参考(40条消息) 全文翻译&杂记《Image-to-Image Translation with Conditional Adversarial NetWorks》_Maples丶丶的博客-CSDN博客_image-to-image translation
图像到图像通常有特定方法(没有通用),但本质是像素到像素的映射问题。本文利用 条件生成对抗(CGAN),实现语义/标签 -- > 真实图像等
摘要
利用CGAN得到图像转换的通用解决方案。
-
输入到输出的映射关系
-
用于映射关系的函数
该网络能学习上面两件事
前言
困难:图像之间的转换定义为场景的可能表示之间的转换,图像之间的映射不是一一对应。CNNs作为图像预测的主力,缺点在于需要我们告诉她loss函数;GANs能区分真实图像和伪造图像,而不用告诉loss函数,本文分析建立在GANs之上。
相关工作
-
图像建模的结构loss
结构化loss也就是像素之间存在关联,大多数文献考虑这种loss,如条件随机场、SSIM度量、特征匹配、非参数loss、convolutional pseudo-prior以及基于匹配协方差统计的loss。pix2pix理论上能对不同于目标的任何可能结构进行惩罚。
-
条件GANs
先前有离散标签、文本及图像作为约束的先例。
方法
图片x + 随机噪声向量z => 输出图像y
-
目标函数
在这里发现生成器简单的忽略了噪声输入,即使用dropout作为噪声输入也只产生微小的随机性
-
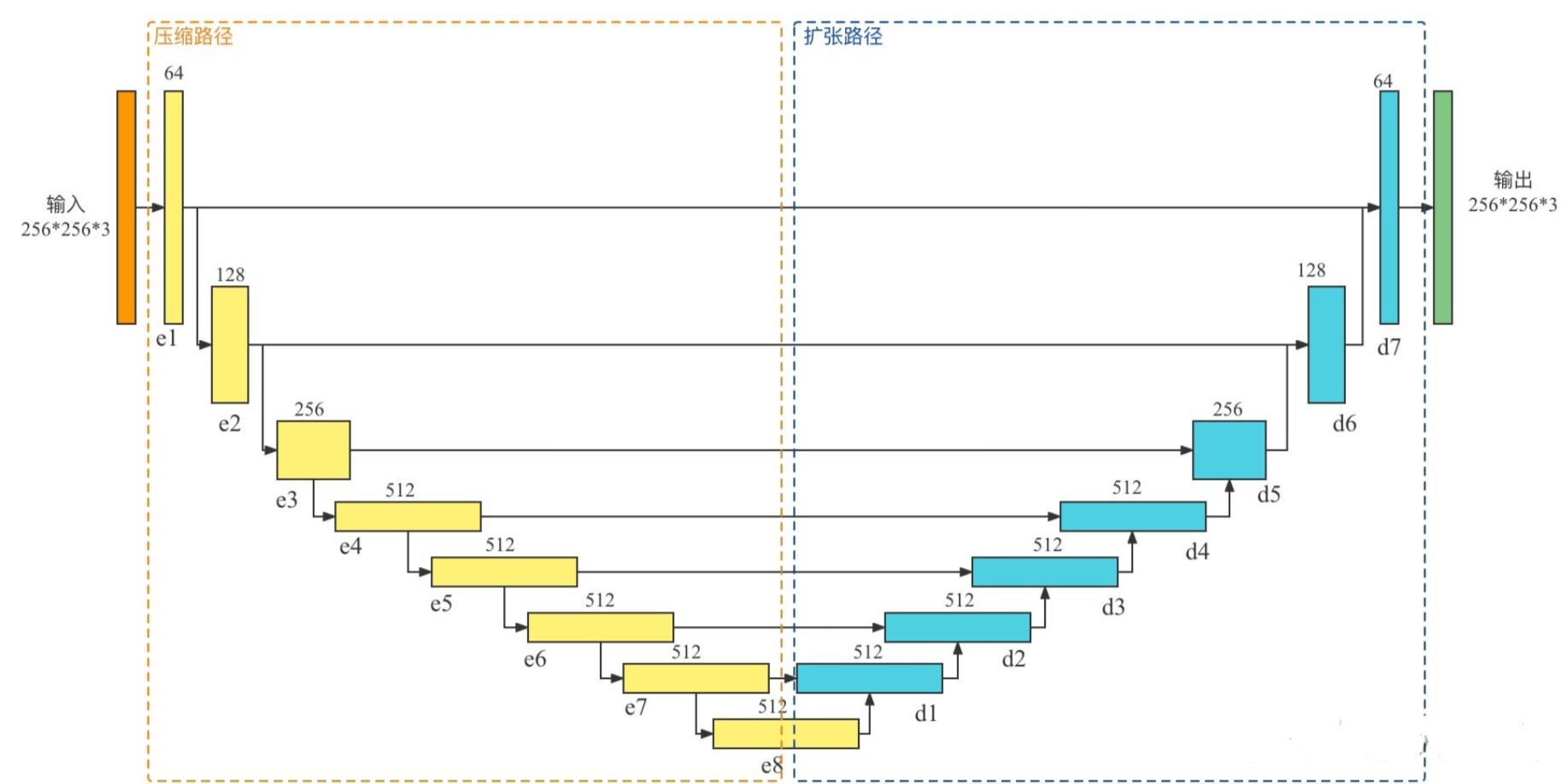
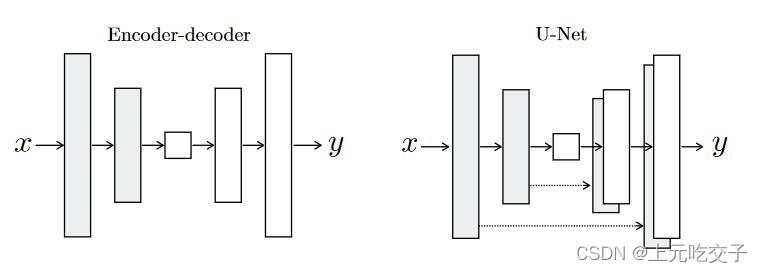
网络结构
生成器和判别器都使用
conv-BatchNorm-ReLu的卷积单元形式。主要特征:-
带有跳线
底层结构一致,输入输出基本对齐。对于图像转换问题,输入输出之间存在很多可以共享的低级信息。
-
2. 马尔可夫、patchGAN
L1能准确地捕捉低频信息,利用patches对高频结构建模,马尔可夫假设也就是通过patch直径分割的像 素之间独立,是纹理、风格建模中的常用假设。
3. 优化与推理
交替训练D、G,使用minivatch SGD和Adam优化器。batch size为1 和 4 差别不大
实验
在各种任务和数据集上测试了该项目
评估指标
MSE传统指标不涉及结果。
-
AWT感知。
也就是利用人工分辨,每个turker只允许进行1组(一种算法),每个算法有50turkers来测试,真假图片不是来自同一输入
-
FCN分数
用真实图像训练的分类器有能力对生成图片进行分割,以此来为合成照片打分
目标函数分析
-
分析loss函数哪个成分重要
只有L1 图像模糊,只有cGAN 有不自然的地方。L1鼓励平均、灰度化的颜色。cGAN一个显著优点:生成合成标签中不存在的空间结构,生成图像清晰。
生成器结构分析
-
U-Net使得结果更好,encoder-decoder 无法学会生成真实图像
-
判别器接受域,1X1有利于结果色彩效果,但图像模糊;70X70较为清晰,256X256可能参数过多,难以训练