争机制,使得响应比较大的值会更大,提高了模型的泛化能力,Hinton在ImageNet中的实验准确率分别提升了1.4%和1.2%。
二、LRN的首次提出与成功应用
LRN归一化技术首次在AlexNet模型中提出这个概念。AlexNet将LeNet的思想发扬光大,把CNN的基本原理应用到了很深很宽的网络中。AlexNet主要使用到的新技术点如下。
(1)成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。虽然ReLU激活函数在很久之前就被提出了,但是直到AlexNet的出现才将其发扬光大。
(2)训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
(3)在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
(4)提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。LRN通过在相邻卷积核生成的feature map之间引入竞争,从而有些本来在feature map中显著的特征在A中更显著,而在相邻的其他feature map中被抑制,这样让不同卷积核产生的feature map之间的相关性变小。
三、LRN的公式详解
Hinton在2012年的Alexnet网络中给出其具体的计算公式如下:
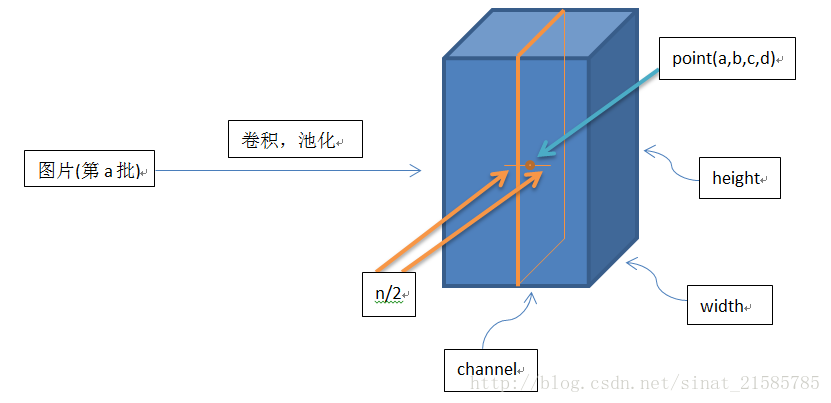
这个公式中的a表示卷积层(包括卷积操作和池化操作)后的输出结果,这个输出结果的结构是一个四维数组[batch,height,width,channel],这里可以简单解释一下,batch就是批次数(每一批为一张图片),height就是图片高度,width就是图片宽度,channel就是通道数可以理解成一批图片中的某一个图片经过卷积操作后输出的神经元个数(或是理解成处理后的图片深度)。ai(x,y)表示在这个输出结构中的一个位置[a,b,c,d],可以理解成在某一张图中的某一个通道下的某个高度和某个宽度位置的点,即第a张图的第d个通道下的高度为b宽度为c的点。论文公式中的N表示通道数(channel)。a,n/2,k,α,β分别表示函数中的input,depth_radius,bias,alpha,beta,其中n/2,k,α,β都是自定义的,特别注意一下∑叠加的方向是沿着通道方向的,即每个点值的平方和是沿着a中的第3维channel方向的,也就是一个点同方向的前面n/2个通道(最小为第0个通道)和后n/2个通道(最大为第d-1个通道)的点的平方和(共n+1个点)。而函数的英文注解中也说明了把input当成是d个3维的矩阵,说白了就是把input的通道数当作3维矩阵的个数,叠加的方向也是在通道方向。
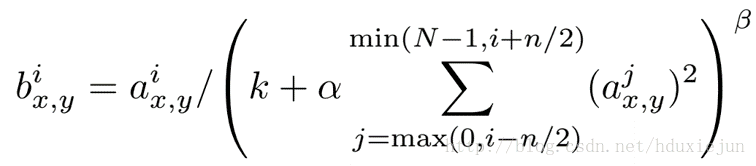
公式看上去比较复杂,但理解起来非常简单。i表示第i个核在位置(x,y)运用激活函数ReLU后的输出,n是同一位置上临近的kernal map的数目,N是kernal的总数。参数K,n,alpha,belta都是超参数,一般设置k=2,n=5,aloha=1*e-4,beta=0.75。

