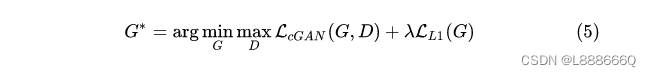文章目录
- Pix2pix介绍
- Pix2pix应用
- Pix2pix生成器及判别器网络结构
- 代码实现
- 1、导入需要的库
- 2、下载数据包
- 3、加载并展示数据包中的图片
- 4、处理图片
- 4.1 将图像调整为更大的高度和宽度
- 4.2 随机裁剪到目标尺寸
- 4.3 随机将图像做水平镜像处理
- 4.4 图像归一化
- 4.5 处理训练集图片
- 4.6 处理测试集图片
- 4.7 将训练集所有图片进行切片操作,放入一个dataset中
- 4.8 将测试集所有图片进行切片操作,放入一个dataset中
- 5、定义网络结构
- 5.1 定义下采样函数
- 5.2 定义上采样函数
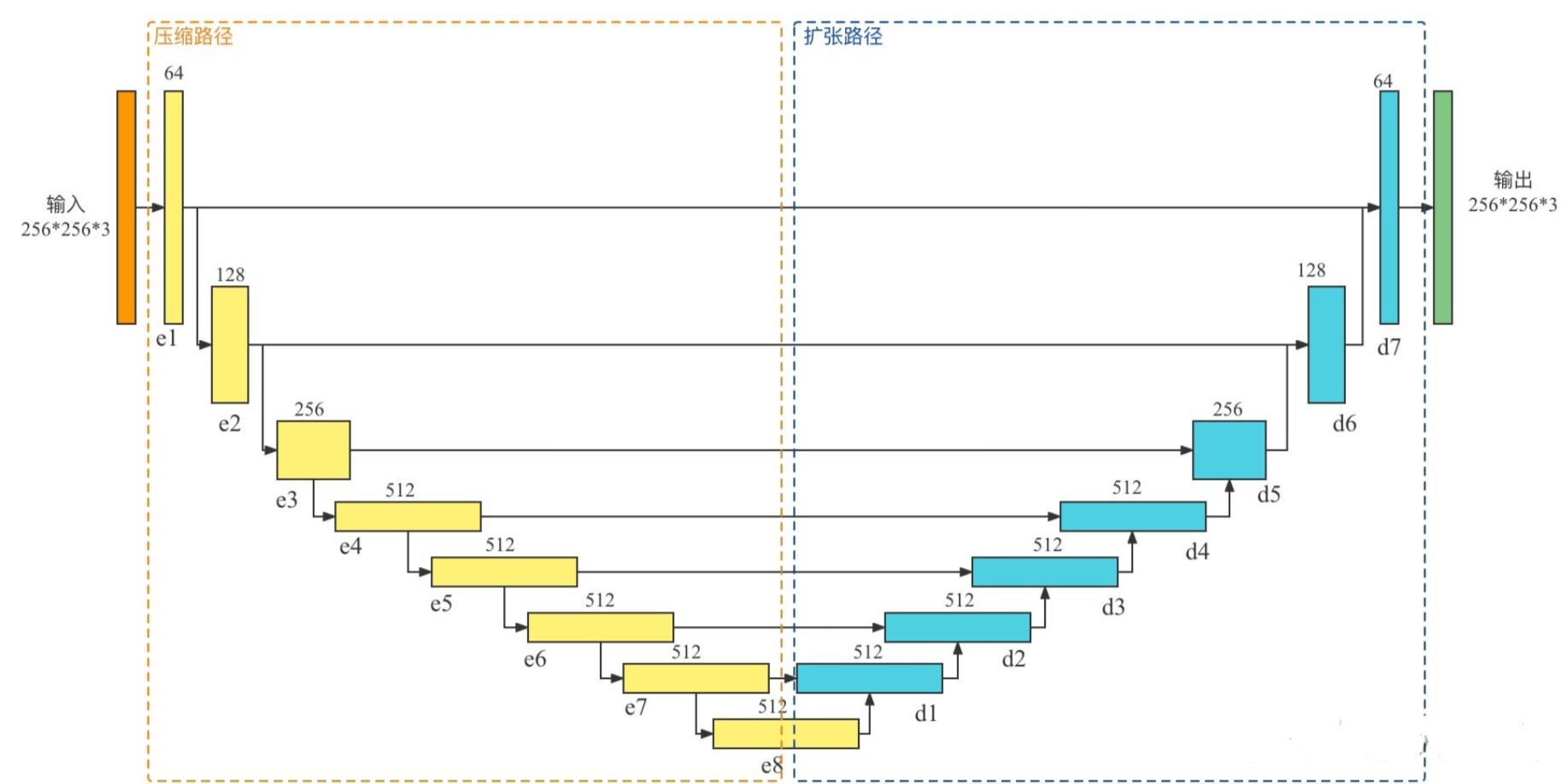
- 5.3 定义生成器(UNet网络)
- 5.4 查看生成器结构
- 5.5定义判别器(PatchGAN网络)
- 5.6 查看判别器结构
- 6、定义损失函数
- 6.1 定义生成器损失函数
