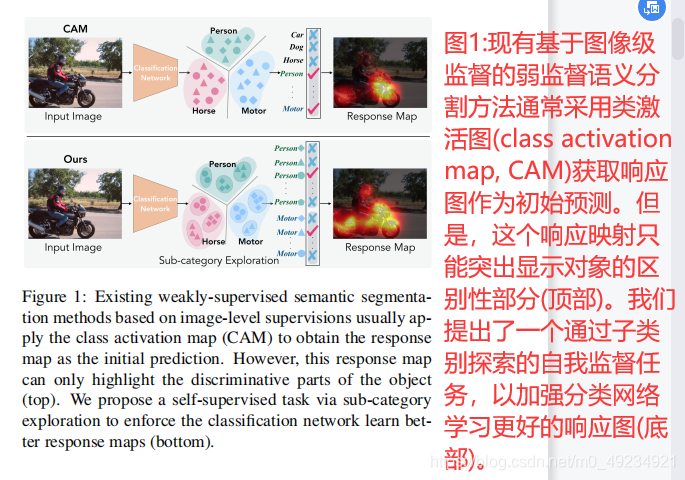
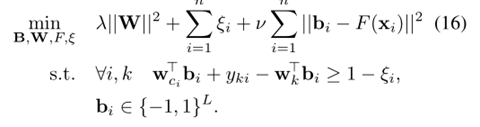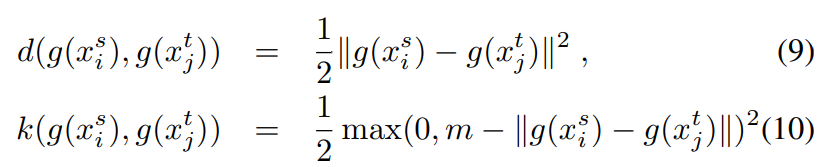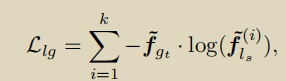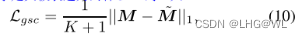半监督学习任务主要分为半监督聚类、半监督分类、半监督回归等问题,我们主要针对半监督分类问题。
半监督学习的假设
- 基于低密度假设
模型的决策边界不应该将该密度区域划分开,而应该处在低密度区域内。 - 基于平滑化假设
输入空间中,距离相近的两个样本应该有相同的标签。

平滑化与低密度假设 - 基于流形假设
data points on the same low-dimensional manifold should have the same label.
流形假设是指具有相似性质的示例,其通常处于较小的局部领域,因此标记也十分相似,这种假设反映了决策函数的局部平滑性。
 流形假设
流形假设 - 基于聚类假设
位于同一个簇中的样本往往具有相似的标签,而处于不同簇中的样本其标签往往不同。
主要研究的方法(self-labeled)
self-labeled方法的分类:

self-labeled的分类图
self-teaching与multi-teaching的比较:
self-teaching即自己教的知识再用来提升自己,由于自己先前的认知有错误,很可能会恶化模型。
multi-teaching即两个不同的view来相互监督学习,从两个不同的view相互借鉴自己不会的,两者也会发生冲突。Tri-training应运而生。
single-view与multi-view的比较:
single-view即将数据集从单独的一个view去构建模型,而mutil-view是从数据集的多个冗余且相互独立的view针对同一个任务去构建模型。在真实的应用场景中,一个数据集有冗余而独立的属性集是非常少见的。
single-view的经典方法有self-training、Tri-training。
multi-view的经典方法有co-training。
single-learning与multi-learning的比较:
single-learning是指无论是集成学习还是单分类模型,其中所使用的模型均为同一个模型。如贝叶斯、决策树、SVM等基分类器。
multi-learning是指无论是集成学习还是单分类模型,其中所使用的模型是多个基学习器模型。
single-classifier与multi-classifier的比较:
single-classifier是指单个分类器。
multi-classifier是指多个分类器。可能为多个同一模型也可能为多个模型的组合。
在self-labeled方法中,每一次迭代过程中扩充有标签样本集主要有三种方式。
- Incremental
A strictly incremental approach begins with an enlarged labeled set EL = L and adds, step-by-step, the most confident instances of U if they fulfill certain criteria.
每一次都添加符合条件的未标记样本,规定每一次添加未标记样本的大小等。 - batch
Another way to generate an EL set is in batch mode. This involves deciding whether each instance meets the addition criteria before adding any of them to the EL. Then, all those that do meet the criteria are added at once.
每一次挑选出符合条件的所有未标记样本集一次性添加到标记样本集中。 - amending
Amending models appeared as a solution to the main drawback of the strictly incremental approach. In this approach, the algorithm starts with EL = L and iteratively can add or remove any instance that meets the specific criterion. This mechanism allows rectifications to already performed operations, and its main advantageis to make the achievementof a good accuracy-suited EL set of instances easy.
主要是克服了Incremental的缺点,反复地选择最置信的样本添加到标记集合中。
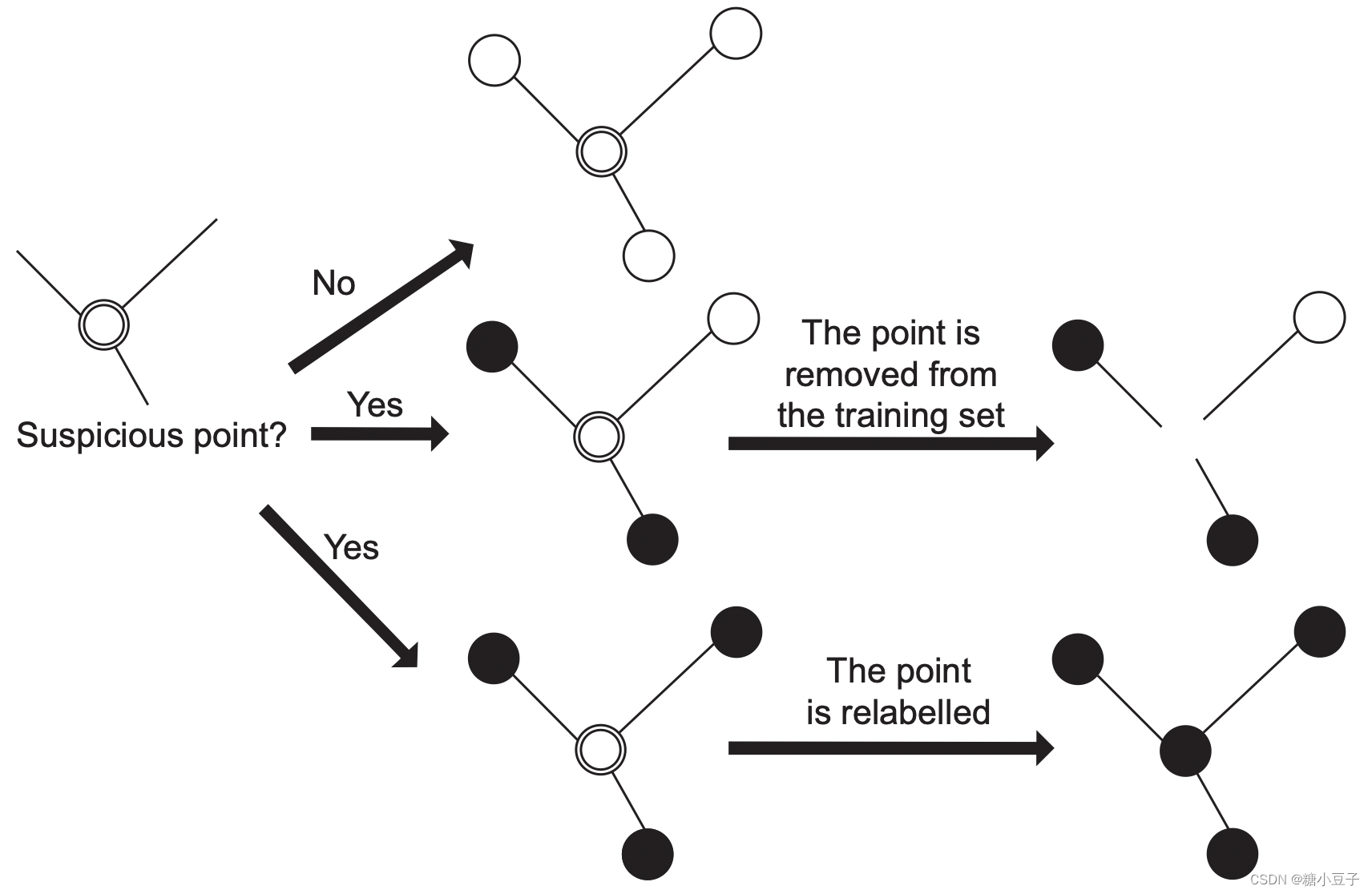
下面介绍一种amending方法保证添加到标记集合中的样本不受到noise数据的干扰
文章题目:On the characterization of noise filters for self-training semi-supervised in nearest neighbor classification
本文提出一个noise filters based on nearest neighbor,在每一次模型对未标记数据集进行更新时,noise filters被用来检测该未标记数据集是否满足条件可被添加到扩充的有标记集合中去,防止noise数据影响下一次的模型构建。

