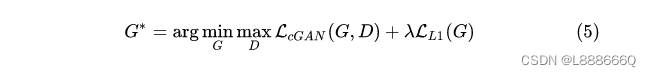目录
一、前言
二、数据集
三、网络结构
四、代码
(一)net
(二)dataset
(三)train
(四)test
五、结果
(一)128*128
(二)256*256
六、完整代码
一、前言
pix2pix可以实现画风迁移、图片修复、语义分割、图片上色等等。这里主要实现将facades labels转换成真实图片。由于源码中涉及的功能较多,代码较为复杂,这里我将主要部分拿了出来并做了一些小修改。
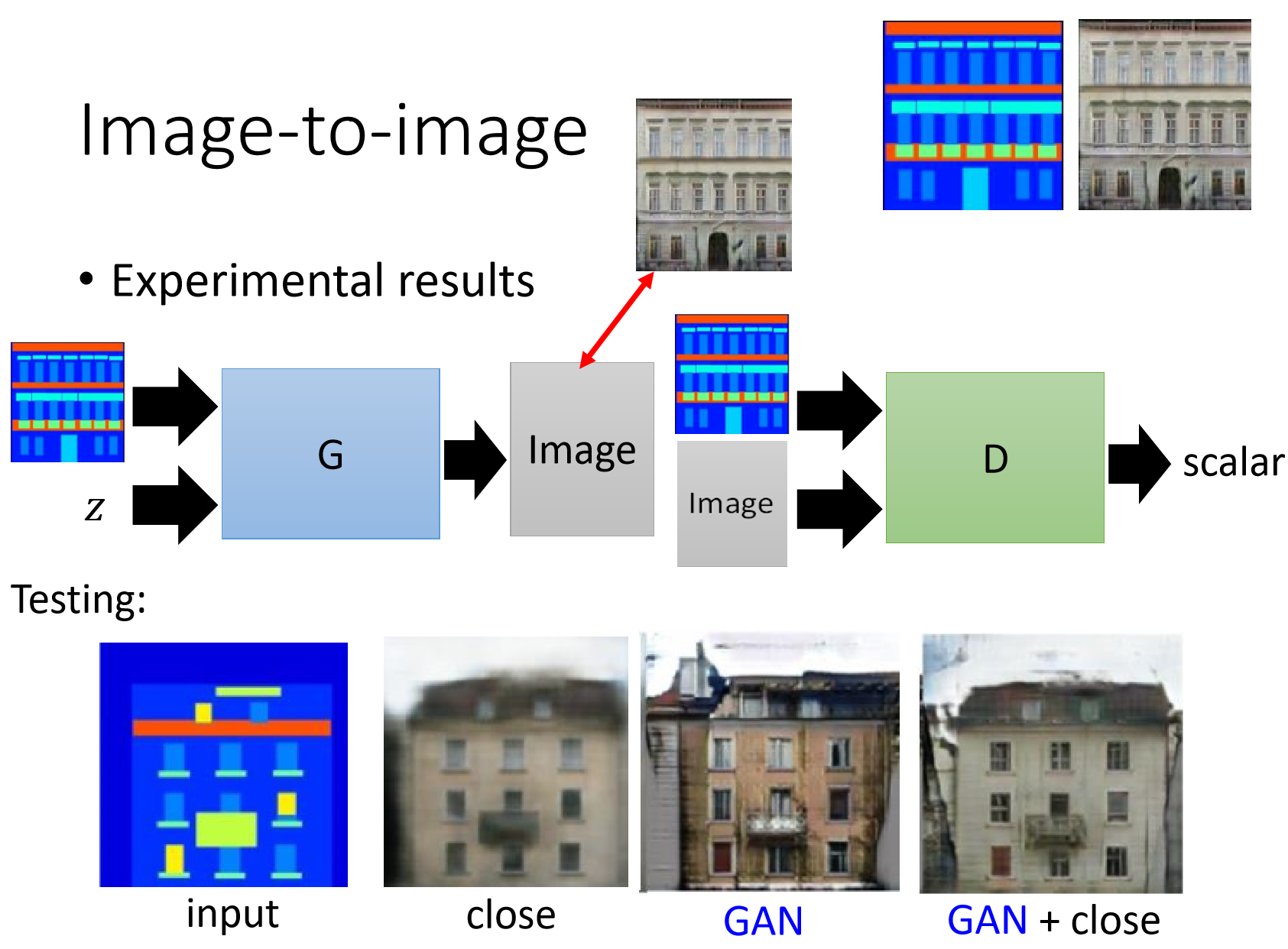
在传统的GAN中,生成器G的输入是噪声z,目的是让G去学习一种分布去拟合真实数据的分布。而在pix2pix中,G的输入是facades labels,生成器G一方面要尽可能生成真的图片去骗过D,另一方面要使输出尽可能去逼近facades labels对应的真实图片(利用了L1loss)。G的噪声是通过在网络的dropout层引入的(如果不引入噪声,那么最终训练的G只会逼近已有的训练样本,无法拟合真实数据的分布) 。
pix2pix中判别器D采用了PatchGAN,即D不仅仅只对整张图的真假打分,而是将图片最终分成多个patch,对每个patch进行打分,D只有当图片与fecades labels匹配并且尽可能逼近真实样本时候才会打高分。
二、数据集
数据集采用的是facades数据集,训练样本是成对匹配的(其中fecades图片均以png格式存储,对应真实样本以jpg存储),共有606张图片,训练过程中将数据集按8:2的比例划分训练集和验证集。部分图像对如下图所示。



三、网络结构
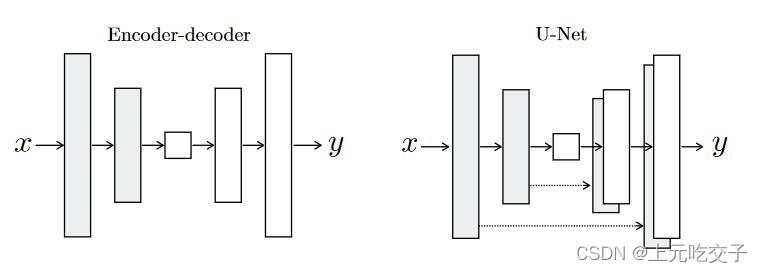
生成器G采用了Unet结构,本质为encoder-decoder,网络结构如下图所示(这里以输入图片为256*256为例)。dropout层只在输入输出channel都为512时候才有。

判别器D其实就是简单的卷积神经网络,网络结构如下图所示。

四、代码
(一)net
这里提供了输入为128*128和256*256两种结构的网络
import torch.nn as nn
import torch
from collections import OrderedDict# 定义降采样部分
class downsample(nn.Module):def __init__(self, in_channels, out_channels):super(downsample, self).__init__()self.down = nn.Sequential(nn.LeakyReLU(0.2, True),nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=4, stride=2, padding=1),nn.BatchNorm2d(out_channels))def forward(self, x):return self.down(x)# 定义上采样部分
class upsample(nn.Module):def __init__(self, in_channels, out_channels, drop_out=False):super(upsample, self).__init__()self.up = nn.Sequential(nn.ReLU(True),nn.ConvTranspose2d(in_channels=in_channels, out_channels=out_channels, kernel_size=4, stride=2, padding=1),nn.BatchNorm2d(out_channels),nn.Dropout(0.5) if drop_out else nn.Identity())def forward(self, x):return self.up(x)# ---------------------------------------------------------------------------------
# 定义pix_G =>input 128*128
class pix2pixG_128(nn.Module):def __init__(self):super(pix2pixG_128, self).__init__()# down sampleself.down_1 = nn.Conv2d(3, 64, 4, 2, 1) # [batch,3,128,128]=>[batch,64,64,64]for i in range(7):if i == 0:self.down_2 = downsample(64, 128) # [batch,64,64,64]=>[batch,128,32,32]self.down_3 = downsample(128, 256) # [batch,128,32,32]=>[batch,256,16,16]self.down_4 = downsample(256, 512) # [batch,256,16,16]=>[batch,512,8,8]self.down_5 = downsample(512, 512) # [batch,512,8,8]=>[batch,512,4,4]self.down_6 = downsample(512, 512) # [batch,512,4,4]=>[batch,512,2,2]self.down_7 = downsample(512, 512) # [batch,512,2,2]=>[batch,512,1,1]# up_samplefor i in range(7):if i == 0:self.up_1 = upsample(512, 