1. 摘要
图像处理的很多问题都是将一张输入的图片转变为一张对应的输出图片,比如灰度图、梯度图、彩色图之间的转换等。通常每一种问题都使用特定的算法(如:使用CNN来解决图像转换问题时,要根据每个问题设定一个特定的loss function 来让CNN去优化,而一般的方法都是训练CNN去缩小输入跟输出的欧氏距离,但这样通常会得到比较模糊的输出)。这些方法的本质其实都是从像素到像素的映射。于是论文在GAN的基础上提出一个通用的方法:pix2pix 来解决这一类问题。通过pix2pix来完成成对的图像转换(Labels to Street Scene, Aerial to Map,Day to Night等),可以得到比较清晰的结果。
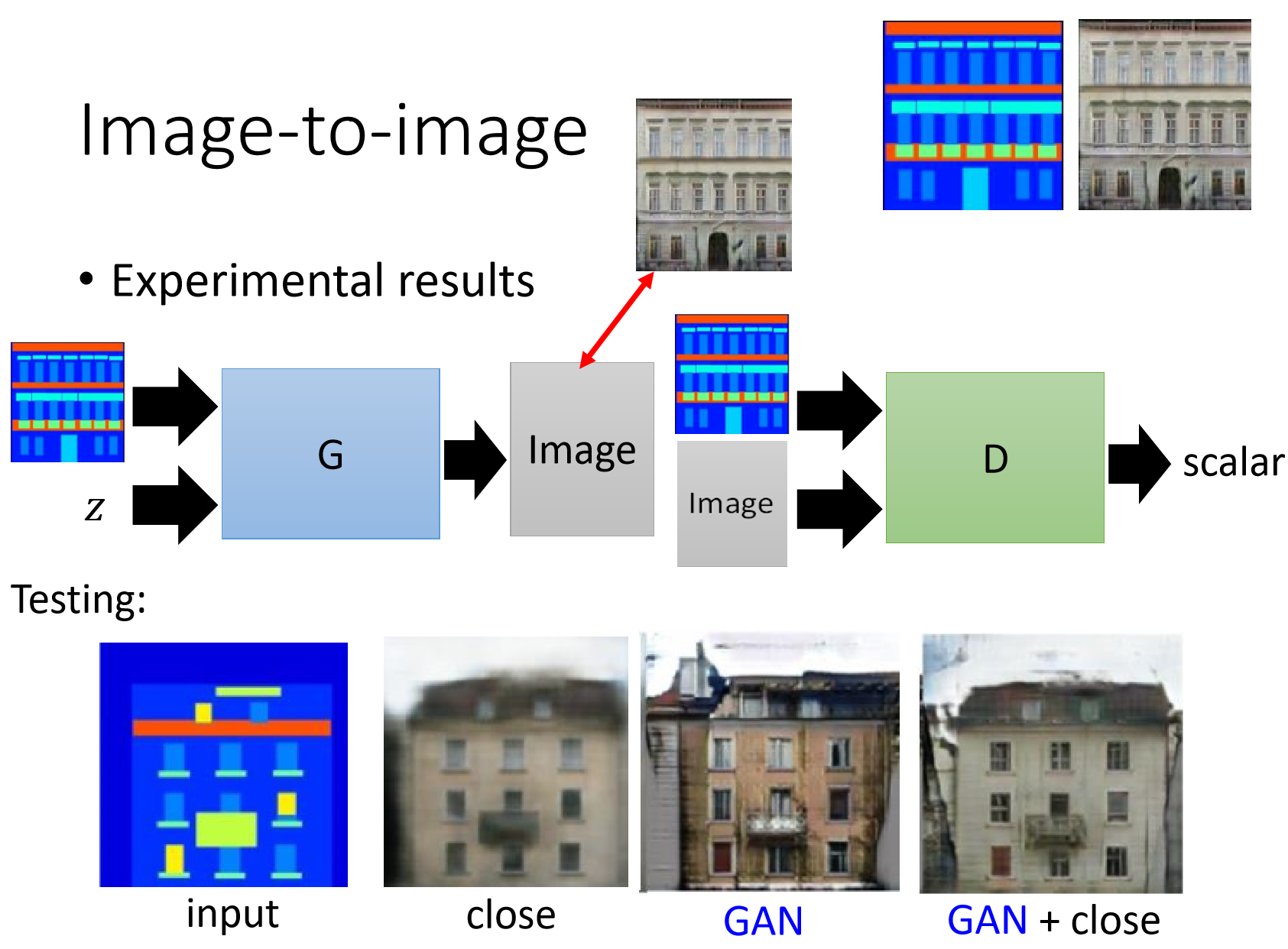
先看一张效果图:

2. 网络结构

上图描述了本文中的图像到图像转换架构的一个抽象的high-level view。与许多图像合成模型类似,它使用Conditional-GAN框架。图像x被用作生成器Generator的输入和作为鉴别器Discriminator的输入。
论文对DCGAN的生成器和判别器的结构做了一些改进。
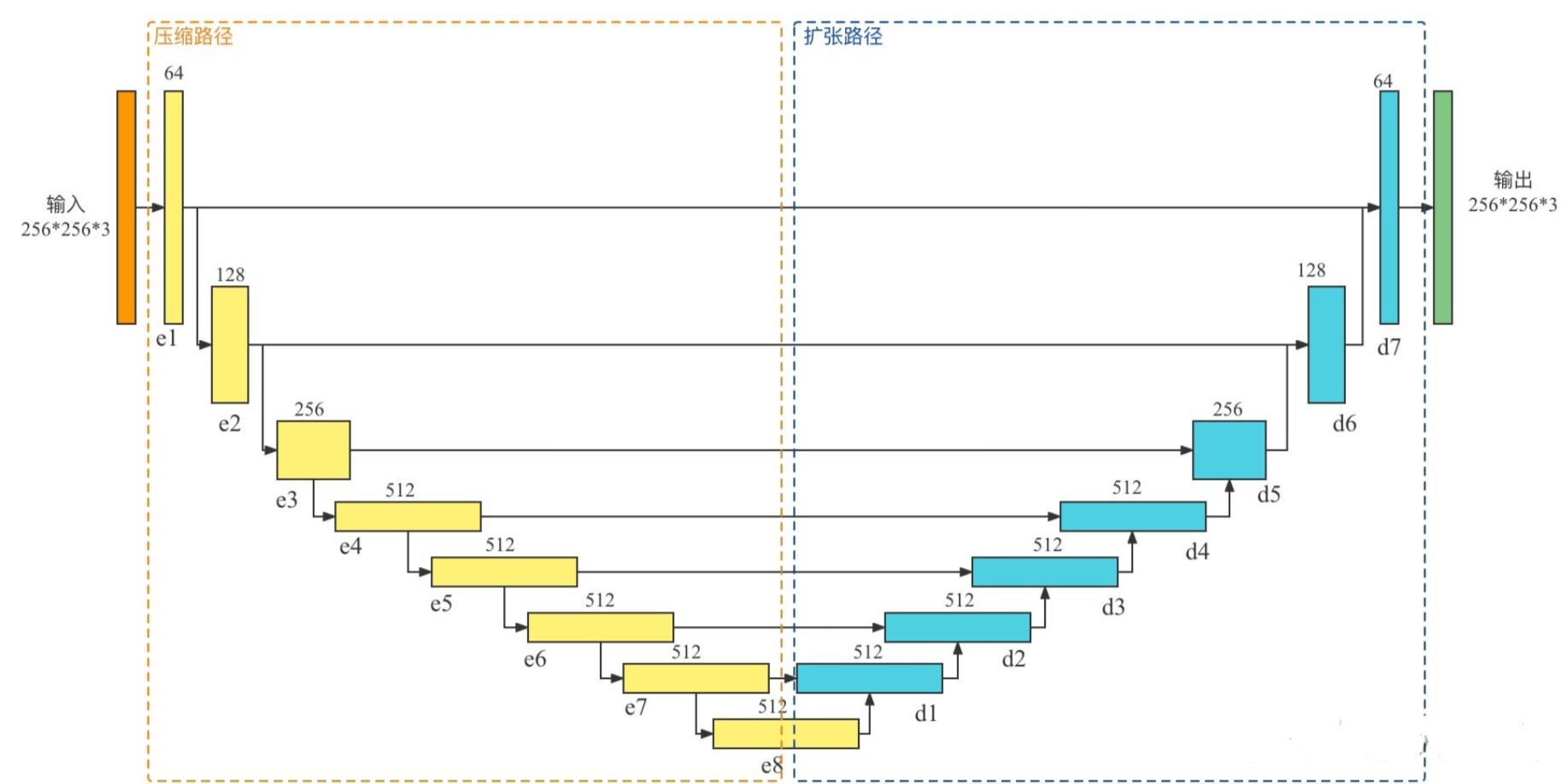
2.1 生成器结构