- 6.2 定义判别器损失函数
- 7、定义优化函数
- 8、定义图像生成并显示的函数
- 9、定义一次梯度下降过程
- 10、训练模型
- 10.1 定义训练过程
- 10.2 开始训练
- 参考资料
Pix2pix介绍
在传统的GAN里,输入一个随机噪声,就会输出一幅随机图像。但通常如果我们想输出的图像是我们想要的那种图像,和我们的输入是对应的、有关联的,比如输入一只猫的草图,输出同一形态的猫的真实图片。比如:

那么这个时候,Pix2pix就派上用场了。
pix2pix对传统的GAN做了个小改动,它不再输入随机噪声,而是输入用户给的图片:
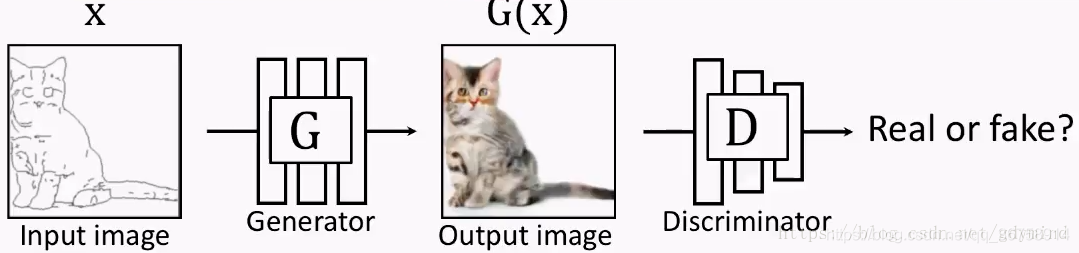
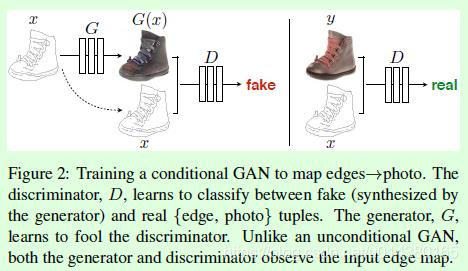
但这也就产生了新的问题:我们怎样建立输入和输出的对应关系。此时G的输出如果是下面这样,D会判断是真图:
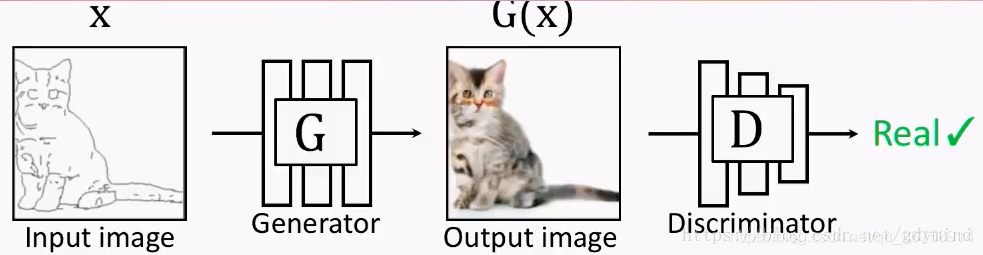 但如果G的输出是下面这样的,D拿来一看,也会认为是真的图片。也就是说,这样做并不能训练出输入和输出对应的网络G,因为是否对应根本不影响D的判断。
