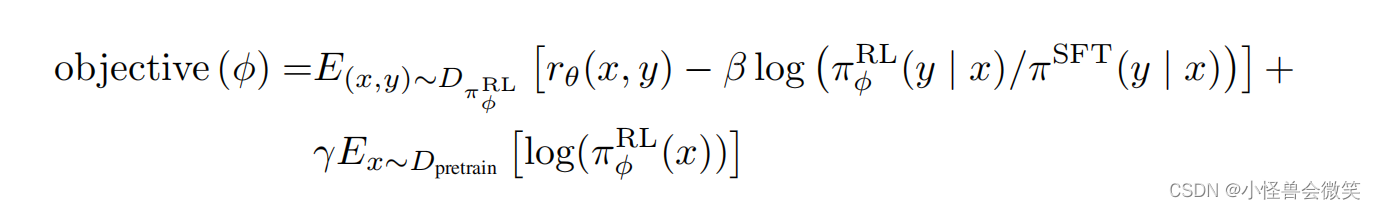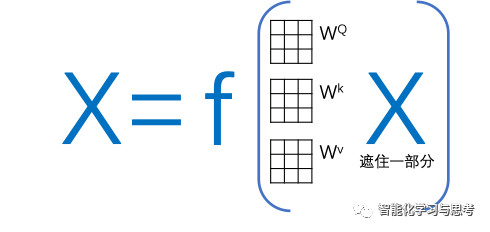Datawhale干货
作者:Ben,中山大学,Datawhale成员
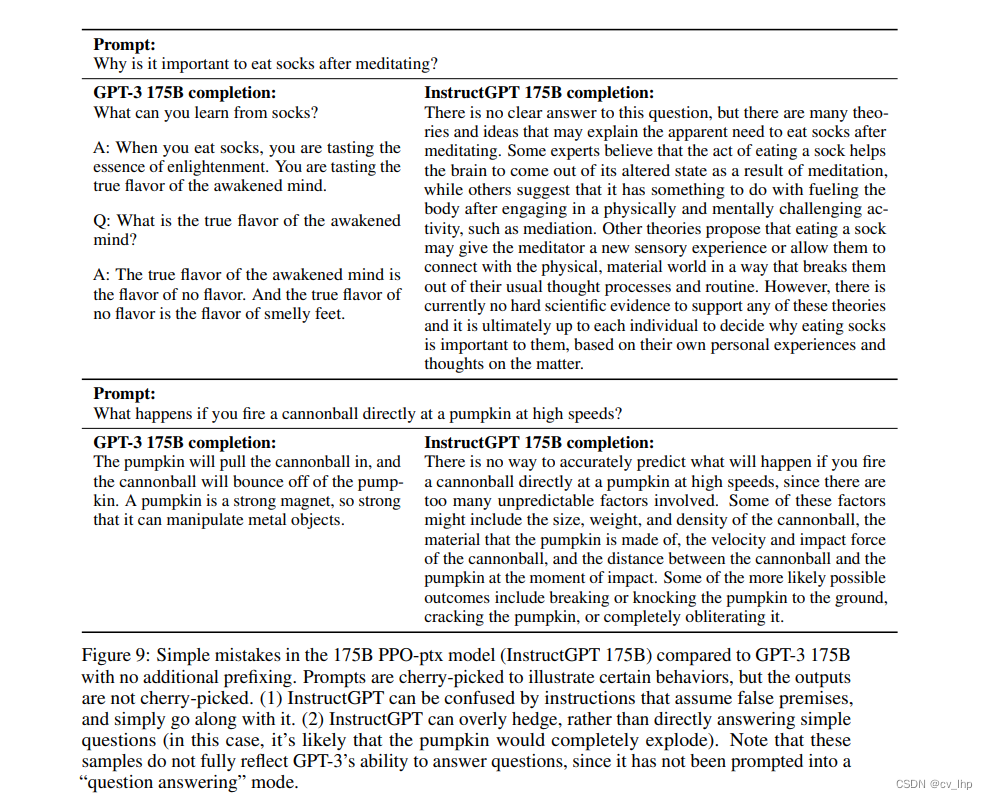
最近ChatGPT火出圈了,它和前阵子的Stable Diffusion(AIGC)一样成为社交媒体上人们津津乐道的话题。“ChatGPT要取代谷歌搜索了?”“ChatGPT要让程序员失业了吗?”……类似的标题又一次刺激了我们的神经。作为一名码农,我对后一个标题其实是嗤之以鼻的。无论ChatGPT是用了什么样的“魔法”,仅从目前展现的能力来看,它学会的顶多就是熟练使用编程语言的API,去实现某个函数完成人类给定的特定小任务。在真实的项目场景下,程序员通常要接过一个含糊不清的需求,梳理其中的每个细节直至形成逻辑闭环,再将其抽象成一个个特定任务并实现功能,现有AI至多能帮上最后一个小阶段;更别提真正让程序员头大的往往是并发、事务一致性等问题,这些都是现有AI无法解决的。
但是作为一名深度学习爱好者,我对ChatGPT表现出来的能力是惊叹的。无论是OpenAI提供的示例还是社交媒体上的各路花活,都让我更新了以往对AI语言模型特有的“人工智障”的认识。因此我其实十分好奇,ChatGPT的“魔法”原理是什么?遗憾的是,我在中文互联网上并没有找到对这个工作很好的解读文字,而直接看论文既费事又不是特别能理解。在一些网上优质解读视频的帮助下,我逐渐理解了所谓的“魔法”究竟是什么,并尝试梳理成如下的文字。
ChatGPT的“魔法”原理