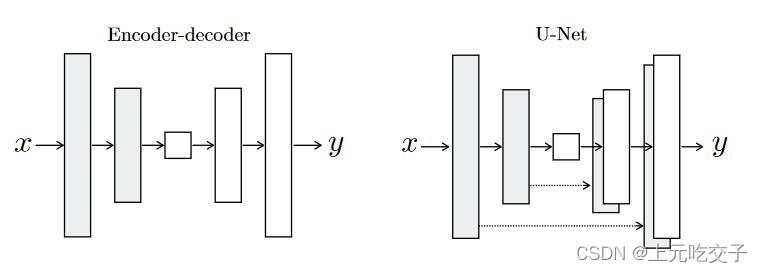
U-Net是德国Freiburg大学模式识别和图像处理组提出的一种全卷积结构。和常见的先降采样到低维度,再升采样到原始分辨率的编解码(Encoder-Decoder)结构的网络相比,U-Net的区别是加入skip-connection,对应的feature maps和decode之后的同样大小的feature maps按通道拼(concatenate)一起,用来保留不同分辨率下像素级的细节信息。U-Net对提升细节的效果非常明显,下面是文中给出的一个效果对比,可以看到不同尺度的信息都得到了很好的保留。

2.2 鉴别器结构
pix2pix中使用的PatchGAN鉴别器是该设计的另一个独特组成部分。PatchGAN / Markovian鉴别器的工作原理是将图像中的独立的patches分类为“真实与假”,而不是将整个图像分类为“真实与假”。作者认为这会强制实施更多约束,从而鼓励出现尖锐的高频细节(sharp high-frequency detail)。此外,PatchGAN具有更少的参数,并且比分类整个图像运行得更快。下图描绘了不同N大小的情况下,对N x N 大小的patches进行分类的实验结果:

3. 目标函数
pix2pix的优化目标包含2个部分,如下所示。一部分是cGAN的优化目标;另一部分是L1距离,用来约束生成图像和真实图像之间的差异,这部分借鉴了其他基于GAN做图像翻译的思想,只不过这里用L1而不是L2,目的是减少生成图像的模糊。

cGAN的优化目标如公式1所示,z表示随机噪声,判别器D的优化目标是使得公式1的值越大越好,而生成器G的优化目标是使得公式1的log(1-D(x,G(x,z))越小越好,这也就是公式4中min和max的含义。这里需要注意的是正如GAN论文提到的,公式1有时候训练容易出现饱和现象,也就是判别器D很强大,但是生成器G很弱小,导致G基本上训练不起来,因此可以将生成器G的优化目标从最小化log(1-D(x,G(x,z))修改为最大化log(D(x,G(x,z))),pix2pix算法采用修改后的优化目标。

L1距离如公式3所示,用来约束生成图像G(x, z)和真实图像y之间的差异。

4. pix2pix实验结果
Table1是关于不同损失函数的组成效果对比, 这里采用的是基于分割标签得到图像的任务。评价时候采用语义分割算法FCN对生成器得到的合成图像做语义分割得到分割图,假如合成图像足够真实,那么分割结果也会更接近真实图像的分割结果,分割结果的评价主要采用语义分割中常用的基于像素点的准确率和IOU等。

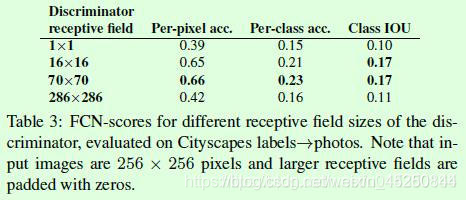
Table2是关于不同生成器的效果,主要是encoder-decoder和U-Net的对比。
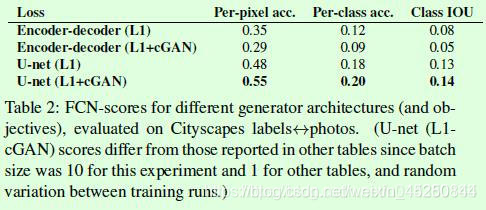
Table3是关于判别器PatchGAN采用不同大小N的实验结果,其中1 ∗ 1 111∗1表示以像素点为单位判断真假,显然这样的判断缺少足够的信息,因此效果不好;286 ∗ 286 286286286∗286表示常规的以图像为单位判断真假,这是比较常规的做法,从实验来看效果也一般。中间2行是介于前两者之间的PatchGAN的效果,可以看到基于区域来判断真假效果较好。
最后放一下pix2pix的生成图像,可以基于图像边缘得到图像、基于语义分割的标签得到图像、背景去除、图像修复等。更多结果可以参考原论文,效果还是很不错的。