但如果G的输出是下面这样的,D拿来一看,也会认为是真的图片。也就是说,这样做并不能训练出输入和输出对应的网络G,因为是否对应根本不影响D的判断。
为了体现这种对应关系,解决方案也很简单,你可以也已经想到了:我们把GG的输入和输出一起作为DD的输入不就好了?于是现在的优化目标变成了这样:
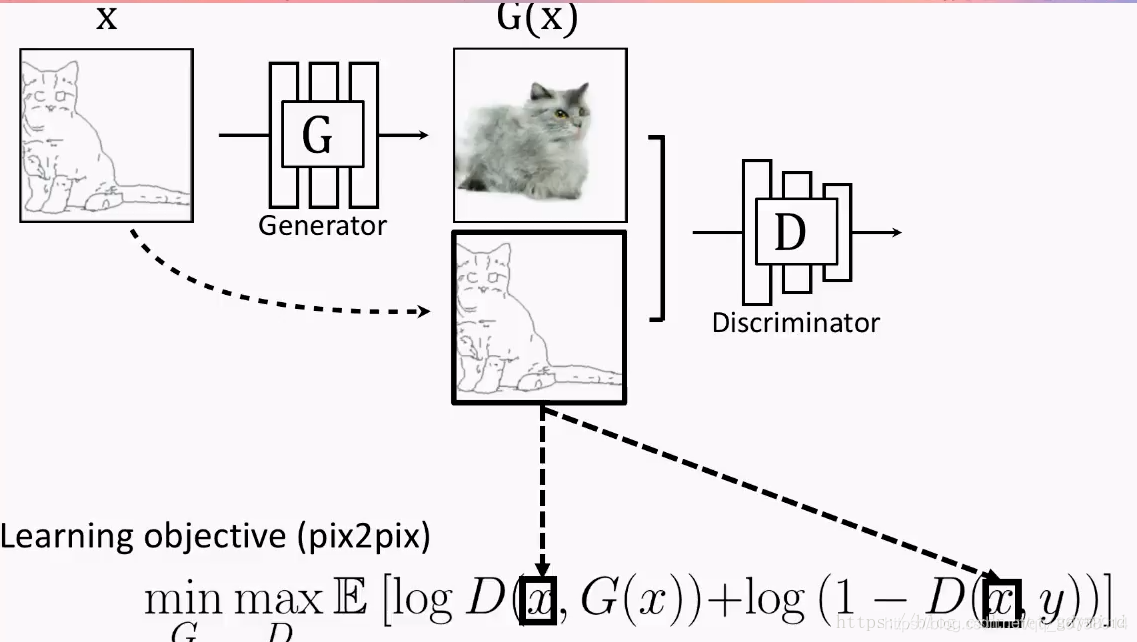
Pix2pix应用
Pix2pix可以应用在:草图转图片、图片自动着色、灰度图变彩色图等领域,如下图所示。

Pix2pix生成器及判别器网络结构
Pix2pix论文地址:Pix2pix论文。

如上图所示,生成器G用到的是Unet结构,输入的轮廓图 x x x编码再解码成真实图片,判别器D用到的是作者自己提出来的条件判别器PatchGAN,判别器D的作用是在轮廓图 x x x的条件下,对于生成的图片 G ( x ) G(x) G(x)判断为假,对于真实判断为真。
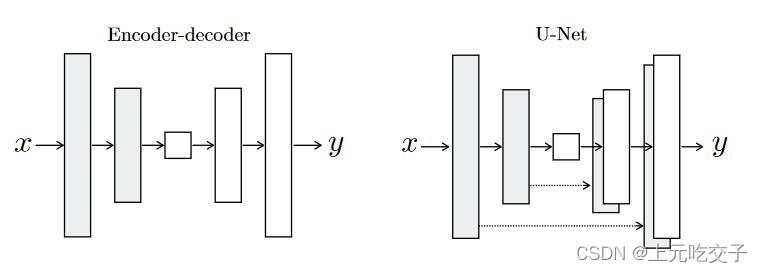
为什么选择Unet?