四、tensorflow中LRN实现
tensorflow中的LRN,公式如下:
sqr_sum[a, b, c, d] = sum(input[a, b, c, d - depth_radius : d + depth_radius + 1] ** 2)
output = input / (bias + alpha * sqr_sum) ** beta这里关于求batch的sqr_sum还是比较复杂了,主要意思是在一个3维空间范围内,取所有像素的点,求平方和,直接套用吧,以alexnet的论文为例,输入暂且定为 [batch_size, 224, 224, 96],这里224×224是图片的大小,经过第一次卷积再经过ReLU,就是LRN函数的输入。运行Tensorflow测试代码:
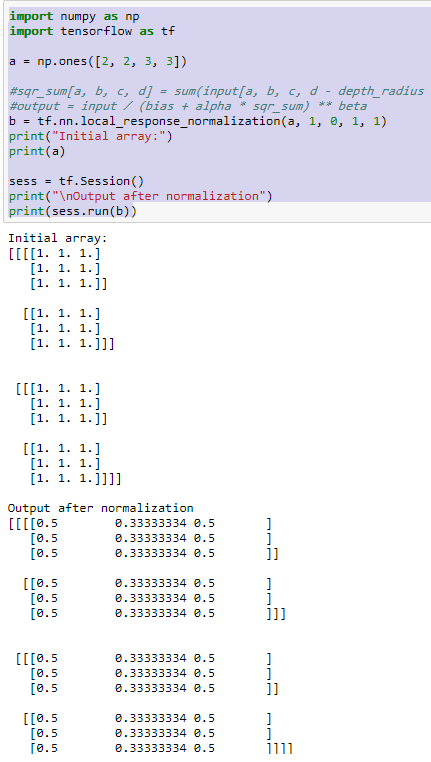
import numpy as np
import tensorflow as tfa = np.ones([2, 2, 3, 3])#sqr_sum[a, b, c, d] = sum(input[a, b, c, d - depth_radius : d + depth_radius + 1] ** 2)
#output = input / (bias + alpha * sqr_sum) ** beta
b = tf.nn.local_response_normalization(a, 1, 0, 1, 1)
print("Initial array:")
print(a)sess = tf.Session()
print("\nOutput after normalization")
print(sess.run(b))
这里输入a,可以理解为一个4维张量,形象点就是 2*2 矩阵,该矩阵每个元素又是 3*3的矩阵。所有的初始值都为1。运行结果如下:
下面有一个简单的图像展示这个,
画个简单的示意图:
五、后期争议
在2015年 Very Deep Convolutional Networks for Large-Scale Image Recognition.提到LRN基本没什么用。

因而在后面的Googlenet,以及之后的一些CNN架构模型,LRN已经不再使用,因为出现了更加有说服能力的块归一化,也称之为批量归一化,即BN。




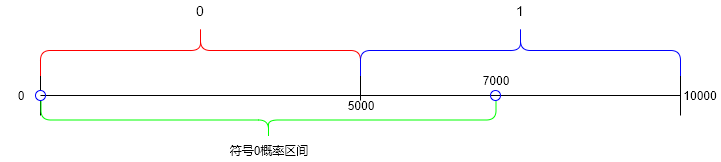
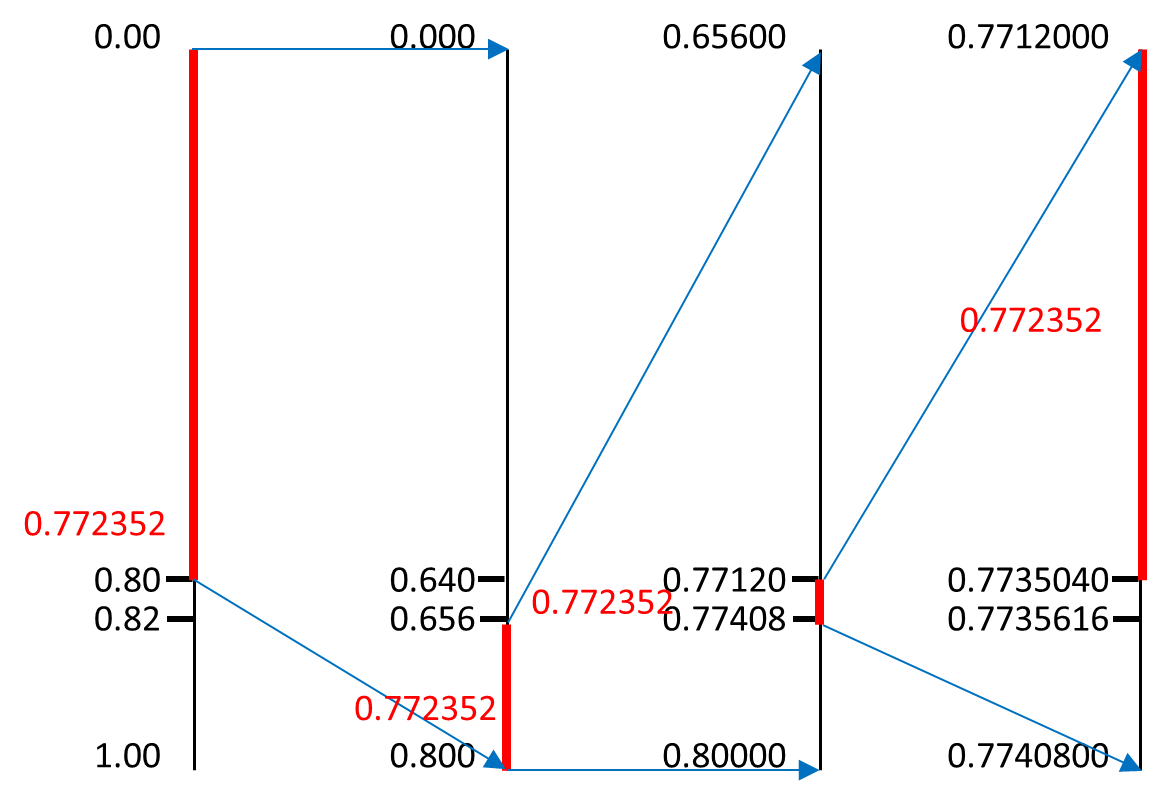



![[图像处理]14.分割算法比较 OTSU算法+自适应阈值算法+分水岭](https://img-blog.csdnimg.cn/c02140900dfe4b1f93edc608877901a4.jpeg)