命名实体识别
- 什么是命名实体识别?
- NER 研究的命名实体
- NER研究目前所遇到的问题
- 命名实体识别的主要方法:
- 基于条件随机场的命名实体识别
- 常用的NER模型
- 1、Spacy NER 模型
- 2、斯坦福命名实体识别器
- 中文人名识别
- 中文姓名的构成规律
- 姓名的上下文环境分析
- Hanlp进行人名识别
- demo
- 地名识别
- 中文地名构成
- 基于 Hanlp 进行地名识别
- demo
- 参考书籍
什么是命名实体识别?
与自动分词、词性标注一样,命名实体识别也是自然语言处理的一个基础任务,是信息抽取、信息检索、机器翻译、问答系统等多种自然语言处理技术必不可少的组成部分。其目的是识别语料中人名、地名、组织机构名等命名实体。由于这些命名实体数量不断增加,通常不可能在词典中穷尽列出,且其构成方法具有各自的规律性,因此,通常把对这些词的识别在词汇形态处理(如汉语切分)任务中独立处理,称为命名实体识别( Named Entities Recognition,NER )。
NER 研究的命名实体
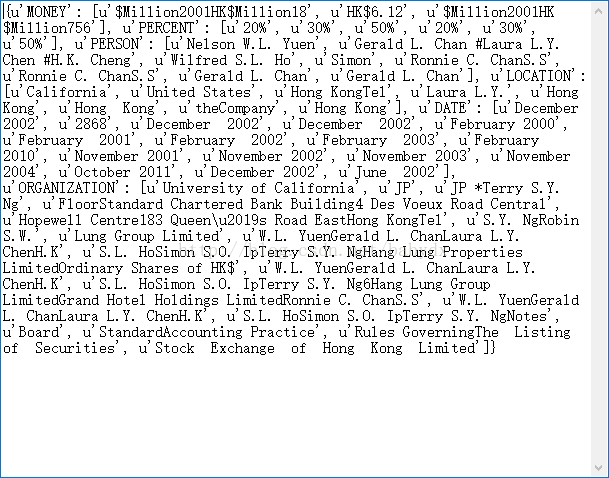
NER 研究的命名实体一般分为3大类(实体类、时间类和数字类)和7小类(人名、地名、组织机构名、时间、日期、货币和百分比)。
NER研究目前所遇到的问题
命名实体识别当前并不是一个大热的研究课题,因为学术界部分认为这是一个已经解决了的问题,但是也有学者认为这个问题还没有得到很好地解决,原因主要有:
- 只是在有限的文本类型(主要是新闻语料)和实体类别(主要是人名、地名)中取得一定效果;
- 评测语料较小,易产生过拟合;
- NER 更加侧重于召回率,但在信息检索领域,高准确率更重要;
- 通用的识别多种类型的命名实体的系统性很差。
中文的命名实体识别与英文的相比,挑战更大,目前常遇到的问题有:
- 各类命名实体数量太多;
- 命名实体的构成规律复杂;
- 嵌套情况复杂;
- 长度不确定。
命名实体识别的主要方法:
命名实体识别目前主要有三类方法:
- 基于规则的命名实体识别:规则加词典是早期命名实体识别中最行之有效的方式。其依赖手工规则的系统,结合命名实体库,对每条规则进行权重赋值,然后通过实体与规则的相符情况来进行类型判断。当提取的规则能够较好反映语言现象时,该方法能明显优于其他方法。
- 基于统计的命名实体识别:与分词类似,目前主流的基于统计的命名实体识别方法有:隐马尔可夫模型、最大熵模型、条件随机场等。其主要思想是基于人工标注的语料,将命名实体识别任务作为序列标注问题来解决。基于统计的方法对语料库的依赖比较大,而可以用来建设和评估命名实体识别系统的大规模通用语料库又比较少,这是该方法的一大制约。
- 混合方法:自然语言处理并不完全是一个随机过程,单独使用基于统计的方法使状态搜索空间非常庞大,必须借助规则知识提前进行过滤修剪处理。目前几乎没有单纯使用统计模型而不使用规则知识的命名实体识别系统,在很多情况下是使用混合方法,结合规则和统计方法。
基于条件随机场的命名实体识别
条件随机场是在给定观察的标记序列下,计算整个标记序列的联合概率,而 HMM 则是在给定当前状态下,定义下一个状态的分布;条件随机场的具体定义为:
设X=(X 1 ,X 2 ,X 3 ,…,X n )和Y=(Y 1 ,Y 2 ,Y 3 ,…Y m )是联合随机变量,若随机变量 Y 构成一个无向图G=(V,E)表示的马尔可夫模型,则其条件概率分布P(Y∣X)称为条件随机场(简称 CRF),P(Yv∣X,Y w ,w =v)=P(Y v∣X,Y w ,w−v)其中w−v表示图G=(V,E)中与结点 v 有边连接的所有节点,w 不等于 v 表示结点 v 以外的所有结点。
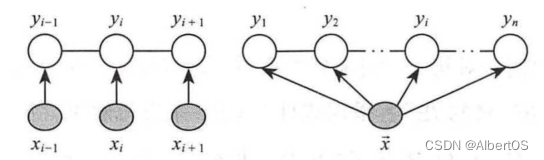
若在给定随机变量序列 X 的条件下,随机变量序列 Y 的条件概率分布P(Y∣X)构成条件随机场,且满足马尔可夫性,此时,称P(Y∣X)为线性链的条件随机场,简称 CRF,线性链条件随机场的结构图如图1所示。
