本文是中文信息处理课程的期末考核大作业,对于自然语言处理主流任务的调研报告
————————————————
版权声明:本文为CSDN博主「<Running Snail>」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_45884316/article/details/118684681
摘要
命名实体识别是自然语言处理中的热点研究方向之一, 目的是识别文本中的命名实体并将其归纳到相应的实体类型中。首先阐述了命名实体识别任务的定义、目标和意义; 然后介绍了命名实体识别研究的发展进程,从最初的规则和字典方法到传统的统计学习方法再到现在的深度学习方法,不断地将新技术应用到命名实体识别研究中以提高性能; 最后针对评判命名实体识别模型的好坏,总结了常用的若干数据集和常用工具,并给出了未来的研究建议 。
1. 引言
命名实体识别这个术语首次出现在MUC-6(Message Understanding Conferences),这个会议关注的主要问题是信息抽取(Information Extraction),第六届MUC除了信息抽取评测任务还开设了新评测任务即命名实体识别任务。除此之外,其他相关的评测会议包括CoNLL(Conference on Computational Natural Language Learning)、ACE(Automatic Content Extraction)和IEER(Information Extraction-Entity Recognition Evaluation)等。在MUC-6之前,大家主要是关注人名、地名和组织机构名这三类专业名词的识别。自MUC-6起,后面有很多研究对类别进行了更细致的划分,比如地名被进一步细化为城市、州和国家,也有人将人名进一步细分为政治家、艺人等小类。
此外,一些评测还扩大了专业名词的范围,比如CoNLL某年组织的评测中包含了产品名的识别。一些研究也涉及电影名、书名、项目名、研究领域名称、电子邮件地址、电话号码以及生物信息学领域的专有名词(如蛋白质、DNA、RNA等)。甚至有一些工作不限定“实体”的类型,而是将其当做开放域的命名实体识别和分类。
2. 研究背景
命名实体识别(Named Entity Recognition, NER)是NLP中一项非常基础的任务,是信息提取、问答系统、句法分析、机器翻译等众多NLP任务的重要基础工具。命名实体一般指的是文本中具有特定意义或者指代性强的实体,学术上通常包括实体类,时间类,数字类三大类和人名、地名、组织机构名、时间、日期、货币、百分比七小类。NER就是从非结构化的输入文本中抽取出上述实体,并且可以按照业务需求识别出更多类别的实体。
NER是一个具有挑战性的学习问题,在大多数语言和领域中,只有很少量的训练数据可用,同时对于可以作为名称的单词种类几乎没有限制,因此很难从这种小的数据样本中进行概括。其发展从早期基于词典和规则的方法,到传统机器学习的方法,到近年来基于深度学习的方法。
NER是NLP中一项基础性关键任务。从自然语言处理的流程来看,NER可以看作词法分析中未登录词识别的一种,是未登录词中数量最多、识别难度最大、对分词效果影响最大问题。同时NER也是关系抽取、事件抽取、知识图谱、机器翻译、问答系统等诸多NLP任务的基础。