作者提到,输入和输出图像的外表面(surface appearance)应该不同而潜在的结构(underlying structure)应该相似,对于image translation的任务来说,输入和输出应该共享一些底层的信息,因此使用Unet这种跳层连接(skip connection)的方法,这里说的跳层连接是 i i i层直接与 n − i n-i n−i层相加,如下所示:
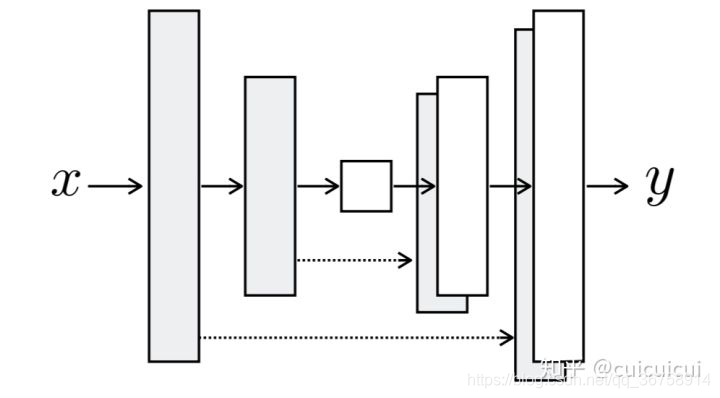
为什么选择PatchGAN?
为了能更好得对图像的局部做判断,作者提出patchGAN的结构,也就是说把图像等分成patch,分别判断每个Patch的真假,最后再取平均。作者最后说,文章提出的这个PatchGAN可以看成所以另一种形式的纹理损失或样式损失。在具体实验时,作者使用了不同尺寸的patch,最后发现70x70的尺寸比较合适。
代码实现
1、导入需要的库
import tensorflow as tf
import os
import matplotlib.pyplot as plt
from IPython import display
2、下载数据包
_URL = 'https://people.eecs.berkeley.edu/~tinghuiz/projects/pix2pix/datasets/facades.tar.gz'path_to_zip = tf.keras.utils.get_file('facades.tar.gz',origin=_URL,extract=True)PATH = os.path.join(os.path.dirname(path_to_zip), 'facades/')
3、加载并展示数据包中的图片
def load(image_file):image = tf.io.read_file(image_file)image = tf.image.decode_jpeg(image)w = tf.shape(image)[1]w = w // 2real_image = image[:, :w, :]input_image = image[:, w:, :]input_image = tf.cast(input_image, tf.float32)real_image = tf.cast(real_image, tf.float32)return input_image, real_imageinp, re = load(PATH+'train/100.jpg')
# casting to int for matplotlib to show the image
plt.figure()
plt.imshow(inp/255.0)
plt.figure()
plt.imshow(re/255.0)
因为原图片为:

但我们需要的是一张输入图片(草图)和一张真实图片(真实建筑),所以我们定义load() 函数,其主要功能是将一种图片拆分成两张。
得到结果:
4、处理图片
4.1 将图像调整为更大的高度和宽度
def resize(input_image, real_image, height, width):input_image = tf.image.resize(input_image, [height, width],method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)real_image = tf.image.resize(real_image, [height, width],method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)return input_image, real_image
4.2 随机裁剪到目标尺寸
对一张图片进行多次(如10次)随机裁剪,将得到的10张图片放到一起看时,有一种图片在跳动的感觉。所以称这种方法为Random jittering,其主要作用是防止过拟合。
# 目标尺寸
IMG_WIDTH = 256
IMG_HEIGHT = 256
def random_crop(input_image, real_image):stacked_image = tf.stack([input_image, real_image], axis=0)cropped_image = tf.image.random_crop(stacked_image, size=[2, IMG_HEIGHT, IMG_WIDTH, 3])return cropped_image[0], cropped_image[1]
4.3 随机将图像做水平镜像处理
水平镜像处理的目的也是为了防止过拟合。