由于ChatGPT并没有放出论文,我们没法直接了解ChatGPT的设计细节。但它的blog中提到一个相似的工作InstructGPT,两者的区别是ChatGPT在后者的基础上针对多轮对话的训练任务做了优化,因此我们可以参考后者的论文去理解ChatGPT。
然而,InstructGPT的论文由25页正文和43页附录组成,所以本文并不试图去讲清包括训练策略在内的每个细节。为了保证梳理的完整性,本文将分为上下两个部分:第一部分参考了Youtube上的 李宏毅 和 陈蕴侬 老师,旨在讲清InstructGPT的改进思路;第二部分参考了B站UP主弗兰克甜,试图转述他对ChatGPT的深刻理解。
InstructGPT的改进思路
对任何一篇工作的理解,都要回归到两个问题:一是它相比以往的工作有哪些改进,二是这些改进基于什么设计思路或者说有什么用。对InstructGPT的简单理解,可以是基于人类反馈的强化学习(RLHF)手段微调的GPT。那么我们去搞懂RLHF,其实就可以大概了解InstructGPT了。
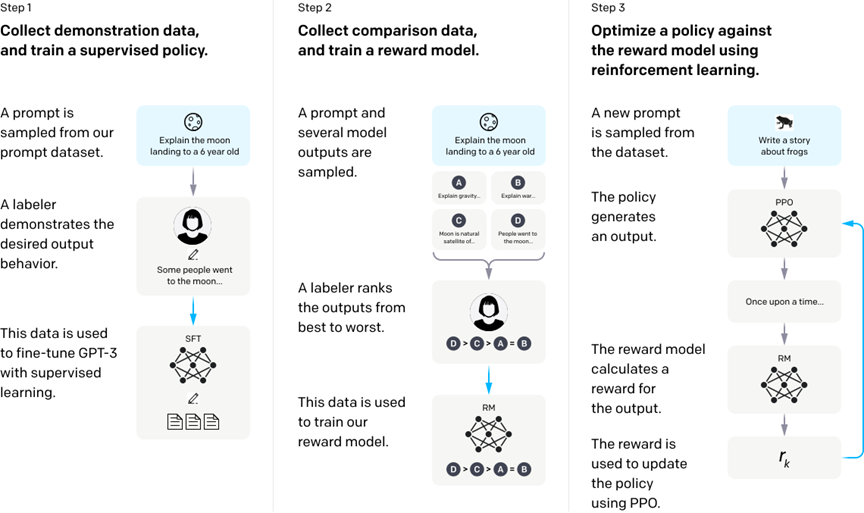
根据下边的论文图片,我们可以知道InstructGPT的训练可以分为三个阶段:
利用人类的标注数据(demonstration data)去对GPT进行有监督训练,不妨把微调好的GPT叫做SFT;
收集多个不同(如4个)的SFT输出,这些输出基于同一个输入,然后由人类对这些输出进行排序并用来训练奖赏模型(RM);
由RM提供reward,利用强化学习的手段(PPO)来训练之前微调过的SFT。
一个需要补充的细节是,RM是会保持更新的,因此阶段2与阶段3其实是递交进行的。