3. 主要方法
命名实体识别从早期基于词典和规则的方法,到传统机器学习的方法, 后来采用基于深度学习的方法,一直到当下热门的注意力机制、图神经网络等研究方法, 命名实体识别技术路线随着时间在不断发展。

3.1 基于规则和字典的方法
基于规则的NER系统依赖于人工制定的规则。规则的设计一般基于句法、语法、词汇的模式以及特定领域的知识等。词典是由特征词构成的词典和外部词典共同组成,外部词典指已有的常识词典。 制定好规则和词典后,通常使用匹配的方式对文本进行处理以实现命名实体识别。
当字典大小有限时,基于规则的NER系统可以达到很好的效果。由于特定领域的规则以及不完全的字典,这种NER系统的特点是高精确率与低召回率,并且类似的系统难以迁移应用到别的领域中去:基于领域的规则往往不通用,对新的领域而言,需要重新制定规则且不同领域字典不同。所以这种基于规则的方法局限性非常明显,不仅需要消耗巨大的人力劳动,且不容易在其他实体类型或数据集扩展。
3.2基于传统机器学习的方法
在基于机器学习的方法中, 命名实体识别被当作是序列标注问题。与分类问题相比,序列标注问题中当前的预测标签不仅与当前的输入特征相关,还与之前的预测标签相关,即预测标签序列之间是有强相互依赖关系的。
采用的传统机器学习方法主要包括:
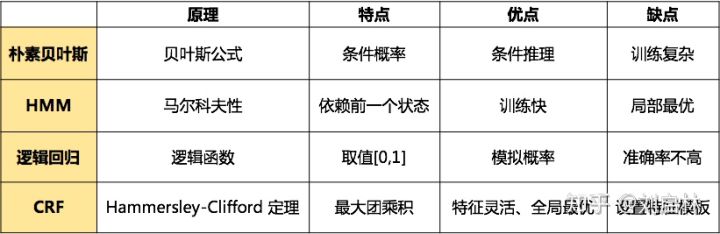
- 隐马尔可夫模型(Hidden Markov Model, HMM)
HMM对转移概率和表现概率直接建模,统计共现概率。更适用于一些对实时性有要求以及像信息检索这样需要处理大量文本的应用,如短文本命名实体识别。 - 最大熵(Maximum Entropy, ME) [14]
ME结构紧凑,具有较好的通用性, 其主要缺点是训练时间复杂性非常高,甚至导致训练代价难以承受,另外由于需要明确的归一化计算,导致开销比较大。 - 最大熵马尔可夫模型(Maximum Entropy Markov Model, MEMM) [15]
MEMM对转移概率和表现概率建立联合概率,统计条件概率,但由于只在局部做归一化容易陷入局部最优。 - 支持向量机(Support Vector Machine, SVM)
SVM在正确率上要比HMM高一些,但是HMM在训练和识别时的速度要快一些。 主要是由于在利用Viterbi算法求解命名实体类别序列的效率较高。 - 条件随机场( Conditional Random Fields, CRF) [16]等。
CRF模型统计全局概率,在归一化时考虑数据在全局的分布,而不是仅仅在局部进行归一化, 因此解决了MEMM中标记偏置的问题。 在传统机器学习中, CRF被看作是命名实体识别的主流模型, 优点在于在对一个位置进行标注的过程中CRF可以利用内部及上下文特征信息。 但同时存在收敛速度慢、训练时间长的问题。
3.3 基于深度学习的方法