def random_jitter(input_image, real_image):# resizing to 286 x 286 x 3input_image, real_image = resize(input_image, real_image, 286, 286)# randomly cropping to 256 x 256 x 3input_image, real_image = random_crop(input_image, real_image)if tf.random.uniform(()) > 0.5:# random mirroringinput_image = tf.image.flip_left_right(input_image)real_image = tf.image.flip_left_right(real_image)return input_image, real_image
4.4 图像归一化
# normalizing the images to [-1, 1]
def normalize(input_image, real_image):input_image = (input_image / 127.5) - 1real_image = (real_image / 127.5) - 1return input_image, real_image
4.5 处理训练集图片
def load_image_train(image_file):input_image, real_image = load(image_file)input_image, real_image = random_jitter(input_image, real_image)input_image, real_image = normalize(input_image, real_image)return input_image, real_image
4.6 处理测试集图片
def load_image_test(image_file):input_image, real_image = load(image_file)input_image, real_image = resize(input_image, real_image,IMG_HEIGHT, IMG_WIDTH)input_image, real_image = normalize(input_image, real_image)return input_image, real_image
4.7 将训练集所有图片进行切片操作,放入一个dataset中
BUFFER_SIZE = 400
BATCH_SIZE = 1train_dataset = tf.data.Dataset.list_files(PATH+'train/*.jpg')
train_dataset = train_dataset.map(load_image_train,num_parallel_calls=tf.data.experimental.AUTOTUNE)
train_dataset = train_dataset.shuffle(BUFFER_SIZE)
train_dataset = train_dataset.batch(BATCH_SIZE)
4.8 将测试集所有图片进行切片操作,放入一个dataset中
test_dataset = tf.data.Dataset.list_files(PATH+'test/*.jpg')
test_dataset = test_dataset.map(load_image_test)
test_dataset = test_dataset.batch(BATCH_SIZE)
5、定义网络结构
5.1 定义下采样函数
为了不每次都在网络中定义批归一化层和激活函数层,我们先定义一个下采样函数,其中包括池化层、批归一化层以及LeakyReLU() 激活函数层。
OUTPUT_CHANNELS = 3
def downsample(filters, size, apply_batchnorm=True):initializer = tf.random_normal_initializer(0., 0.02)result = tf.keras.Sequential()result.add(tf.keras.layers.Conv2D(filters, size, strides=2, padding='same',kernel_initializer=initializer, use_bias=False))if apply_batchnorm:result.add(tf.keras.layers.BatchNormalization())result.add(tf.keras.layers.LeakyReLU())return result
