命名实体识别
命名实体识别(Named Entity Recognition,NER),指识别文本中具有特定意义的实体,包括人名、地名、机构名、专有名词等。
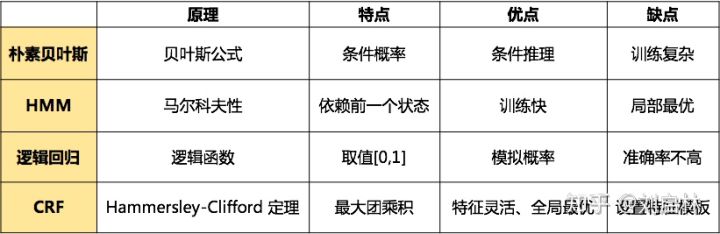
常用的方法如下。
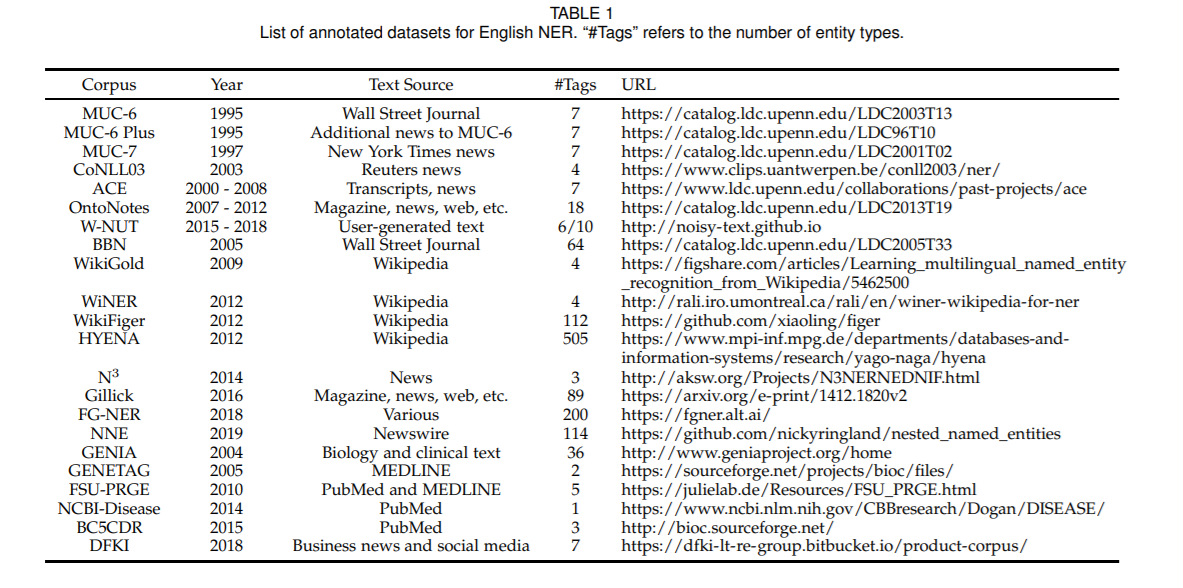
数据集一览
数据集下载地址 提取码:s249

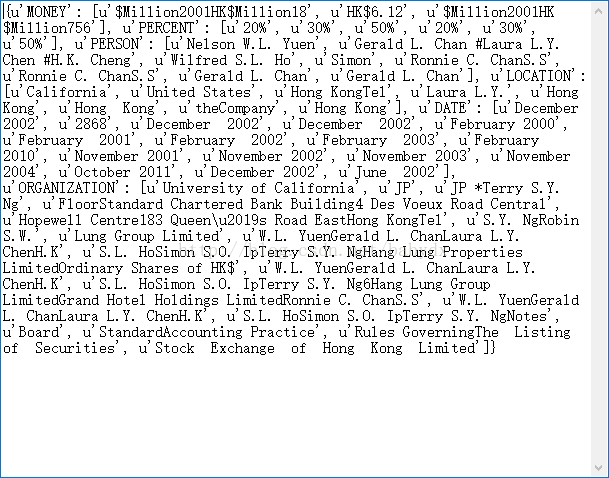
看一下我们的数据集,分为句子、单词、词性和标签。 在标签里面我们不关注的单词被标记为"O",而关注的是非"O",有
- geo 地点
- per 人名
- org 组织
详情请参考spacy中关于标签的定义
其中开头的"B"开始 某个实体的开始,"I"表示某个实体的剩下部分。
比如 B-geo 地点的开头,I-geo 地点的中间或结尾。

上图"Hyde Park"两个单词可以看成是一个专有名词,都表示地点。
词性的话这里就不展开了。
import pandas as pd
import numpy as np
data = pd.read_csv("./data/ner_dataset.csv", encoding="latin1")data = data.fillna(method="ffill") # 向下填充,以none上面的非none元素填充
data.tail(10)

words = list(set(data["Word"].values))
n_words = len(words)
print(n_words) #35178
总共有3万多个单词。
基于规则的方法
基于规则的方法想法简单,但实现起来比较繁琐。需要考虑的比较全面。
比如定义正则表达式来识别电话、邮箱、身份证号码等。 或者利用已定义的词典来匹配。
基于投票的方法
统计每个单词的实体类型,记录针对每个单词概率最大的实体类型。下次碰到这个单词,就认为是这个实体类型。
由于实现起来简单,不需要学习,准确率还可以,应该通常用作基准。
from sklearn.base import BaseEstimator, TransformerMixinclass MajorityVoting(BaseEstimator, TransformerMixin):def fit(self, X, y):"""X: 单词列表y: 单词对应的标签列表"""word2cnt = {}self.tags = []self.mjvote = {}for x, t in zip(X, y):if t not in self.tags:self.tags.append(t)if x in word2cnt:if t in word2cnt[x]:word2cnt[x][t] += 1else:word2cnt[x][t] = 1else:word2cnt[x] = {t: 1}for k, d in word2cnt.items():self.mjvote[k] = max(d, key=d.get)def predict(self, X, y=None):'''通过内存中缓存的多数投票结果预测单词的标签,未知单词预测为'O''''return [self.mjvote.get(x, 'O') for x in X]words = data["Word"].values.tolist()
tags = data["Tag"].values.tolist()from sklearn.model_selection import cross_val_predict
from sklearn.metrics import classification_reportmodel = MajorityVoting()pred = cross_val_predict(estimator=model, X=words, y=tags, cv=5)
report = classification_report(y_pred=pred, y_true=tags)print(report)