由于我此前并不是特别了解强化学习,因此一开始读论文时尚能理解阶段1和3,但完全搞不懂阶段2在说什么。相信不少读者也有类似的疑问:
InstructGPT为什么要做这样的改进,或者说它的novelty是什么?
为什么要训练一个RM,这个奇奇怪怪的RM为什么能用来充当奖赏函数?
人类对模型的多个输出做个排序,为什么就能够提供监督信号,或者说在训练RM时如何怎么做到loss的梯度回传?
可能部分人还有其它疑问,但我相信回答了这三个问题,应该也能帮助理解。
第一个问题其实在ChatGPT的blog中也有回答。这两个模型的改进思路,都是尽可能地对齐(Alignment)GPT的输出与对用户友好的语言逻辑,即微调出一个用户友好型GPT。以往的GPT训练,都是基于大量无标注的语料,这些语料通常收集自互联网。我们都知道,大量“行话”“黑话”存在于互联网中,这样训练出来的语言模型,它可能会有虚假的、恶意的或者有负面情绪等问题的输出。因此,一个直接的思路就是,通过人工干预微调GPT,使其输出对用户友好。
为了回答第二个问题,其实要稍微拓展下强化学习相关的一些研究。我们都知道,经典的强化学习模型可以总结为下图的形式:
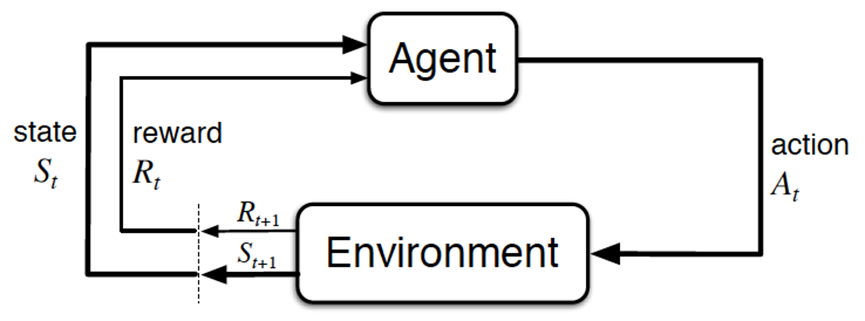
具体来说,智能体(Agent)就是我们要训练的模型,而环境是提供reward的某个对象,它可以是AlphaGo中的人类棋手,也可以是自动驾驶中的人类驾驶员,甚至可以是某些游戏AI里的游戏规则。强化学习理论上可以不需要大量标注数据,然而实际上它所需求的reward存在一些缺陷,这导致强化学习策略很难推广:
reward的制定非常困难。比如说游戏AI中,可能要制定成百上千条游戏规则,这并不比标注大量数据来得容易;
部分场景下reward的效果不好。比如说自动驾驶的多步决策(sequential decision)场景中,学习器很难频繁地获得reward,容易累计误差导致一些严重的事故。
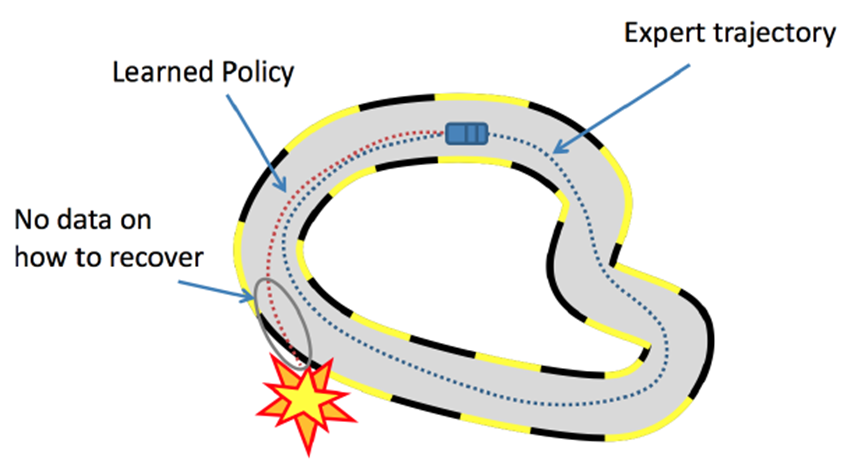
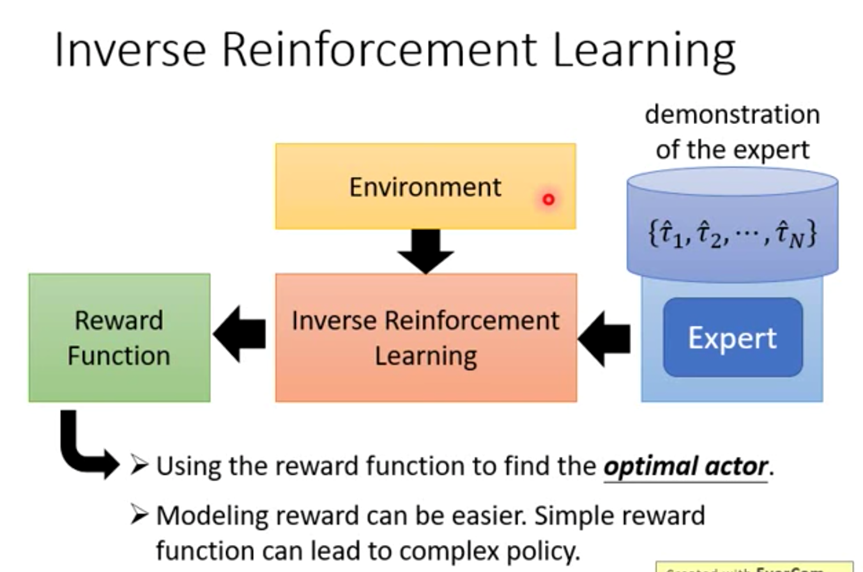
想把上面的多步决策问题讲清是一件困难的事,而且我本人也不是十分理解。总之,为了解决这些问题,模仿学习(Imitation Learning)应运而生。模仿学习的思路是不让模型在人类制定的规则下自己学习,而是让模型模仿人类的行为。有的人可能会疑惑,这与监督学习有什么异同吗?我认为相同点在于都要收集人类的标注数据,不同点在于模仿学习最终是以强化学习的形式进行的;简单来说,模仿学习将强化学习的Environment替换成一个Reward Model,而这个RM是通过人类标注数据去训练得到的。其中,逆强化学习就是模仿学习的一种形式,如下图。(PS:由于我实在是不了解强化学习领域,所以这里的理解可能不准确)
在回答了第二个“为什么要训练RM”的问题后,就要接着回答“如何训练RM”。如下图,训练RM的核心是由人类对SFT生成的多个输出(基于同一个输入)进行排序,再用来训练RM。按照模仿学习的定义,直观上的理解可以是,RM在模仿人类对语句的排序思路,或者按照OpenAI团队论文《Learning from Human Preferences》的说法是,模仿人类的偏好(Preference)。那么到底是如何模仿的呢,或者说如何实现梯度回传?