5.2 定义上采样函数
def upsample(filters, size, apply_dropout=False):initializer = tf.random_normal_initializer(0., 0.02)result = tf.keras.Sequential()result.add(tf.keras.layers.Conv2DTranspose(filters, size, strides=2,padding='same',kernel_initializer=initializer,use_bias=False))result.add(tf.keras.layers.BatchNormalization())if apply_dropout:result.add(tf.keras.layers.Dropout(0.5))result.add(tf.keras.layers.ReLU())return result
5.3 定义生成器(UNet网络)
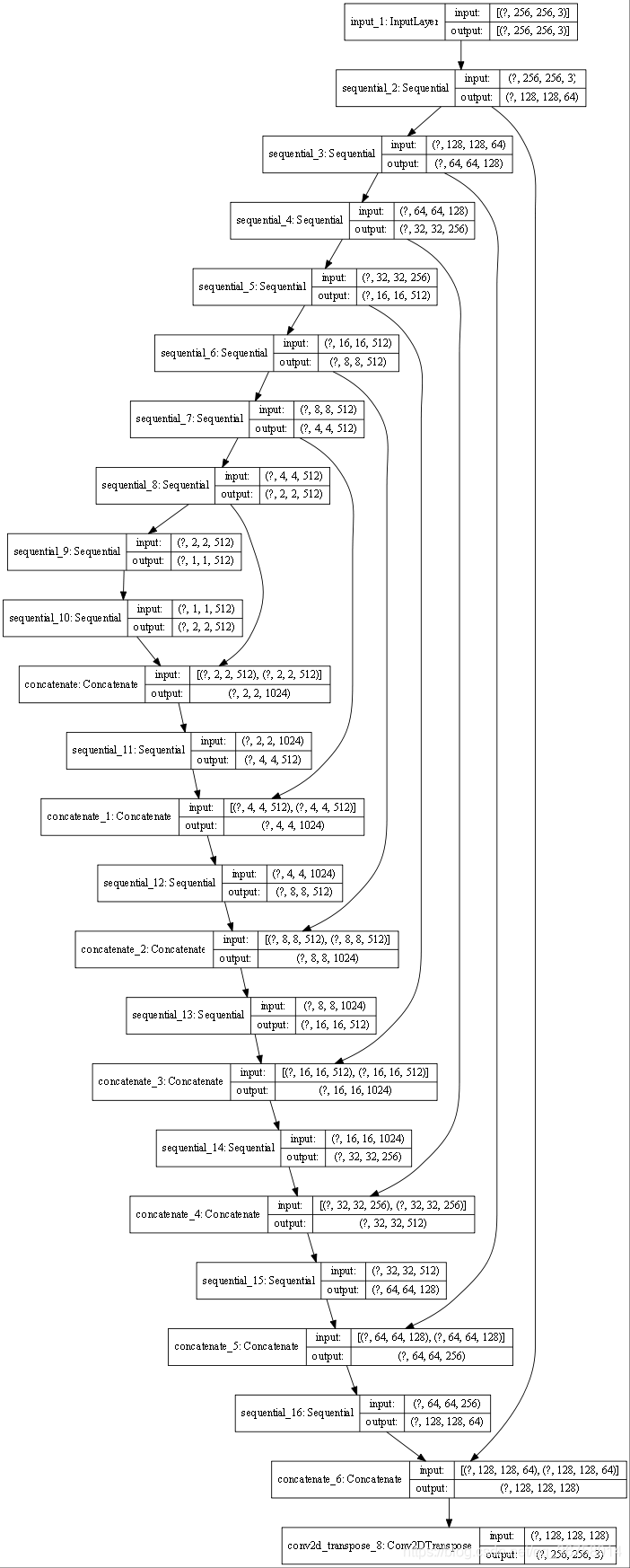
def Generator():inputs = tf.keras.layers.Input(shape=[256,256,3])down_stack = [downsample(64, 4, apply_batchnorm=False), # (bs, 128, 128, 64)downsample(128, 4), # (bs, 64, 64, 128)downsample(256, 4), # (bs, 32, 32, 256)downsample(512, 4), # (bs, 16, 16, 512)downsample(512, 4), # (bs, 8, 8, 512)downsample(512, 4), # (bs, 4, 4, 512)downsample(512, 4), # (bs, 2, 2, 512)downsample(512, 4), # (bs, 1, 1, 512)]up_stack = [upsample(512, 4, apply_dropout=True), # (bs, 2, 2, 512)+(bs, 2, 2, 512)=(bs, 2, 2, 1024)upsample(512, 4, apply_dropout=True), # (bs, 4, 4, 1024)upsample(512, 4, apply_dropout=True), # (bs, 8, 8, 1024)upsample(512, 4), # (bs, 16, 16, 1024)upsample(256, 4), # (bs, 32, 32, 512)upsample(128, 4), # (bs, 64, 64, 256)upsample(64, 4), # (bs, 128, 128, 128)]initializer = tf.random_normal_initializer(0., 0.02)last = tf.keras.layers.Conv2DTranspose(OUTPUT_CHANNELS, 4,strides=2,padding='same',kernel_initializer=initializer,activation='tanh') # (bs, 256, 256, 3)x = inputs# Downsampling through the modelskips = []for down in down_stack:x = down(x)skips.append(x)skips = reversed(skips[:-1])# Upsampling and establishing the skip connectionsfor up, skip in zip(up_stack, skips):x = up(x) # 第一个x是(bs, 1, 1, 512)x = tf.keras.layers.Concatenate()([x, skip])x = last(x)return tf.keras.Model(inputs=inputs, outputs=x)
5.4 查看生成器结构
generator = Generator()
tf.keras.utils.plot_model(generator, show_shapes=True, dpi=64)
5.5定义判别器(PatchGAN网络)
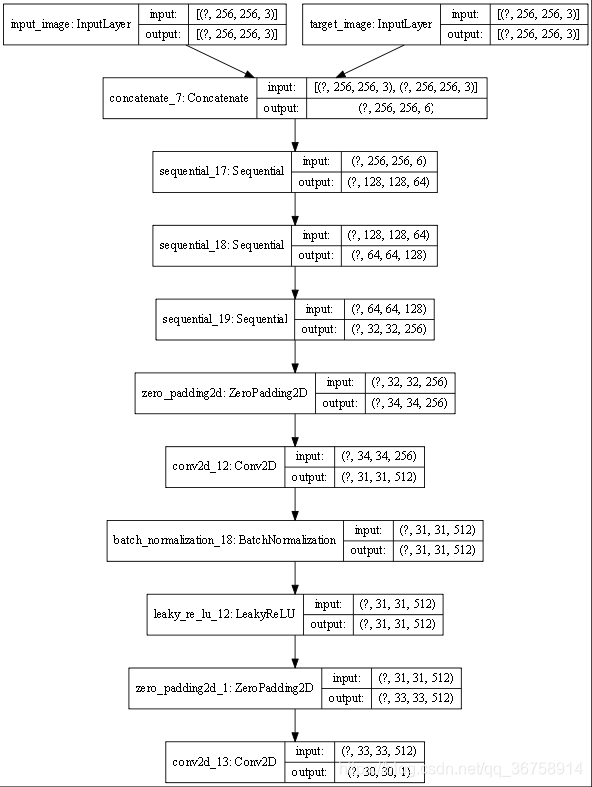