近年来, 在基于神经网络的结构上加入注意力机制、图神经网络、迁移学习、远监督学习等热门研究技术也是目前的主流研究方向 。NER使用深度学习的原因主要是:1.NER适用于非线性转化。2.深度学习避免大量的人工特征的构建,节省了设计NER功能的大量精力。3.深度学习能通过梯度传播来训练,这样可以构建更复杂的网络。5. 端到端的训练方式。
3.3.1 BiLSTM-CRF
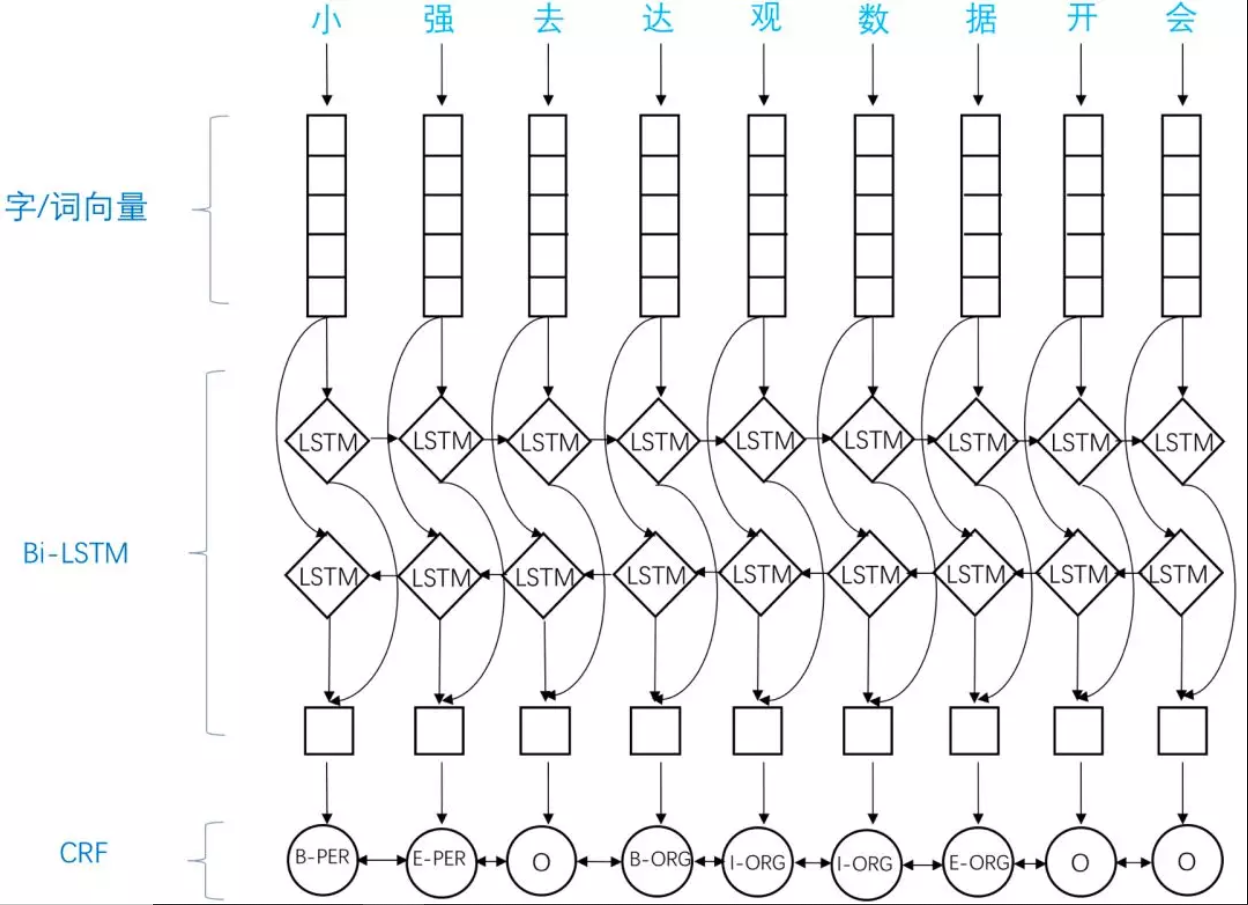
BiLSTM-CRF直观显示了模型结构与优势,其中BiLSTM通过前向/后向传递的方式学习序列中某字符依赖的过去和将来的信息,CRF则考虑到标注序列的合理性。模型主要由Embedding层(主要有词向量,字向量以及一些额外特征),双向LSTM层,以及最后的CRF层构成。在特征方面,该模型继承了深度学习方法的优势,无需特征工程,使用词向量以及字符向量就可以达到很好的效果,如果有高质量的词典特征,能够进一步获得提高。
引入双向LSTM层作为特征提取工具,LSTM拥有较强的长序列特征提取能力。双向LSTM,在提取某个时刻特征时,能够利用该时刻之后的序列的信息,无疑能够提高模型的特征提取能力。引入CRF作为解码工具。中文输入经过双向LSTM层的编码之后,需要能够利用编码到的丰富的信息,将其转化成NER标注序列。通过观察序列,预测隐藏状态序列,CRF无疑是首选。
这些优势使得论文模型在当时取得SOTA结果,已经达到或者超过了基于丰富特征的CRF模型,成为目前基于深度学习的NER方法中的最主流模型。
3.3.2 IDCNN-CRF
论文Fast and Accurate Entity Recognition with Iterated Dilated Convolutions提出在NER任务中,引入膨胀卷积,一方面可以引入CNN并行计算的优势,提高训练和预测时的速度;另一方面,可以减轻CNN在长序列输入上特征提取能力弱的劣势。具体使用时,dilated width会随着层数的增加而指数增加。这样随着层数的增加,参数数量是线性增加的,而感受野却是指数增加的,这样就可以很快覆盖到全部的输入数据。IDCNN对输入句子的每一个字生成一个logits,这里就和BiLSTM模型输出logits之后完全一样,再放入CRF Layer解码出标注结果。
3.3.3 CAN-NER
Convolutional Attention Network for Chinese Named Entity Recognition(NAACL 2019)提出了用基于注意力机制的卷积神经网络架构。

采用一种卷积注意网络CAN,它由具有局部attention的基于字符的CNN和具有全局attention的GRU组成,用于获取从局部的相邻字符和全局的句子上下文中信息。首先模型输入的是字符,卷积注意力层用来编码输入的字符序列并隐式地对局部语义相关的字符进行分组。对输入进行向量嵌入,包含字向量、分词向量和位置向量,得到输入向量后,采用局部 local attention来捕捉窗口范围内中心词和周围词的依赖,局部 attention 的输出被送到 CNN 中,最后采用加和池化方案。得到局部特征后,进入到BiGRU-CRF 中,而后采用全局的 attention来进一步捕捉句子级别的全局信息。后面接 CRF,得到分类结果。self-attention 可以捕捉广义的上下文信息,减少无用中间词的干扰。