512) # [batch,512,1,1]=>[batch,512,2,2]self.up_2 = upsample(1024, 512, drop_out=True) # [batch,1024,2,2]=>[batch,512,4,4]self.up_3 = upsample(1024, 512, drop_out=True) # [batch,1024,4,4]=>[batch,512,8,8]self.up_4 = upsample(1024, 256) # [batch,1024,8,8]=>[batch,256,16,16]self.up_5 = upsample(512, 128) # [batch,512,16,16]=>[batch,128,32,32]self.up_6 = upsample(256, 64) # [batch,256,32,32]=>[batch,64,64,64]self.last_Conv = nn.Sequential(nn.ConvTranspose2d(in_channels=128, out_channels=3, kernel_size=4, stride=2, padding=1),nn.Tanh())self.init_weight()def init_weight(self):for w in self.modules():if isinstance(w, nn.Conv2d):nn.init.kaiming_normal_(w.weight, mode='fan_out')if w.bias is not None:nn.init.zeros_(w.bias)elif isinstance(w, nn.ConvTranspose2d):nn.init.kaiming_normal_(w.weight, mode='fan_in')elif isinstance(w, nn.BatchNorm2d):nn.init.ones_(w.weight)nn.init.zeros_(w.bias)def forward(self, x):# downdown_1 = self.down_1(x)down_2 = self.down_2(down_1)down_3 = self.down_3(down_2)down_4 = self.down_4(down_3)down_5 = self.down_5(down_4)down_6 = self.down_6(down_5)down_7 = self.down_7(down_6)# upup_1 = self.up_1(down_7)up_2 = self.up_2(torch.cat([up_1, down_6], dim=1))up_3 = self.up_3(torch.cat([up_2, down_5], dim=1))up_4 = self.up_4(torch.cat([up_3, down_4], dim=1))up_5 = self.up_5(torch.cat([up_4, down_3], dim=1))up_6 = self.up_6(torch.cat([up_5, down_2], dim=1))out = self.last_Conv(torch.cat([up_6, down_1], dim=1))return out# 定义pix_D_128 => input 128*128
class pix2pixD_128(nn.Module):def __init__(self):super(pix2pixD_128, self).__init__()# 定义基本的卷积\bn\reludef base_Conv_bn_lkrl(in_channels, out_channels, stride):return nn.Sequential(nn.Conv2d(in_channels, out_channels, 4, stride, 1),nn.BatchNorm2d(out_channels),nn.LeakyReLU(0.2))D_dic = OrderedDict()in_channels = 6out_channels = 64for i in range(4):if i < 3:D_dic.update({'layer_{}'.format(i + 1): base_Conv_bn_lkrl(in_channels, out_channels, 2)})else:D_dic.update({'layer_{}'.format(i + 1): base_Conv_bn_lkrl(in_channels, out_channels, 1)})in_channels = out_channelsout_channels *= 2D_dic.update({'last_layer': nn.Conv2d(512, 1, 4, 1, 1)}) # [batch,1,14,14]self.D_model = nn.Sequential(D_dic)def forward(self, x1, x2):in_x = torch.cat([x1, x2], dim=1)return self.D_model(in_x)# ---------------------------------------------------------------------------------