def Discriminator():initializer = tf.random_normal_initializer(0., 0.02)inp = tf.keras.layers.Input(shape=[256, 256, 3], name='input_image')tar = tf.keras.layers.Input(shape=[256, 256, 3], name='target_image')x = tf.keras.layers.concatenate([inp, tar]) # (bs, 256, 256, channels*2)down1 = downsample(64, 4, False)(x) # (bs, 128, 128, 64)down2 = downsample(128, 4)(down1) # (bs, 64, 64, 128)down3 = downsample(256, 4)(down2) # (bs, 32, 32, 256)zero_pad1 = tf.keras.layers.ZeroPadding2D()(down3) # (bs, 34, 34, 256)conv = tf.keras.layers.Conv2D(512, 4, strides=1,kernel_initializer=initializer,use_bias=False)(zero_pad1) # (bs, 31, 31, 512)batchnorm1 = tf.keras.layers.BatchNormalization()(conv)leaky_relu = tf.keras.layers.LeakyReLU()(batchnorm1)zero_pad2 = tf.keras.layers.ZeroPadding2D()(leaky_relu) # (bs, 33, 33, 512)last = tf.keras.layers.Conv2D(1, 4, strides=1,kernel_initializer=initializer)(zero_pad2) # (bs, 30, 30, 1)return tf.keras.Model(inputs=[inp, tar], outputs=last)
5.6 查看判别器结构
discriminator = Discriminator()
tf.keras.utils.plot_model(discriminator, show_shapes=True, dpi=64)
6、定义损失函数
6.1 定义生成器损失函数

LAMBDA = 100
loss_object = tf.keras.losses.BinaryCrossentropy(from_logits=True)def generator_loss(disc_generated_output, gen_output, target):gan_loss = loss_object(tf.ones_like(disc_generated_output), disc_generated_output)# mean absolute errorl1_loss = tf.reduce_mean(tf.abs(target - gen_output))total_gen_loss = gan_loss + (LAMBDA * l1_loss)return total_gen_loss, gan_loss, l1_loss
一部分损失来源于将生成图片输入判别器后得到的结果与1(判定为真)之间的交叉熵损失;另一部分损失来自生成的图像与真实建筑图像之间的L1损失。
6.2 定义判别器损失函数

def discriminator_loss(disc_real_output, disc_generated_output):real_loss = loss_object(tf.ones_like(disc_real_output), disc_real_output)generated_loss = loss_object(tf.zeros_like(disc_generated_output), disc_generated_output)total_disc_loss = real_loss + generated_lossreturn total_disc_loss
一部分损失来源于将生成图片输入判别器后得到的结果与0(判定为假)之间的交叉熵损失;另一部分损失来自将真实建筑图片输入判别器后得到的结果与1(判定为真)之间的交叉熵损失。
7、定义优化函数
generator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
8、定义图像生成并显示的函数
