本文是翻译的github这个项目的博客https://guillaumegenthial.github.io/sequence-tagging-with-tensorflow.html。
为什么要用biLSTM?为了使特征提取自动化。当使用CRF++工具来进行命名实体识别时,需要自定义模板(或者使用默认的模板)。
任务和数据
任务是进行命名实体识别(named entity recognition),例如:

在CoNLL2003任务中,实体是LOC,PER,ORG,MISC,也就是位置,人名,组织名和杂项(miscellaneous),非实体表示为“0”。由于一些实体由多个单词组成,使用标签结构来区分实体的开始(B-...),和实体内(I-...),其他还有例如“IOBES”等结构。
想一想,我们需要的就是一个能给句子中的每个词一个类别的系统,而这个类别也就是对应的标签。
但为什么我们不直接把所有的地点,常见姓名和组织名保存成一个列表呢?是因为有很多实体,例如姓名和组织名是人为构造的,而怎样构造,我们没有先验知识。所以,我们其实是需要能够从句子中提取出上下文信息的工具。
假设数据保存在.txt文件中,一行是一个单词和是否是实体的标志,如下所示:

模型
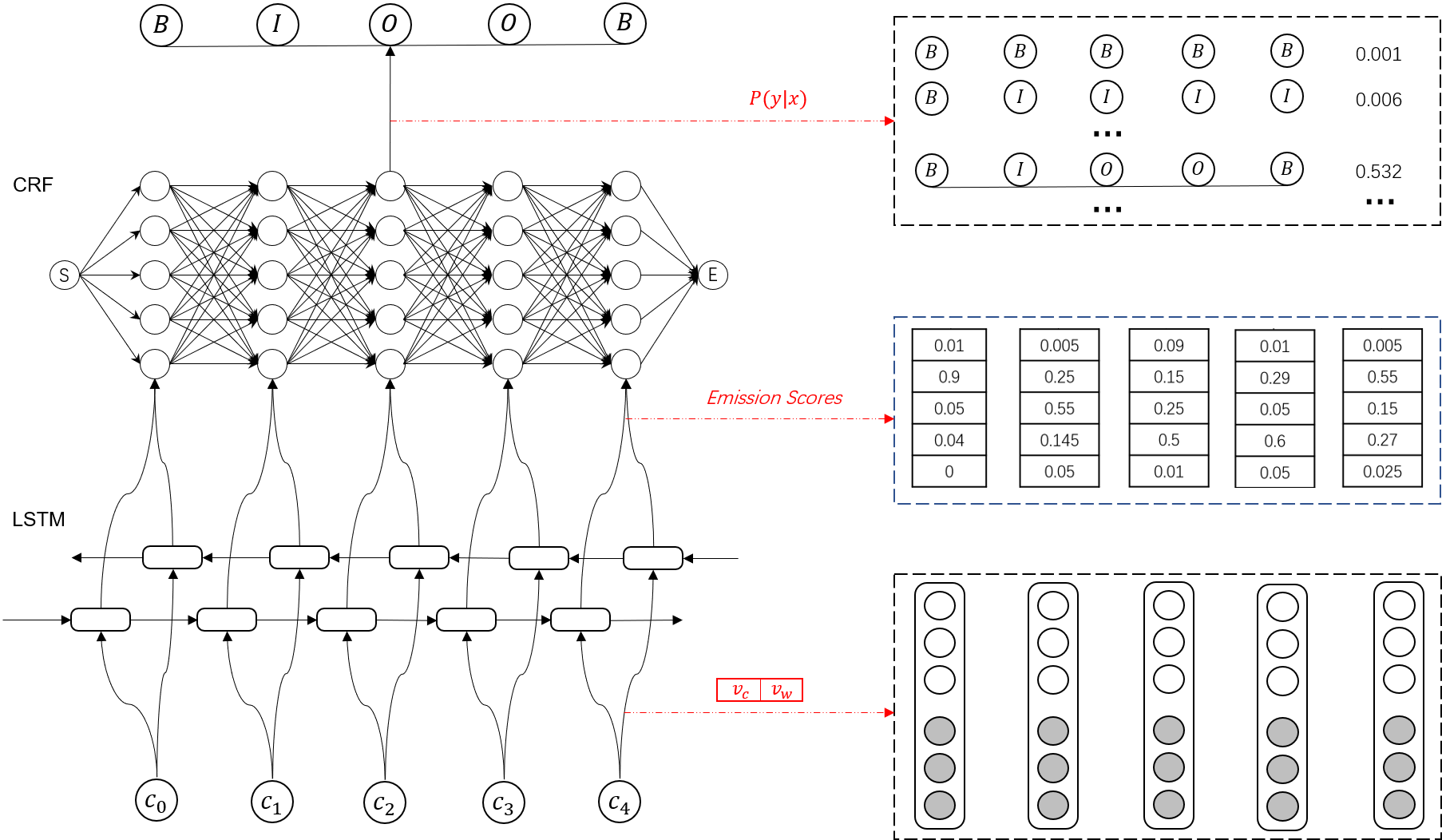
正如大多数NLP系统一样,我们在某些部分依赖循环神经网络。将模型分成以下3部分:
1.词表示。使用紧密(dense)向量表示每个词,加载预先训练好的词向量(GloVe,Word2Vec,Senna等)。我们也将从单个字(单个字母)中提取一些含义。为什么也需要单个字呢?正如我们之前所说,有很多实体没有预先训练好的词向量,而且开头是大写字母会对识别出实体有用。
2.上下文单词表示。对上下文中的每一个词,需要有一个有意义的向量表示。使用LSTM来获取上下文中单词的向量表示。
3.解码。当我们有每个词的向量表示后,来进行实体标签的预测。
词向量表示
对每一个词,我们需要构建一个向量来获取这个词的意思以及对实体识别有用的一些特征,这个向量由Glove训练的词向量和从字母中提取出特征的向量堆叠而成。一个选择是使用手动提取的特征,例如单词是否是大写字母开头等。另一种更美好的选择是使用某种神经网络来自动提取特征。在这里,对单个字母使用bi-LSTM,当然也可以使用其他循环神经网络,或者对单个字母或n-gram使用CNN。