3.2.4 Lattice LSTM(针对中文的NER)
中文的NER与英文不太一样,中文NER问题很大程度上取決于分词的效果,比如实体边界和单词的边界在中文NER可题中经常是一样的。所以在中文NER问题中,有时通常先对文本进行分词然后再预测序列中单词的类别。这样一来会导致一个问题,即在分词中造成的错误会影响到NER的结果。基于字向量的模型能够避免上述问题,但因为单纯采用字向量,导致拆开了很多并不应该拆开的词语,从而丢失了它们本身的内在信息。

《Chinese NER Using Lattice LSTM》提出一种用于中文NER的LSTM的格子模型,与基于字符的方法相比,该模型显性地利用词和词序信息;与基于词的方法相比,完整的嵌入词语信息因此 lattice LSTM 不会出现分词错误。门控循环单元使得模型能够从句子中选择最相关的字符和词,以生成更好的 NER 结果。但是,此模型对于一些新的词语效果不理想。
3.2.5 引入BERT及attention
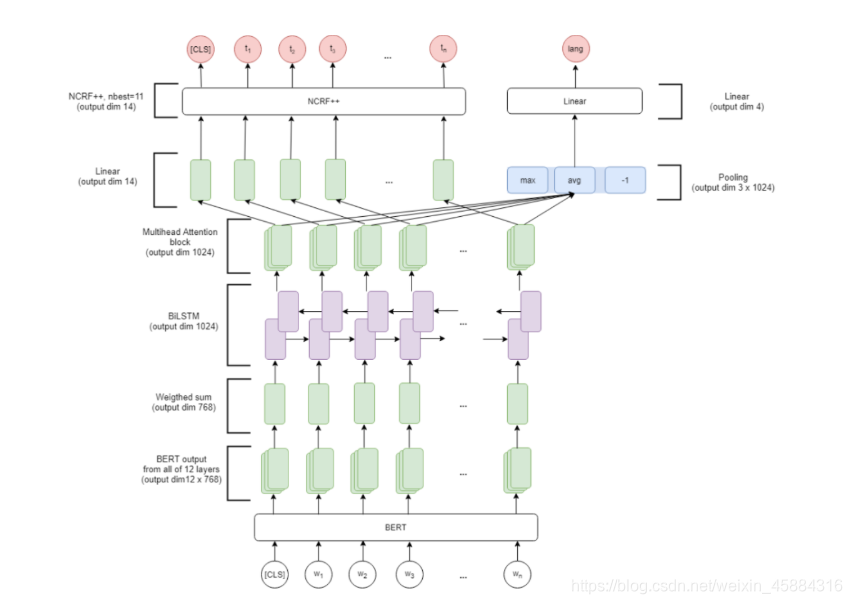
论文《Multilingual Named Entity Recognition Using Pretrained Embeddings, Attention Mechanism and NCRF》在NCRF和BiLSTM中间加入了一层Multihead Attention,并用BERT来获取上下文词表示,然后设计了一个多任务结构来学习多语言NER。
4.NER主要数据集
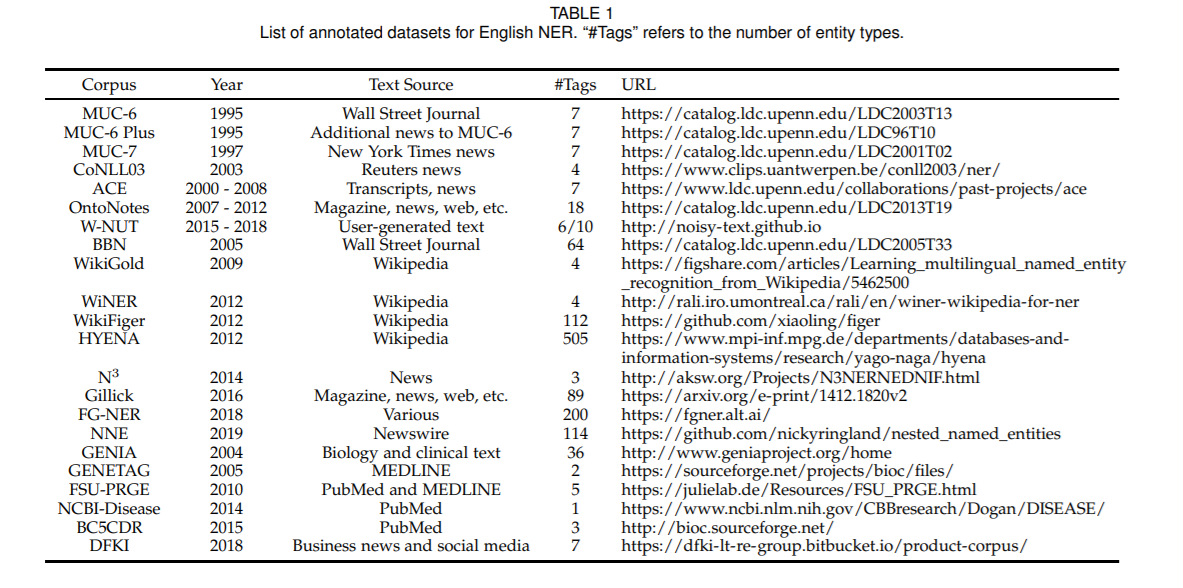
英文数据集
①CoNLL 2003数据集包括1 393篇英语新闻文章和909篇德语新闻文章,英语语料库是免费的,德国语料库需要收费。英语语料取自路透社收集的共享任务数据集。 数据集中标注了4种实体类型:PER,LOC,ORG MISC。
② CoNLL 2002数据集是从西班牙EFE新闻机构收集的西班牙共享任务数据集。数据集标注了4种实
体类型: PER,LOC,ORG,MISC。
③ ACE 2004 多语种训练语料库版权属于语言数据联盟(Linguistic Data Consortium, LDC), ACE 2004多语言培训语料库包含用于 2004 年自动内容提取(ACE)技术评估的全套英语、 阿拉伯语和中文培训数据。语言集由为实体和关系标注的各种类型的数据组成。
④ ACE 2005 多语种训练语料库版权属于 LDC, 包含完整的英语、阿拉伯语和汉语训练数据, 数据来源包括:微博、广播新闻、新闻组、广播对话等, 可以用来做实体、 关系、 事件抽取等任务。
⑤ OntoNotes 5.0 数据集版权属于 LDC, 由 1745K 英语、 900K 中文和 300K 阿拉伯语文本数据组成, OntoNotes 5.0 的数据来源也多种多样, 来自电话对话、新闻通讯社、广播新闻、广播对话和博客等。实体被标注为 PERSON,ORGANIZATION,LOCATION 等 18 个类型。