# 256*256
class pix2pixG_256(nn.Module):def __init__(self):super(pix2pixG_256, self).__init__()# down sampleself.down_1 = nn.Conv2d(3, 64, 4, 2, 1) # [batch,3,256,256]=>[batch,64,128,128]for i in range(7):if i == 0:self.down_2 = downsample(64, 128) # [batch,64,128,128]=>[batch,128,64,64]self.down_3 = downsample(128, 256) # [batch,128,64,64]=>[batch,256,32,32]self.down_4 = downsample(256, 512) # [batch,256,32,32]=>[batch,512,16,16]self.down_5 = downsample(512, 512) # [batch,512,16,16]=>[batch,512,8,8]self.down_6 = downsample(512, 512) # [batch,512,8,8]=>[batch,512,4,4]self.down_7 = downsample(512, 512) # [batch,512,4,4]=>[batch,512,2,2]self.down_8 = downsample(512, 512) # [batch,512,2,2]=>[batch,512,1,1]# up_samplefor i in range(7):if i == 0:self.up_1 = upsample(512, 512) # [batch,512,1,1]=>[batch,512,2,2]self.up_2 = upsample(1024, 512, drop_out=True) # [batch,1024,2,2]=>[batch,512,4,4]self.up_3 = upsample(1024, 512, drop_out=True) # [batch,1024,4,4]=>[batch,512,8,8]self.up_4 = upsample(1024, 512) # [batch,1024,8,8]=>[batch,512,16,16]self.up_5 = upsample(1024, 256) # [batch,1024,16,16]=>[batch,256,32,32]self.up_6 = upsample(512, 128) # [batch,512,32,32]=>[batch,128,64,64]self.up_7 = upsample(256, 64) # [batch,256,64,64]=>[batch,64,128,128]self.last_Conv = nn.Sequential(nn.ConvTranspose2d(in_channels=128, out_channels=3, kernel_size=4, stride=2, padding=1),nn.Tanh())self.init_weight()def init_weight(self):for w in self.modules():if isinstance(w, nn.Conv2d):nn.init.kaiming_normal_(w.weight, mode='fan_out')if w.bias is not None:nn.init.zeros_(w.bias)elif isinstance(w, nn.ConvTranspose2d):nn.init.kaiming_normal_(w.weight, mode='fan_in')elif isinstance(w, nn.BatchNorm2d):nn.init.ones_(w.weight)nn.init.zeros_(w.bias)def forward(self, x):# downdown_1 = self.down_1(x)down_2 = self.down_2(down_1)down_3 = self.down_3(down_2)down_4 = self.down_4(down_3)down_5 = self.down_5(down_4)down_6 = self.down_6(down_5)down_7 = self.down_7(down_6)down_8 = self.down_8(down_7)# upup_1 = self.up_1(down_8)up_2 = self.up_2(torch.cat([up_1, down_7], dim=1))up_3 = self.up_3(torch.cat([up_2, down_6], dim=1))up_4 = self.up_4(torch.cat([up_3, down_5], dim=1))up_5 = self.up_5(torch.cat([up_4, down_4], dim=1))up_6 = self.up_6(torch.cat([up_5, down_3], dim=1))up_7 = self.up_7(torch.cat([up_6, down_2], dim=1))out = self.last_Conv(torch.cat([up_7, down_1], dim=1))return out# 256*256