这种方法也能达到94%的一个准确率。
利用分类模型
要想利用分类模型,我们需要一些特征。这里就需要用到特征工程来提取单词的特征。
特征工程
提取每个单词的最简单的特征,比如单词长度。
以语句“The professor Colin proposed a(停止词) model for NER in 1999”为例,假设我们考虑单词“Colin”
特征词袋模型
- 当前词: Colin
- 前后词:professor,proposed
- 前前,后后词:the,model
- Bi-gram: professor Colin,Colin proposed,The professor,proposed model
- Tri-gram:…
词性特征
- 当前词:名词
- 前后词:名,动
- 前前,后后词:冠词,名词
- n-gram:…
前缀&后缀
- 当前词:Co,in
- 前后词:pr,or,pr,ed
- 前前,后后词:…
当前词的特性
- 词长
- 含有多个大写字母
- 是否大写开头(Title)
- 是否包含特殊符号(“-”)?
- 是否包含数字
词干特征
- …
做完特征工程之后,就可以得到特征向量,然后就可以喂给分类模型进行分类。
首先我们用一些比较简单的特征,并用随机森林模型来进行分类。
from sklearn.ensemble import RandomForestClassifier
def get_feature(word):# 返回一些简单的特征 是否为标题(首字母大写,其他字母小写),是否全小写,是否全大写,单词长度,是否为数字,是否为字母return np.array([word.istitle(), word.islower(), word.isupper(), len(word),word.isdigit(), word.isalpha()])words = [get_feature(w) for w in data["Word"].values.tolist()]
tags = data["Tag"].values.tolist()from sklearn.model_selection import cross_val_predict
from sklearn.metrics import classification_report
pred = cross_val_predict(RandomForestClassifier(n_estimators=20), X=words, y=tags, cv=5)
report = classification_report(y_pred=pred, y_true=tags)
print(report)

这里只是进行了简单的特征提取,只考虑了标题、小写、大写、数字等,可以看到结果还没有基准好。说明我们的特征提取的不够,下面我们进行更详细的特征提取。
from sklearn.preprocessing import LabelEncoderdef get_sentences(data):agg_func = lambda s: [(w, p, t) for w, p, t in zip(s["Word"].values.tolist(),s["POS"].values.tolist(),s["Tag"].values.tolist())]sentence_grouped = data.groupby("Sentence #").apply(agg_func)return [s for s in sentence_grouped] # 转换成句子
sentences = get_sentences(data)out = []
y = []
mv_tagger = MajorityVoting()
# LabelEncoder将标签转换为数值(索引)
tag_encoder = LabelEncoder()
pos_encoder = LabelEncoder()words = data["Word"].values.tolist()
pos = data["POS"].values.tolist()
tags = data["Tag"].values.tolist()mv_tagger.fit(words, tags)
tag_encoder.fit(tags)
pos_encoder.fit(pos)it = 0for sentence in sentences:for i in range(len(sentence)):w, p, t = sentence[i][0], sentence[i][1], sentence[i][2]if i < len(sentence)-1:# 如果不是最后一个单词,则可以用到下文的信息mem_tag_r = tag_encoder.transform(mv_tagger.predict([sentence[i+1][0]]))[0] #预测的标签true_pos_r = pos_encoder.transform([sentence[i+1][1]])[0] #实际的词性else:mem_tag_r = tag_encoder.transform(['O'])[0]true_pos_r = pos_encoder.transform(['.'])[0]if i > 0: # 如果不是第一个单词,则可以用到上文的信息mem_tag_l = tag_encoder.transform(mv_tagger.predict([sentence[i-1][0]]))[0]true_pos_l = pos_encoder.transform([sentence[i-1][1]])[0]else:mem_tag_l = tag_encoder.transform(['O'])[0]true_pos_l = pos_encoder.transform(['.'])[0]#print (mem_tag_r, true_pos_r, mem_tag_l, true_pos_l)out.append(np.array([w.istitle(), w.islower(), w.isupper(), len(w), w.isdigit(), w.isalpha(),tag_encoder.transform(mv_tagger.predict([sentence[i][0]])),pos_encoder.transform([p])[0], mem_tag_r, true_pos_r, mem_tag_l, true_pos_l]))y.append(t)it = it + 1if it % 1000 == 0 :print(it) #打印进行到哪了
这里不仅考虑到了每个单词的词性、标签,还考虑了上下文(左右单词)的信息。
LabelEncoder的用法见
然后输出测试结果。

from sklearn.model_selection import cross_val_predict
from sklearn.metrics import classification_report
pred = cross_val_predict(RandomForestClassifier(n_estimators=20), X=out, y=y, cv=5)
report = classification_report(y_pred=pred, y_true=y)
print(report)

如结果所示,现在准确率是97%,比基准好了3%。这是我们考虑了前后单词的结果,如果考虑前前、后后会不会更好呢,感兴趣的可以自己尝试一下。
以上就是命名实体识别的简单介绍,后面会推出更多内容。
参考
- 贪心学院课程