组成一个单词的每个字母都由一个向量表示(注意大写和小写是区分开来的),对每个字母使用bi-LSTM,并将最后状态堆叠起来获得一个固定长度的向量。直觉上,这个向量获取到了这个词的形态。然后,我们将词向量和字母向量合并,获得这个词最终的向量表示。
Tensorflow处理批量的词和数据,因此需要将句子填充到相同的长度,定义2个placeholder:
# shape = (batch size, max length of sentence in batch)
word_ids = tf.placeholder(tf.int32, shape=[None, None])# shape = (batch size)
sequence_lengths = tf.placeholder(tf.int32, shape=[None])使用tensorflow内置的函数来加载词向量。假设embeddings是一个保存这GloVe向量的数组,那么embeddings[i]就是第i和单词的词向量。
L = tf.Variable(embeddings, dtype=tf.float32, trainable=False)
# shape = (batch, sentence, word_vector_size)
pretrained_embeddings = tf.nn.embedding_lookup(L, word_ids)接下来构建单个字母的表示,对词也需要填充到相同的长度,定义2个placeholder:
# shape = (batch size, max length of sentence, max length of word)
char_ids = tf.placeholder(tf.int32, shape=[None, None, None])# shape = (batch_size, max_length of sentence)
word_lengths = tf.placeholder(tf.int32, shape=[None, None])
为什么我们到处都使用None?为什么我们需要使用None呢?
这取决于我们如何填充,在这里,我们选择动态填充,例如在一个batch中,将batch中的句子填充到这个batch的最大长度。因此,句子长度和词的长度取决与这个batch。
接下来构造字母向量(character embeddings)。我们没有预训练的字母向量,使用tf.get_variable来初始化一个矩阵。然后改变这个4维tensor的形状来满足bidirectional_dynamic_rnn的输入要求。sequence_length这个参数使我们确保我们获得的最后状态是有效的最后状态。(因为batch中句子的实际长度不一样)
# 1. get character embeddings
K = tf.get_variable(name="char_embeddings", dtype=tf.float32,shape=[nchars, dim_char])
# shape = (batch, sentence, word, dim of char embeddings)
char_embeddings = tf.nn.embedding_lookup(K, char_ids)# 2. put the time dimension on axis=1 for dynamic_rnn
s = tf.shape(char_embeddings) # store old shape
# shape = (batch x sentence, word, dim of char embeddings)
char_embeddings = tf.reshape(char_embeddings, shape=[-1, s[-2], s[-1]])
word_lengths = tf.reshape(self.word_lengths, shape=[-1])# 3. bi lstm on chars
cell_fw = tf.contrib.rnn.LSTMCell(char_hidden_size, state_is_tuple=True)
cell_bw = tf.contrib.rnn.LSTMCell(char_hidden_size, state_is_tuple=True)_, ((_, output_fw), (_, output_bw)) = tf.nn.bidirectional_dynamic_rnn(cell_fw,cell_bw, char_embeddings, sequence_length=word_lengths,dtype=tf.float32)
# shape = (batch x sentence, 2 x char_hidden_size)
output = tf.concat([output_fw, output_bw], axis=-1)# shape = (batch, sentence, 2 x char_hidden_size)
char_rep = tf.reshape(output, shape=[-1, s[1], 2*char_hidden_size])# shape = (batch, sentence, 2 x char_hidden_size + word_vector_size)
word_embeddings = tf.concat([pretrained_embeddings, char_rep], axis=-1)上下文单词表示
当我们得到词最终的向量表示后,对词向量的序列进行LSTM或bi-LSTM。