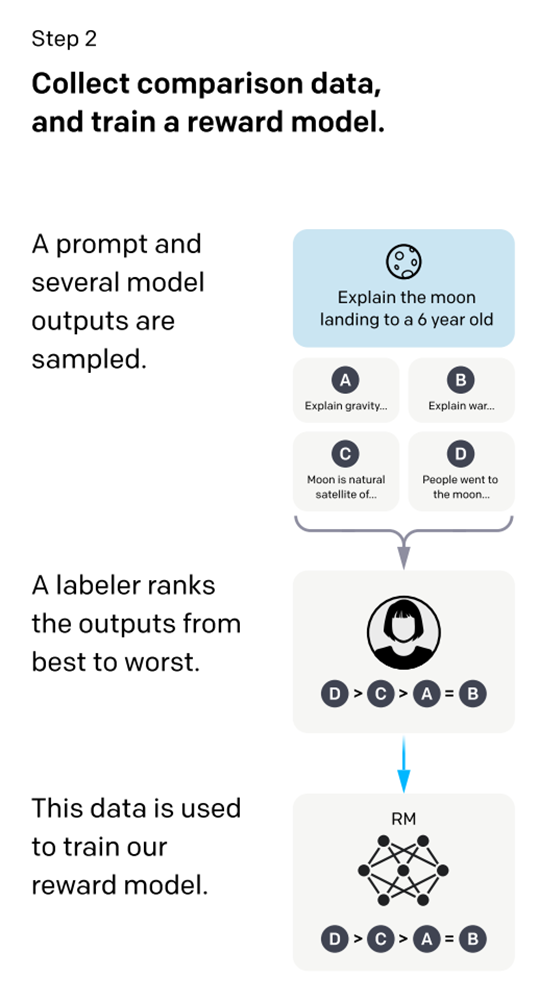
这里我们代入一个场景。如上图,SFT生成了ABCD四个语句,然后人类对照着Prompt输入来做出合适的排序选择,如D>C>A=B。这里的排序实质是人类分别给四个语句打分,比如说D打了7分,C打了6分,A和B打了4分。为了让RM学到人类偏好(即排序),可以四个语句两两组合分别计算loss再相加取均值,即分别计算个loss。具体的loss形式如下图。

需要说明的是,是Prompt输入,是SFT的输出,是RM的输出。其中总是语句组合对中打分更高的,反之。通过这种形式的梯度回传,RM逐渐学会了给D这类语句打高分,给AB这类语句打低分,从而模仿到了人类偏好。
到了这一步,不妨可以这么简单理解RLHF:所谓的人类反馈的强化学习,某种意义上来说,就是由人类的打分来充当reward。那么,虽然我们已经知道reward的设计确实比较麻烦,但为什么要用RLHF的形式而不是其它形式?以及ChatGPT是如何将这一套框架应用到多轮对话场景中的?
对ChatGPT的进一步理解
这一个部分我们回答两个问题:一,为什么是RLHF?二,RLHF是如何运用到ChatGPT中的多轮对话场景中的?至于为什么要问这两个问题,以及这两个问题如何更进一步帮助理解ChatGPT,将会在下文阐述。
首先,为什么是RLHF?我们当然知道,强化学习(RL)的reward有一些缺陷,所以有人提出了模仿学习(IL),而上文提到的RM与IL有一定的联系。那么如何理解RLHF,RL和IL之间的区别与联系?