class pix2pixD_256(nn.Module):def __init__(self):super(pix2pixD_256, self).__init__()# 定义基本的卷积\bn\reludef base_Conv_bn_lkrl(in_channels, out_channels, stride):return nn.Sequential(nn.Conv2d(in_channels, out_channels, 4, stride, 1),nn.BatchNorm2d(out_channels),nn.LeakyReLU(0.2))D_dic = OrderedDict()in_channels = 6out_channels = 64for i in range(4):if i < 3:D_dic.update({'layer_{}'.format(i + 1): base_Conv_bn_lkrl(in_channels, out_channels, 2)})else:D_dic.update({'layer_{}'.format(i + 1): base_Conv_bn_lkrl(in_channels, out_channels, 1)})in_channels = out_channelsout_channels *= 2D_dic.update({'last_layer': nn.Conv2d(512, 1, 4, 1, 1)}) # [batch,1,30,30]self.D_model = nn.Sequential(D_dic)def forward(self, x1, x2):in_x = torch.cat([x1, x2], dim=1)return self.D_model(in_x)
(二)dataset
split_data.py
import random
import globdef split_data(dir_root):random.seed(0)ori_img = glob.glob(dir_root + '/*.png')k = 0.2train_ori_imglist = []val_ori_imglist = []sample_data = random.sample(population=ori_img, k=int(k * len(ori_img)))for img in ori_img:if img in sample_data:val_ori_imglist.append(img)else:train_ori_imglist.append(img)return train_ori_imglist, val_ori_imglistif __name__ == '__main__':a, b= split_data('../base')
mydatasets.py
from torch.utils.data.dataset import Dataset
import torchvision.transforms as transform
from PIL import Image
import cv2class CreateDatasets(Dataset):def __init__(self, ori_imglist,img_size):self.ori_imglist = ori_imglistself.transform = transform.Compose([transform.ToTensor(),transform.Resize((img_size, img_size)),transform.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])def __len__(self):return len(self.ori_imglist)def __getitem__(self, item):ori_img = cv2.imread(self.ori_imglist[item])ori_img = ori_img[:, :, ::-1]real_img = Image.open(self.ori_imglist[item].replace('.png', '.jpg'))ori_img = self.transform(ori_img.copy())real_img = self.transform(real_img)return ori_img, real_img
(三)train
from torch.utils.tensorboard import SummaryWriter
from pix2Topix import pix2pixG_256, pix2pixD_256
import argparse
from mydatasets import CreateDatasets
from split_data import split_data
import os
from torch.utils.data.dataloader import DataLoader
import torch
import torch.optim as optim
import torch.nn as nn
from utils import train_one_epoch, valdef train(opt):batch = opt.batchdata_path = opt.dataPathprint_every = opt.everydevice = 'cuda' if torch.cuda.is_available() else 'cpu'epochs = opt.epochimg_size = opt.imgsizeif not os.path.exists(opt.savePath):os.mkdir(opt.savePath)# 加载数据集train_imglist, val_imglist = split_data(data_path)train_datasets = CreateDatasets(train_imglist, img_size)val_datasets = CreateDatasets(val_imglist, img_size)train_loader = DataLoader(dataset=train_datasets, batch_size=batch, shuffle=True, num_workers=opt.numworker,drop_last=True)val_loader = DataLoader(dataset=val_datasets, batch_size=batch, shuffle=True, num_workers=opt.numworker,drop_last=True)# 