这次,我们使用每一个时间点的隐藏状态,而不仅仅是最终状态。输入m个词向量,获得m个隐藏状态的向量,然而词向量只是包含词级别的信息,而隐藏状态的向量考虑了上下文。
cell_fw = tf.contrib.rnn.LSTMCell(hidden_size)
cell_bw = tf.contrib.rnn.LSTMCell(hidden_size)(output_fw, output_bw), _ = tf.nn.bidirectional_dynamic_rnn(cell_fw,cell_bw, word_embeddings, sequence_length=sequence_lengths,dtype=tf.float32)context_rep = tf.concat([output_fw, output_bw], axis=-1)解码
在解码阶段计算标签得分,使用每个词对应的隐藏状态向量来做最后预测,可以使用一个全连接神经网络来获取每个实体标签的得分。
假设我们有9个类别,使用和
来计算得分
,可以将s[i]理解为词w对应标签i的得分。
W = tf.get_variable("W", shape=[2*self.config.hidden_size, self.config.ntags],dtype=tf.float32)b = tf.get_variable("b", shape=[self.config.ntags], dtype=tf.float32,initializer=tf.zeros_initializer())ntime_steps = tf.shape(context_rep)[1]
context_rep_flat = tf.reshape(context_rep, [-1, 2*hidden_size])
pred = tf.matmul(context_rep_flat, W) + b
scores = tf.reshape(pred, [-1, ntime_steps, ntags])对标签得分进行解码,有两个选择。不管是哪个选择,都会计算标签序列的概率并找到概率最大的序列。
1.softmax:使用将得分转化为代表这个单词属于某个类别(标签)的概率,概率和为1。最后,标签序列的概率是每个位置标签概率的乘积。
2.线性crf: softmax方法是做局部选择,换句话说,即使bi-LSTM产生的h中包含了一些上下文信息,但标签决策仍然是局部的。我们没有利用周围的标签来帮助决策。例如:“New York”,当我们给了York “location”这个标签后,这应该帮助我们决定“New”对应location的起始位置。线性CRF定义了全局得分C