⑥ MUC 7 数据集是发布的可以用于命名实体识别任务, 版权属于 LDC,下载需要支付一定费用。数据取自北美新闻文本语料库的新闻标题, 其中包含 190K 训练集、 64K 测试集。
⑦ Twitter数据集是由Zhang等提供,数据收集于Twitter,训练集包含了4 000 推特文章, 3257条推特用户测试。该数据集不仅包含文本信息还包含了图片信息
其它数据集
中文数据集
- CCKS2017开放的中文的电子病例测评相关的数据。
评测任务一:https://biendata.com/competition/CCKS2017_1/
评测任务二:https://biendata.com/competition/CCKS2017_2/ - CCKS2018开放的音乐领域的实体识别任务。
评测任务:https://biendata.com/competition/CCKS2018_2/ - (CoNLL 2002)Annotated Corpus for Named Entity Recognition。
地址:https://www.kaggle.com/abhinavwalia95/entity-annotated-corpus - NLPCC2018开放的任务型对话系统中的口语理解评测。
地址:http://tcci.ccf.org.cn/conference/2018/taskdata.php - 一家公司提供的数据集,包含人名、地名、机构名、专有名词。
下载地址:https://bosonnlp.com/dev/resource
5.NER工具
Stanford NER
斯坦福大学开发的基于条件随机场的命名实体识别系统,该系统参数是基于CoNLL、MUC-6、MUC-7和ACE命名实体语料训练出来的。
地址:https://nlp.stanford.edu/software/CRF-NER.shtml
python实现的Github地址:https://github.com/Lynten/stanford-corenlp
# 安装:pip install stanfordcorenlp
# 国内源安装:pip install stanfordcorenlp -i https://pypi.tuna.tsinghua.edu.cn/simple
# 使用stanfordcorenlp进行命名实体类识别
# 先下载模型,下载地址:https://nlp.stanford.edu/software/corenlp-backup-download.html
# 对中文进行实体识别
from stanfordcorenlp import StanfordCoreNLP
zh_model = StanfordCoreNLP(r'stanford-corenlp-full-2018-02-27', lang='zh')
s_zh = '我爱自然语言处理技术!'
ner_zh = zh_model.ner(s_zh)
s_zh1 = '我爱北京天安门!'
ner_zh1 = zh_model.ner(s_zh1)
print(ner_zh)