这里我们举一个具体的场景,当我们想要训练一个能够对话的机器人时,我们可以怎么做?在一般的强化学习设定中,我们人类可以扮演Environment的角色,衡量机器人每句对话的好坏(reward),但这显然非常折磨人。即,确定一个合适的Reward机制是很困难的。而在模仿学习(如逆强化学习)设定中, 人类不去对机器人的对话做评价,而是机器人反过来模仿人类的对话方式。具体来说,可以从网上或者其它渠道收集大量历史对话数据来训练一个奖赏模型(RM)。
看起来模仿学习很好地解决了Reward机制的问题,然而同样的,它也带来了如何收集高质量数据训练RM的问题。还是以对话机器人举例,如果只是简单地拉家常,那么找一些稍微培训过的普通人就可以了;但是如果要解决医疗对话等场景,显然普通人不足以胜任,而一名有经验的医生的标注数据成本可能高于十名普通人的。因此,一个合理的思路是,如何借鉴监督学习中降低标注成本的思路,来降低RM的训练成本。
在我看来,RLHF中的rank就好比监督学习中的弱标注——它并不提供直接的监督信号。但通过学习简单的排序,RM可以学到人类的偏好。那怎么去理解这里的“偏好”呢?打个比方,有一家冰箱工厂生产了好几种类型的冰箱,虽然这些客户中没有一个懂得如何造冰箱的(或者说他们不需要懂),但他们可以通过消费行为,让厂商明白消费者对冰箱类型的“偏好”,从而引导冰箱厂商生产销量更好的冰箱。

既然RLHF能很好地解决RL甚至IL的一些问题,也在InstructGPT中取得了很好的效果。那么,是否可以顺理成章地将之迁移到多轮对话场景中呢?
我们可以从强化学习的假设出发去理解这个问题。“我们都知道”,以PPO为代表的强化学习模型,基于马尔可夫性的假设。简单理解马尔科夫性就是,它将来的状态只取决于现在,与过去无关。也就是说,马尔可夫性有一个很重要的特点:无记忆性。然而,在多轮人机对话场景中,模型却应该具备部分可观测马尔可夫性,即要求语言模型有“记忆性”。这理解起来也比较直观,在多轮对话场景里,存在某一轮对话中的代词指向上一轮对话中的某个人或物的可能,假如模型不具备记忆性,那就无法很好地处理这种问题。显然,强化学习的假设与多轮对话场景的相背,不做一些优化的话很难直接应用。那么进一步的问题来了,ChatGPT是如何做优化的呢?
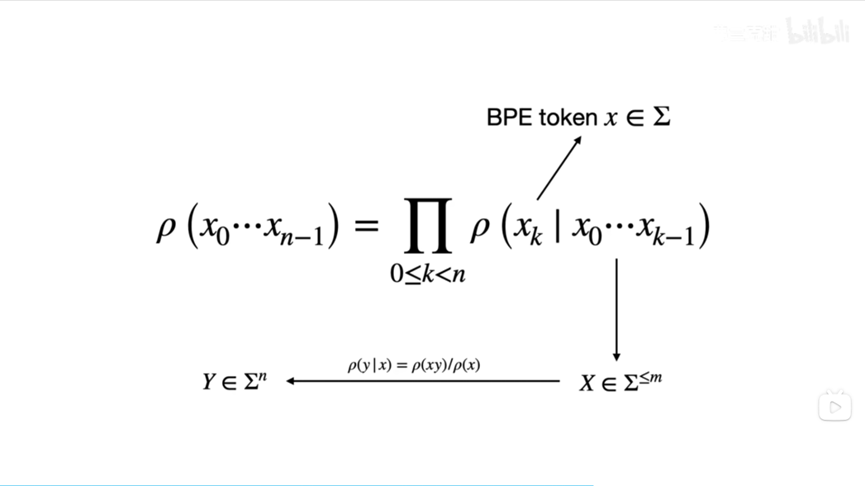
这里我们先从自然语言任务中最基本的语言模型简单说起。一个语言模型大概是说,当你给定前面的若干个词后,它会给你下一个词;而当你有了下一个词后,它会再给你接一个词,以此递推。这就好比我们使用手机输入法,你打出一些词句后,输入法会提供若干个候选词——这里的手机输入法其实就是一个语言模型。那么我们如何利用这个最基本的语言模型来建模多轮对话问题呢?实际上,我们向ChatGPT提出的问题,可以看成一句话,或者说是下图的输入。然后我们可以将ChatGPT给出的答案,抽象成下图的输出。而ChatGPT这类语言模型,提供了若干个类似手机输入法的“候选句”,每个候选句对应的概率不一。所谓的语言模型的训练,其实就是让模型调整候选句对应的概率,使我们人类希望输出的候选句的概率尽可能大,而不希望输出的概率尽可能小。