noise filters model framework
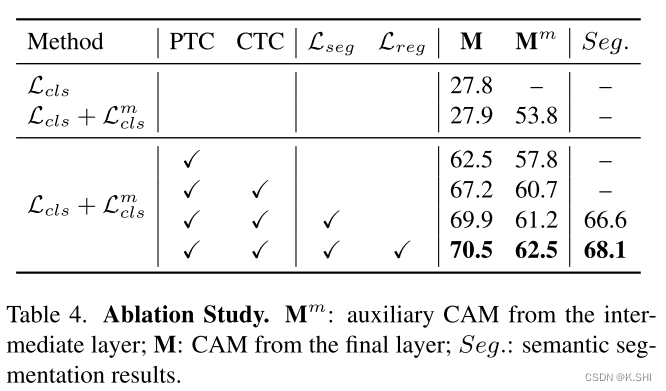
本文还对多种filters进行了比较,其中包括local filter和global filter。

Number of detected noisy instances
该文章对self-labeled的方法没有太大的改变,只是在扩充有标记样本集的时候更加准确,减少了noise数据对模型的干扰。
下面再介绍一篇2020年新发表的文章,题目为:An effective framework based on local cores for self-labeled semi-supervised classification
该文章的主要贡献如下: - propose a LC-SSC framework which solves the problem of lacking adequate initial labeled data in self-labeled methods.The pro-posed framework is able to deal with spherical or non-spherical data. Besides, our framework performs better than the existing one, when initial labeled data are extremely scarce.
- In LC-SSC framework, we modify the local cores and pro-pose a method
to find local cores in semi-supervised learning.
总结该文章的贡献:
当初始阶段标记样本是极其稀缺的情况下,该方法能够通过发现local core的方法能相对扩充有标记集合,使得self-labeled方法在初始阶段能较好的学习到数据的分布。此外,该方法也可以处理球型或非球型数据集,先前所提出的方法不能够很好的处理非球型数据集,在初始阶段扩充非球型数据集时,错误率很高。