print(ner_zh1)[('我爱', 'O'), ('自然', 'O'), ('语言', 'O'), ('处理', 'O'), ('技术', 'O'), ('!', 'O')]
[('我爱', 'O'), ('北京', 'STATE_OR_PROVINCE'), ('天安门', 'FACILITY'), ('!', 'O')]# 对英文进行实体识别
eng_model = StanfordCoreNLP(r'stanford-corenlp-full-2018-02-27')
s_eng = 'I love natural language processing technology!'
ner_eng = eng_model.ner(s_eng)
s_eng1 = 'I love Beijing Tiananmen!'
ner_eng1 = eng_model.ner(s_eng1)
print(ner_eng)
print(ner_eng1)[('I', 'O'), ('love', 'O'), ('natural', 'O'), ('language', 'O'), ('processing', 'O'), ('technology', 'O'), ('!', 'O')]
[('I', 'O'), ('love', 'O'), ('Beijing', 'CITY'), ('Tiananmen', 'LOCATION'), ('!', 'O')]
MALLET
麻省大学开发的一个统计自然语言处理的开源包,其序列标注工具的应用中能够实现命名实体识别。 官方地址:http://mallet.cs.umass.edu/
Hanlp
HanLP是一系列模型与算法组成的NLP工具包,由大快搜索主导并完全开源,目标是普及自然语言处理在生产环境中的应用。支持命名实体识别。 Github地址:https://github.com/hankcs/pyhanlp
官网:http://hanlp.linrunsoft.com/
# 安装:pip install pyhanlp
# 国内源安装:pip install pyhanlp -i https://pypi.tuna.tsinghua.edu.cn/simple
# 通过crf算法识别实体
from pyhanlp import *
# 音译人名示例
CRFnewSegment = HanLP.newSegment("crf")
term_list = CRFnewSegment.seg("我爱北京天安门!")
print(term_list)[我/r, 爱/v, 北京/ns, 天安门/ns, !/w]
NLTK
NLTK是一个高效的Python构建的平台,用来处理人类自然语言数据。
Github地址:https://github.com/nltk/nltk 官网:http://www.nltk.org/
# 安装:pip install nltk
# 国内源安装:pip install nltk -i https://pypi.tuna.tsinghua.edu.cn/simple
import nltk
s = 'I love natural language processing technology!'