5. pix2pixHD
这篇paper作为pix2pix的改进版本,如其名字一样,主要是可以产生高分辨率的图像。具体来说,作者的贡献主要在以下两个方面:
- 使用多尺度的生成器以及判别器等方式从而生成高分辨率图像。
- 使用了一种非常巧妙的方式,实现了对于同一个输入,产生不同的输出。并且实现了交互式的语义编辑方式,这一点不同于pix2pix中使用dropout保证输出的多样性。
5.1 高分辨率图片生成
为了生成高分辨率图像,作者主要从三个层面做了改进:
- 模型结构:coarse-to-fine的生成器。
- Loss设计:multi-scale的判别器。这个比较简单,就是在三个不同尺度上判别,然后取平均。更好的loss设计,总loss = GAN loss + Feature matching loss + Content loss。
- 使用Instance-map的图像进行训练。
5.2 模型结构
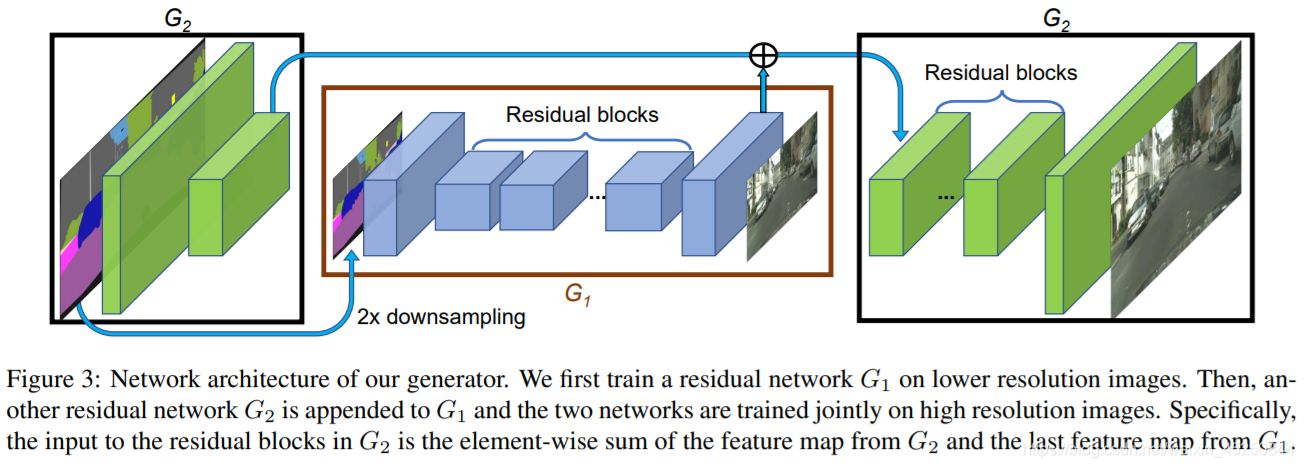
如上图,生成的流程:图片先经过一个生成器 G 2 G_2 G2的卷积层进行2倍下采样,然后使用另一个生成器 G 1 G_1 G1生成低分辨率的图,将得到的结果和刚刚下采样得到的图进行element-wise的相加,然后输出到 G 2 G_2 G2的后续网络生成高分辨率的图片。
这么做的好处是,低分辨率的生成器会学习到全局的连续性(越粗糙的尺度感受野越大,越重视全局一致性),高分辨率的生成器会学习到局部的精细特征,因此生成的图片会兼顾局部特征和全局特征的真实性。如果仅使用高分辨率的图生成的话,精细的局部特征可能比较真实,但是全局的特征就不那么真实了。
判别器使用多尺度判别器,在三个不同的尺度上进行判别并对结果取平均。判别的三个尺度为:原图,原图的1/2降采样,原图的1/4降采样(实际做法为在不同尺度的特征图上进行判别,而非对原图进行降采样)。显然,越粗糙的尺度感受野越大,越关注全局一致性。
生成器和判别器均使用多尺度结构实现高分辨率重建,思路和PGGAN类似,但实际做法差别比较大。
5.2 损失函数
这里的Loss由三部分组成:
- GAN loss:和pix2pix一样,使用PatchGAN。
- Feature matching loss:将生成的样本和Ground truth分别送入判别器提取特征,然后对特征做Element-wise loss
- Content loss:将生成的样本和Ground truth分别送入VGG16提取特征,然后对特征做Element-wise loss