球型数据

非球型数据
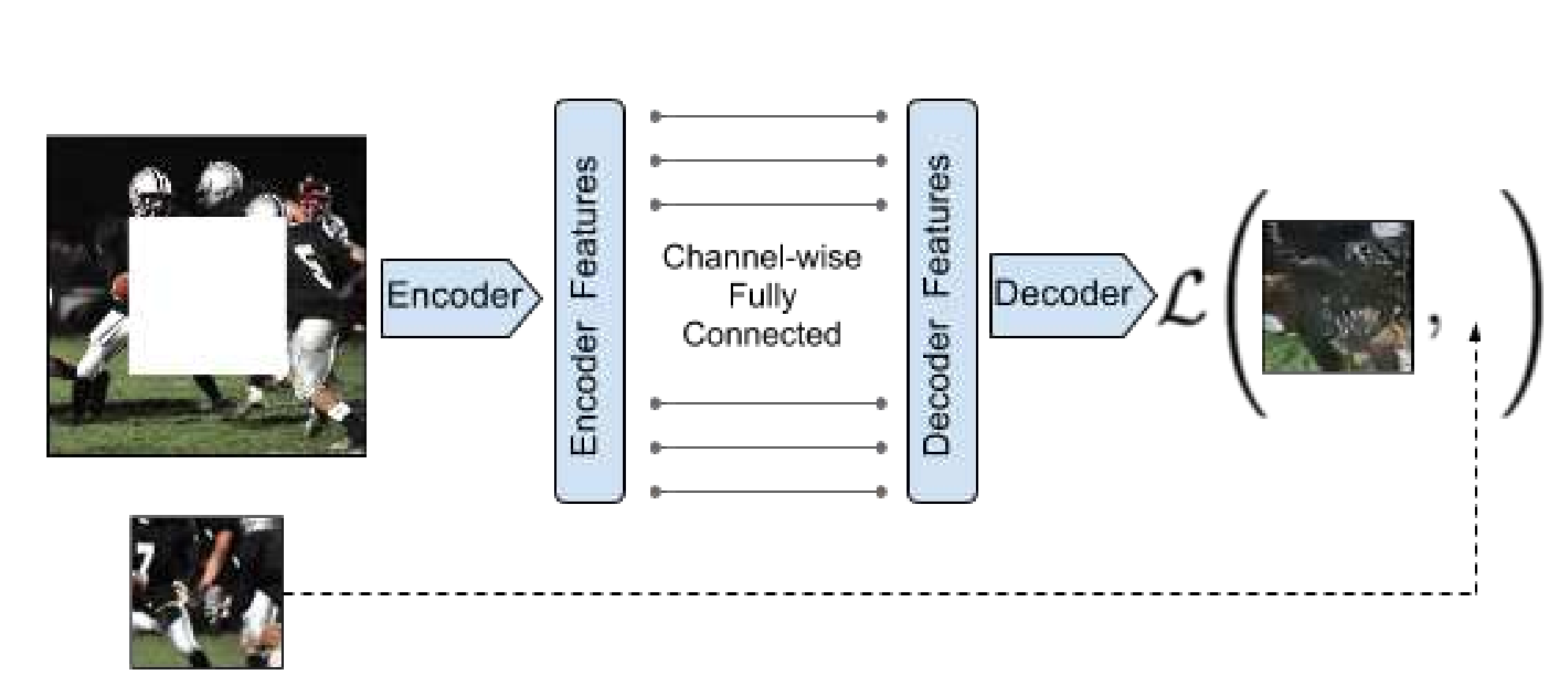
该方法的框架:

方法整体框架图
该方法的效果:

球型效果图

非球型效果图
总结 - 目前所提出的方法都是在扩充有标记数据集时的准确率或在模型初始阶段扩充有标记数据集上做文章。但也得到了不错的效果。
- 未来可能的方向:1、可以发现新的技术来更加准确的扩充有标记样本的集合。2、利用一些基模型的特性加上数据集本身的一些特性在对未标记数据集分类时更加准确。我们最终的目的就是扩充有标记数据集,使得模型能不断从未标记数据集中获得知识。
以上仅代表我个人的想法,若有错误之处,欢迎指正!!!
参考文献:
[1] Jesper E. van Engelen.A survey on semi-supervised learning.
[2] Isaac Triguero.Self-labeled techniques for semi-supervised learning: taxonomy, software and empirical study.
[3]Isaac Triguero.On the characterization of noise filters for self-training semi-supervised in nearest neighbor classification.
[4]Junnan Li.An effective framework based on local cores for self-labeled semi-supervised classification.