其中,T是9*9的转换矩阵,e,b是9维的向量,表示某个标签作为开头和结尾的成本。T包含了标签决策内的线性依赖关系,下一个标签依赖于上一个标签。

如果单看每个位置的得分,则标签序列PER-PER-LOC的得分(10+4+11)比PER-O-LOC的得分(10+3+11)高,但如果考虑标签之间的依赖关系,PER-O-LOC的得分(31)高于PER-PER-LOC的得分(26),而Pierre loves Pairs的标签序列就是PER-O-LOC。
要实现CRF计算得分,需要做2件事:
1. 找到得分最高的标签序列
2. 计算所有标签序列的概率分布?
要找到得分最高的标签序列,不可能计算所有的个标签得分,并甚至将每个标签得分标准化为概率。其中,m是句子的长度。使用动态方法找到得分最高的序列,假设有从t+1,...,m的序列得分,那么从t,...,m的序列得分是

每一个循环步骤的复杂度是
对一个10个词的句子来说,复杂度从下降到9*9*10=810
线性链CRF的最后一步是对所有可能序列的得分执行softmax,从而得到给定序列的概率。

是在时间t,标签为yt的所有序列得分的和。【为什么要定义这个值?为了对Z进行递归计算,减少计算量】


则给定标签序列的概率是

使用交叉熵损失函数作为目标函数进行训练,交叉熵损失定义为
,其中
是正确的标签序列,
使用crf对应的标签序列概率为
直接使用softmax对应的标签序列概率是
以下代码计算损失并返回转移矩阵T,计算crf的对数概率只需要一行代码
# shape = (batch, sentence)
labels = tf.placeholder(tf.int32, shape=[None, None], name="labels")log_likelihood, transition_params = tf.contrib.crf.crf_log_likelihood(
scores, labels, sequence_lengths)loss = tf.reduce_mean(-log_likelihood)
直接使用softmax后计算损失时,要注意padding,使用tf.sequence_mask来将序列长度转换成是否向量。
losses = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=scores, labels=labels)
# shape = (batch, sentence, nclasses)
mask = tf.sequence_mask(sequence_lengths)
# apply mask
losses = tf.boolean_mask(losses, mask)loss = tf.reduce_mean(losses)
之后定义训练操作:
optimizer = tf.train.AdamOptimizer(self.lr)
train_op = optimizer.minimize(self.loss)
当训练好模型后,如何使用模型进行预测?
当直接使用softmax时,则最好的序列就是在每个时间点选择最高得分的标签,用以下代码实现:
labels_pred = tf.cast(tf.argmax(self.logits, axis=-1), tf.int32)
当使用CRF时,需要动态编程,但也只需要一行代码。
# shape = (sentence, nclasses)
score = ...
viterbi_sequence, viterbi_score = tf.contrib.crf.viterbi_decode(score, transition_params)
补充一个问题:
为什么LSTM之后可以接CRF?
当没有使用深度学习来提取特征之前,输入CRF的是自定义的特征,满足特征,则得分为1,不满足,则得分为0。CRF可以看作当前位置的特征得分和标签转移的特征得分的得分和,然后选整个序列得分高的。
那直接把LSTM输出的拼接起来的词向量和句向量拼接起来的向量该如何理解呢?
https://blog.csdn.net/bobobe/article/details/80489303
这篇文章认为从LSTM输出的向量是相当于定义在结点上的特征函数,也就是上文中的![]() ,就是看当前词对标签结果的影响。但LSTM每个位置输出的向量的维度和标签个数一般是不一样的,标签个数远远少于输出向量的维度,但我觉得可以这样理解。
,就是看当前词对标签结果的影响。但LSTM每个位置输出的向量的维度和标签个数一般是不一样的,标签个数远远少于输出向量的维度,但我觉得可以这样理解。
也从这儿可以看出来,在CRF解码的时候 tf.contrib.crf.veterbi_decode()是需要另外传入transition_params参数的,就是底层的神经网络没有学习到转移的特征函数。
不知道理解的对不对,还望和大家一起探讨~