使用Feature matching loss和Content loss计算特征的loss,而不是计算生成样本和Ground truth的MSE,主要在于MSE会造成生成的图像过度平滑,缺乏细节。Feature matching loss和Content loss只保证内容一致,细节则由GAN去学习。
5.3 使用Instance-map的图像进行训练
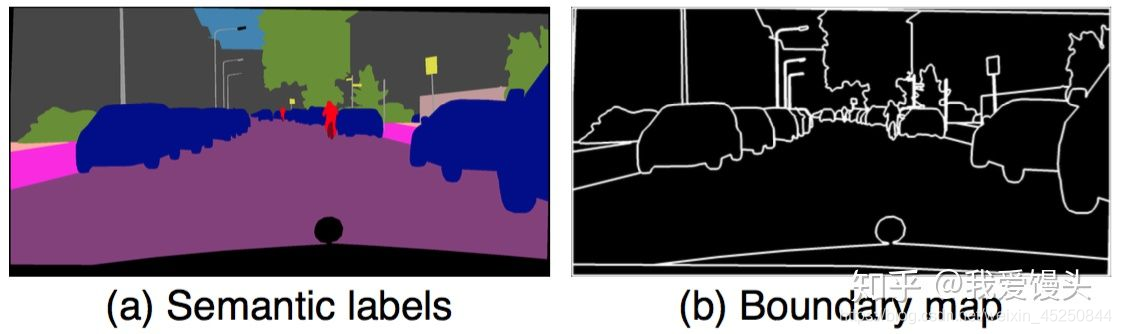
pix2pix采用语义分割的结果进行训练,可是语义分割结果没有对同类物体进行区分,导致多个同一类物体排列在一起的时候出现模糊,这在街景图中尤为常见。在这里,作者使用个体分割(Instance-level segmention)的结果来进行训练,因为个体分割的结果提供了同一类物体的边界信息。具体做法如下:
- 根据个体分割的结果求出Boundary map
- 将Boundary map与输入的语义标签concatnate到一起作为输入 Boundary map求法很简单,直接遍历每一个像素,判断其4邻域像素所属语义类别信息,如果有不同,则置为1。下面是一个示例:
5.4 语义编辑
不同于pix2pix实现生成多样性的方法(使用Dropout),这里采用了一个非常巧妙的办法,即学习一个条件(Condition)作为条件GAN的输入,不同的输入条件就得到了不同的输出,从而实现了多样化的输出,而且还是可编辑的。具体做法如下:

- 首先训练一个编码器
- 利用编码器提取原始图片的特征,然后根据Labels信息进行Average pooling,得到特征(上图的Features)。这个Features的每一类像素的值都代表了这类标签的信息。
- 如果输入图像有足够的多,那么Features的每一类像素的值就代表了这类物体的先验分布。 对所有输入的训练图像通过编码器提取特征,然后进行K-means聚类,得到K个聚类中心,以K个聚类中心代表不同的颜色,纹理等信息。
- 实际生成图像时,除了输入语义标签信息,还要从K个聚类中心随机选择一个,即选择一个颜色/纹理风格
这个方法总的来说非常巧妙,通过学习数据的隐变量达到控制图像颜色纹理风格信息。
5.5 总结
pix2pix主要的贡献在于:
- 提出了生成高分辨率图像的多尺度网络结构,包括生成器,判别器
- 提出了Feature loss和VGG loss提升图像的分辨率 - 通过学习隐变量达到控制图像颜色,纹理风格信息
- 通过Boundary map提升重叠物体的清晰度
可以看出,这篇paper除了第三点,都是针对性的解决高分辨率图像生成的问题的。