def generate_images(model, test_input, tar):prediction = model(test_input, training=True)plt.figure(figsize=(15,15))display_list = [test_input[0], tar[0], prediction[0]]title = ['Input Image', 'Ground Truth', 'Predicted Image']for i in range(3):plt.subplot(1, 3, i+1)plt.title(title[i])# getting the pixel values between [0, 1] to plot it.plt.imshow(display_list[i] * 0.5 + 0.5)plt.axis('off')plt.show()
此函数的作用是将输入图像、真实建筑图像以及输出的图像一起显示出来。如:
for example_input, example_target in test_dataset.take(1):generate_images(generator, example_input, example_target)

9、定义一次梯度下降过程
def train_step(input_image, target, epoch):with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:gen_output = generator(input_image, training=True)disc_real_output = discriminator([input_image, target], training=True)disc_generated_output = discriminator([input_image, gen_output], training=True)gen_total_loss, gen_gan_loss, gen_l1_loss = generator_loss(disc_generated_output, gen_output, target)disc_loss = discriminator_loss(disc_real_output, disc_generated_output)generator_gradients = gen_tape.gradient(gen_total_loss,generator.trainable_variables)discriminator_gradients = disc_tape.gradient(disc_loss,discriminator.trainable_variables)generator_optimizer.apply_gradients(zip(generator_gradients,generator.trainable_variables))discriminator_optimizer.apply_gradients(zip(discriminator_gradients,discriminator.trainable_variables))
10、训练模型
10.1 定义训练过程
训练过程:首先选择一组测试集图片(包括输入图片与真实建筑图片),将模型在训练集中训练epochs次,每训练完一次(遍历一遍训练集)就将此模型应用到刚才选择的测试集图片中并显示结果。
def fit(train_ds, epochs, test_ds):for epoch in range(epochs):display.clear_output(wait=True)for example_input, example_target in test_ds.take(1):generate_images(generator, example_input, example_target)print("Epoch: ", epoch)# Trainfor n, (input_image, target) in train_ds.enumerate():print('.', end='')if (n+1) % 100 == 0:print()train_step(input_image, target, epoch)print()
10.2 开始训练
EPOCHS = 100
fit(train_dataset, EPOCHS, test_dataset)
得到最终结果:

参考资料
生成对抗网络系列(4)——pix2pix
一文读懂GAN, pix2pix, CycleGAN和pix2pixHD
[GAN笔记] pix2pix