那么这个语言模型和强化学习又有什么样的联系呢?在强化学习中,我们确实有智能体/模型(Agent)和环境(Environment)交互这样的范式。但是在ChatGPT所使用的这种训练方式中,环境从某种意义上说被另一个模型取缔了(即前面提到的RM)。如下图,图中的状态State是之前提到的输入语句,而当智能体拿到一个,它给出的动作action其实是下一个单词。注意,GPT确实可以输出一整句话,但其实要完成这个最终的输出,需要做若干次如图所示的action。当环境(或RM)接收到它给出的单词后,会把这个单词放到已有的单词序列末尾,然后再把这个新的单词序列还给智能体,之后依次类推。打个比方,这里的智能体就是手机输入法,而环境就是使用输入法的用户。用户所做的事情,就是当输入法给出一系列候选词后,基于某种偏好选择某个词,然后让手机输入法再去猜下一个词,直到输入法把整个句子猜出来为止。这里我们明白了在语言模型场景下,强化学习的状态和动作对应什么,那么什么是奖赏Reward呢?更进一步地,ChatGPT中的Reward,是否就是前面所提到的RM呢?
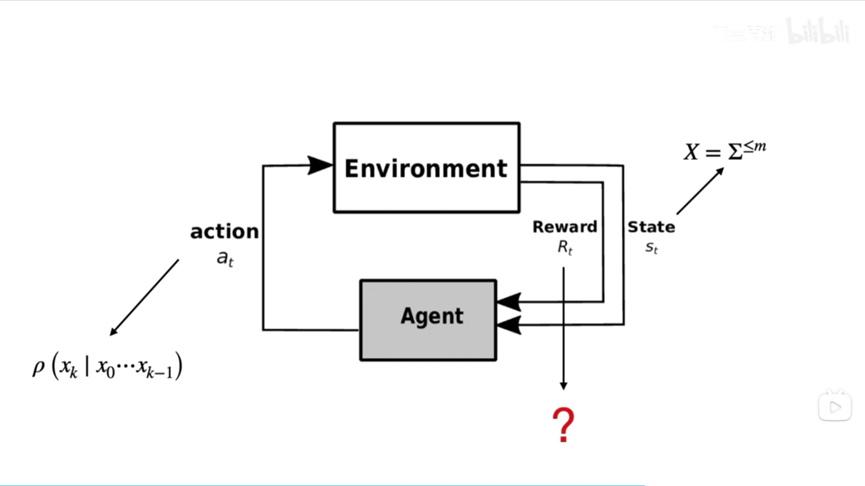
我们之前已经了解到,RM学到的其实是人类的SFT多个输出结果的排序,即人类对语句的偏好。它其实直接学到的,就是人类对语句的打分。那么这种RM模型是否可以直接对应强化学习中的Reward呢?实际上不全是。在下图InstructGPT给出的奖赏函数中,它的一部分确实是RM模型根据学到的人类偏好给出的打分,而另一部分则是参与了强化学习的ChatGPT和它的原始版本SFT的某种差距——这里我们不希望这种差距太大。之所以要加入后边的偏置项,是因为我们害怕ChatGPT在强化学习的训练过程中过于放飞自我,学会了通过某种刁钻的方式取悦人类,而不是老老实实地根据人类的问题给出正确答案。
同时,后面的偏置项可以被看作KL散度,而KL散度可以拆分成交叉熵减去熵的形式。注意这里是交叉熵减去熵,那么在整个奖赏函数中,熵前面的符号为正——这体现了强化学习的一种思想,即让策略的熵在允许的范围内尽可能大,这可以促进策略的探索。
但是,这个奖赏函数是对整个输入语句和整个输出语句而言的,而我们又在之前讨论过,智能体是根据一个一个词来去拼凑出整个回答的。图中的奖赏函数只能给出完整回答的奖赏,那么在智能体生成回答的过程中,每个动作action给出的词对应的奖赏是什么呢?