实例化网络pix_G = pix2pixG_256().to(device)pix_D = pix2pixD_256().to(device)# 定义优化器和损失函数optim_G = optim.Adam(pix_G.parameters(), lr=0.0002, betas=(0.5, 0.999))optim_D = optim.Adam(pix_D.parameters(), lr=0.0002, betas=(0.5, 0.999))loss = nn.MSELoss()l1_loss = nn.L1Loss()start_epoch = 0# 加载预训练权重if opt.weight != '':ckpt = torch.load(opt.weight)pix_G.load_state_dict(ckpt['G_model'], strict=False)pix_D.load_state_dict(ckpt['D_model'], strict=False)start_epoch = ckpt['epoch'] + 1writer = SummaryWriter('train_logs')# 开始训练for epoch in range(start_epoch, epochs):loss_mG, loss_mD = train_one_epoch(G=pix_G, D=pix_D, train_loader=train_loader,optim_G=optim_G, optim_D=optim_D, writer=writer, loss=loss, device=device,plot_every=print_every, epoch=epoch, l1_loss=l1_loss)writer.add_scalars(main_tag='train_loss', tag_scalar_dict={'loss_G': loss_mG,'loss_D': loss_mD}, global_step=epoch)# 验证集val(G=pix_G, D=pix_D, val_loader=val_loader, loss=loss, l1_loss=l1_loss, device=device, epoch=epoch)# 保存模型torch.save({'G_model': pix_G.state_dict(),'D_model': pix_D.state_dict(),'epoch': epoch}, './weights/pix2pix_256.pth')def cfg():parse = argparse.ArgumentParser()parse.add_argument('--batch', type=int, default=16)parse.add_argument('--epoch', type=int, default=200)parse.add_argument('--imgsize', type=int, default=256)parse.add_argument('--dataPath', type=str, default='../base', help='data root path')parse.add_argument('--weight', type=str, default='', help='load pre train weight')parse.add_argument('--savePath', type=str, default='./weights', help='weight save path')parse.add_argument('--numworker', type=int, default=4)parse.add_argument('--every', type=int, default=2, help='plot train result every * iters')opt = parse.parse_args()return optif __name__ == '__main__':opt = cfg()print(opt)train(opt)
utils.py
import torchvision
from tqdm import tqdm
import torch
import osdef train_one_epoch(G, D, train_loader, optim_G, optim_D, writer, loss, device, plot_every, epoch, l1_loss):pd = tqdm(train_loader)loss_D, loss_G = 0, 0step = 0G.train()D.train()for idx, data in enumerate(pd):in_img = data[0].to(device)real_img = data[1].to(device)# 先训练Dfake_img = G(in_img)D_fake_out = D(fake_img.detach(), in_img).squeeze()D_real_out = D(real_img, in_img).squeeze()ls_D1 = loss(D_fake_out, torch.zeros(D_fake_out.size()).cuda())ls_D2 = loss(D_real_out, torch.ones(D_real_out.size()).cuda())ls_D = (ls_D1 + ls_D2) * 0.5optim_D.zero_grad()ls_D.backward()optim_D.step()# 再训练Gfake_img = G(in_img)D_fake_out = D(fake_img, in_img).squeeze()ls_G1 = loss(D_fake_out, torch.ones(D_fake_out.size()).cuda())ls_G2 = l1_loss(fake_img, real_img)ls_G = ls_G1 + ls_G2 * 100optim_G.zero_grad()ls_G.backward()optim_G.step()loss_D += ls_Dloss_G += ls_Gpd.desc = 'train_{} G_loss: {} D_loss: {}'.format(epoch, ls_G.item(), ls_D.item())# 绘制训练结果if idx % plot_every == 0:writer.add_images(tag='train_epoch_{}'.format(epoch), img_tensor=0.5 * (fake_img + 1), global_step=step)step += 1mean_lsG = loss_G / len(train_loader)mean_lsD = loss_D / len(train_loader)return mean_lsG, mean_lsD@torch.no_grad()
def val(G, D, val_loader, loss, device, l1_loss, epoch):pd = tqdm(val_loader)loss_D, loss_G = 0, 0G.eval()D.eval()all_loss = 10000for idx, item in enumerate(pd):in_img = item[0].to(device)real_img = item[1].to(device)fake_img = G(in_img)D_fake_out = D(fake_img, in_img).squeeze()ls_D1 = loss(D_fake_out, torch.zeros(D_fake_out.size()).cuda())ls_D = ls_D1 * 0.5ls_G1 = loss(D_fake_out, torch.ones(D_fake_out.size()).cuda())ls_G2 = l1_loss(fake_img, real_img)ls_G = ls_G1 + ls_G2 * 100loss_G += ls_Gloss_D += ls_Dpd.desc = 'val_{}: G_loss:{} D_Loss:{}'.format(epoch, ls_G.item(), ls_D.item())# 保存最好的结果all_ls = ls_G + ls_Dif all_ls < all_loss:all_loss = all_lsbest_image = fake_imgresult_img = (best_image + 1) * 0.5if not os.path.exists('./results'):os.mkdir('./results')torchvision.utils.save_image(result_img, './results/val_epoch{}.jpg'.format(epoch))
(四)test
from pix2Topix import pix2pixG_256
import torch
import torchvision.transforms as transform
import matplotlib.pyplot as plt
import cv2
from PIL import Imagedef test(img_path):if img_path.endswith('.png'):img = cv2.imread(img_path)img = img[:, :, ::-1]else:img = Image.open(img_path)transforms = transform.Compose([transform.ToTensor(),transform.Resize((256, 256)),transform.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])img = transforms(img.copy())img = img[None].to('cuda') # [1,3,128,128]# 实例化网络G = pix2pixG_256().to('cuda')# 加载预训练权重ckpt = torch.load('weights/pix2pix_256.pth')G.load_state_dict(ckpt['G_model'], strict=False)G.eval()out = G(img)[0]out = out.permute(1,2,0)out = (0.5 * (out + 1)).cpu().detach().numpy()plt.figure()plt.imshow(out)plt.show()if __name__ == '__main__':test('../base/cmp_b0141.png')
五、结果
(一)128*128
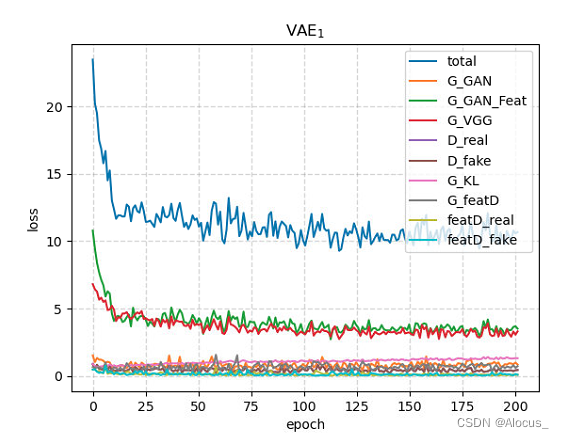
利用128*128的net迭代了200个epoch,训练损失如下图所示。

下图为200个epoch后G生成的图片(验证集上)

(二)256*256
利用256*256的net迭代了170个epoch,训练损失如下图所示。

下图为训练集上G生成的部分图片(训练集上生成效果还是很不错的)。

下图为验证集上G生成的部分图片(验证集上效果相对较差一些)。

六、完整代码
代码:代码 提取码:1uee
权重:weights 提取码:zmdo
数据集:data 提取码:yydk