s_token = nltk.word_tokenize(s)
s_tagged = nltk.pos_tag(s_token)
s_ner = nltk.chunk.ne_chunk(s_tagged)
print(s_ner)
SpaCy
工业级的自然语言处理工具,遗憾的是不支持中文。 Gihub地址: https://github.com/explosion/spaCy 官网:https://spacy.io/
# 安装:pip install spaCy
# 国内源安装:pip install spaCy -i https://pypi.tuna.tsinghua.edu.cn/simple
import spacy
eng_model = spacy.load('en')
s = 'I want to Beijing learning natural language processing technology!'
# 命名实体识别
s_ent = eng_model(s)
for ent in s_ent.ents:print(ent, ent.label_, ent.label)Beijing GPE 382
Crfsuite
可以载入自己的数据集去训练CRF实体识别模型。
文档地址:
https://sklearn-crfsuite.readthedocs.io/en/latest/?badge=latest
代码已上传:https://github.com/yuquanle/StudyForNLP/blob/master/NLPbasic/NER.ipynb
6. 总结
命名实体识别是自然语言处理应用中的重要步骤, 它不仅检测出实体边界,还检测出命名实体的类型,是文本意义理解的基础。 本文阐述了命名实体识别的研究进展,从早期基于规则和词典的方法,到传统机器学习的方法,到近年来基于深度学习的方法, 神经网络与 CRF 模型相结合的 NN-CRF 模型依旧是目前命名实体识别的主流模型。 未来的研究中,数据标注和非正式文本(评论、论坛发言等未出现过的实体)仍会是两个挑战。迁移学习、对抗学习、远监督学习方法以及图神经网络、注意力机制、NER模型压缩、多类别实体、嵌套实体、实体识别和实体链接联合任务等都会是NER未来研究的重点。
参考文献
[1] Zhang Y , Yang J . Chinese NER Using Lattice LSTM[J]. 2018.
[2] Strubell E , Verga P , Belanger D , et al. Fast and Accurate Entity Recognition with Iterated Dilated Convolutions[J]. 2017.
[3] Zhu Y , Wang G , Karlsson B F . CAN-NER: Convolutional Attention Network forChinese Named Entity Recognition[J]. 2019.
[4] Emelyanov A A , Artemova E . Multilingual Named Entity Recognition Using Pretrained Embeddings, Attention Mechanism and NCRF[J]. 2019.
[5] Li J , Sun A , Han J , et al. A Survey on Deep Learning for Named Entity Recognition[J]. IEEE Transactions on Knowledge and Data Engineering, 2020, PP(99):1-1.
[6] Ratnaparkhi A . A Maximum Entropy Model for Part-Of-Speech Tagging. 2002.
[7] MCCALLUM A, FREITAG D, PEREIRA F C N. Maximum Entropy Markov Models for Information Extraction andSegmentation[C]//Icml, 2000, 17: 591-598
[8] Lafferty J , Mccallum A , Pereira F . Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data[C]// Proc. 18th International Conf. on Machine Learning. 2001.
[9] 陈曙东, 欧阳小叶. 命名实体识别技术综述[J]. 无线电通信技术, 2020, 046(003):251-260.
[10] 刘宇鹏, 栗冬冬. 基于BLSTM-CNN-CRF的中文命名实体识别方法[J]. 哈尔滨理工大学学报, 2020, v.25(01):119-124.
[11] Huang Z , Wei X , Kai Y . Bidirectional LSTM-CRF Models for Sequence Tagging[J]. Computer Science, 2015.
[12] Xiang R , He W , Meng Q , et al. AFET: Automatic Fine-Grained Entity Typing by Hierarchical Partial-Label Embedding[C]// Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016.
[13] COLLOBERT R, WESTON J, BOTTOU L, et al. Natural Language Processing (almost) from Scratch[J]. Journal of MachineLearning Research, 2011, 12(Aug): 2493-2537