这个细节在InstructGPT中并没有给出。幸运的是,OpenAI团队的另一篇论文《Learning from summarize from Human feedback》中的一个引脚标注给出了关于这个疑问的答案。作者说,奖赏模型只在最终生成回答之后才给出奖赏,在中间的过程中是不给出奖赏的。在这里作者没有使用回答一词,而是使用总结一词,因为它的任务是将一篇长文章进行归纳总结。顺着这位作者的思路,只有在ChatGPT输出了EOS token的时候,整个轨迹才结束(EOS token是自然语言处理中用来表示一段话结束的标志)。

这里我们可以梳理下RLHF和GPT的本质关系。实际上,这里使用RLHF就是为了解决我们无法对一个离散的训练进行求导的问题。而使用强化学习来解决这个问题也不是ChatGPT的独创:早在2016年SeqGAN的作者就已经使用了这样的方法了。因此我们可以从问题本质的角度去这么理解ChatGAN:它就是把Transformer和“SeqGAN”结合在一起。当然这个“SeqGAN”并不是标准版本,因为它不是像模仿学习那样通过示教来学习,而是通过人类的偏好来进行学习。从问题本质上看,ChatGPT与之前的工作的最大不同,就体现在它使用了SeqGAN进行微调。(PS:能力有限只能全盘照搬UP主观点,但这些对我非常有启发,因为我在读论文时也感觉ChatGPT使用到的强化学习,有点GAN的味道~)

最后再让我们回顾梳理下第二个问题:RLHF是如何运用到ChatGPT中的多轮对话场景中的?由于多轮对话要求语言模型有记忆性,因此无法直接使用强化学习。这里的矛盾具体体现在了奖赏函数中:ChatGPT的奖赏函数是针对GPT的一整个输入语句 和一整个输出语句 而言的;而ChatGPT的语言模型在强化学习的训练策略中,每个action其实输出的是一个个词语 。因此,OpenAI的团队可能是采取不对序列的中间生成给予reward的方式解决上文提到的矛盾,而这种解决方式十分接近SeqGAN的思路。
作者后记
通过梳理完这篇ChatGPT的解读文章后,我对ChatGPT有了更深刻细致的理解。我还记得一开始看到UP主弗兰克甜的视频时,简直惊为天人,这也促使我耗费大量精力梳理出这篇文章。一个想升华的点是,我们对技术尤其是AI其实要抱着即尊重又亲近的态度,不要是敬畏,更别是鄙视。我对人工智能的发展长期看好,但目前也不太可能出现跳脱式的新技术,所有的技术都是在迭代发展中慢慢成长的。最后由于我的能力有限,这篇文章可能没法照顾到方方面面的细节。
参考链接:
1. https://www.bilibili.com/video/BV1zW4y1g7pQ/?share_source=copy_web&vd_source=fe0ed33242ba9d84a6e7da7e017223c2
2. https://www.youtube.com/watch?v=e0aKI2GGZNg
3. https://www.youtube.com/watch?v=ORHv8yKAV2Q

整理不易,点赞三连↓