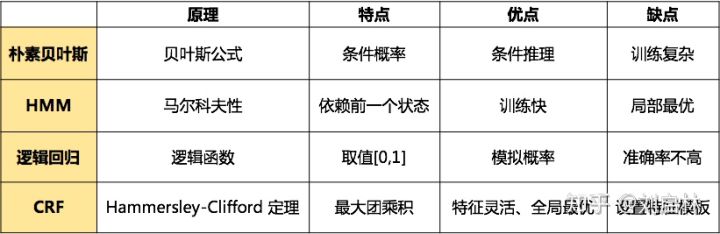
HMM 与 CRF 的联系区别如下表所示:
| HMM | CRF | |
|---|---|---|
| 概率图类型 | 概率有向图 | 概率无向图 |
| 模型类别 | 生成模型 | 判别模型 |
| 求解过程 | 可能是局部最优 | 可以全局最优 |
| 处理方面 | 每个状态依赖上一个状态 | 依赖于当前状态的周围节点状态 |
常用的NER模型
1、Spacy NER 模型
作为一个免费的开放源码库,Spacy 使 Python 中的高级自然语言处理(NLP)变得更加简单方便。
Spacy 为 python 中的命名实体识别提供了一个非常有效的统计系统,它可以将标签分配给连续的令牌组。它提供了一个默认模型,可以识别各种命名或数字实体,其中包括公司名称、位置、组织、产品名称等。除了这些默认实体之外,Spacy 还可以通过训练模型以用新的被训练示例更新,将使模型可以任意类添新的命名实体,进行识别。
2、斯坦福命名实体识别器
Stanford NER 是一个命名实体 Recognizer,用 Java 实现。它提供了一个默认的训练模型,主要用于识别组织、人员和位置等实体。除此之外,还提供针对不同语言和环境训练的各种模型。
斯坦福 NER 因为线性链条件随机场(CRF)序列模型已经在软件中实现,所以也被称为 CRF(条件随机场)分类器。我们可以使用自己的标注数据集为各种应用程序训练自己的自定义模型。
中文人名识别
中文姓名的构成规律
中文姓名一般由二字或三字组成,第一字为姓氏字(复姓为前两字),其后的一到两个汉字为名用字。统计表明,中文姓名在用字上也有一定规律:一方面某些字频频出现在姓名中,如在姓氏用字中,虽然姓氏辞典中列举了几千个姓氏字,但目前实际使用的不过几百个,而张、王、李、赵、刘5个姓竟占了32%;另一方面,某些字又从不被用作姓名用字,如最、仅、 紧、以、且等字。
根据这一特性,首先从一个含有1万多个人名的数据库中抽取303个姓用字和1047个名用字,形成系统的知识源;然后根据姓名的构成原则制定了一组姓名构成规则集,其中的规则以姓氏字驱动。由于中文姓名的构成是严格遵守构成规则的,因而本文将姓名构成规则定义为一组必须匹配的严格规则。

姓名的上下文环境分析
中文姓名在文本中不是孤立存在的,其依存的上下文信息具有一定的特点:
-
前置信息:姓名的前端多冠有对人的职业、职务及与说话人的关系的称谓,如“这是上海市副市长刘振元日前在与上海旅游记者协会座谈时介绍的。”、“我和妻子秦润英都是双目失明的盲人。”等。在上述句子中的“市长”和“妻子”就是人名“刘振元”和“秦润英”的前置提示信息。
-
后置信息:姓名的后端多随有对此人的职业、职务及与说话人的关系的称谓,如“我国著名学者彭明教授访问前苏联时将书稿复印件全文带回。”,这里的“教授”就成为人名“彭明”的后置提示信息。
-
提示动词:某些动词多随在姓名和人称代词后,如“说、指出、告诉、通知…”,可充分利用这些词的提示作用。
Hanlp进行人名识别
HanLP 是由一系列模型与算法组成的工具包,目标是普及自然语言处理在生产环境中的应用。HanLP 具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点;
提供词法分析(中文分词、词性标注、命名实体识别)、句法分析、文本分类和情感分析等功能。
HanLP 已经被广泛用于 Lucene、Solr、ElasticSearch、Hadoop、Android、Resin 等平台,有大量开源作者开发各种插件与拓展,并且被包装或移植到 Python、C#、R、JavaScript 等语言上去。 基于深度学习的 HanLP2.0 已于2020年初发布,面向下一个十年的前沿 NLP 技术,与 1.x 相辅相成,平行发展。
在 python 环境下使用 Hanlp 可以通过安装 pyhanlp 来导入:
pip install pyhanlp # 安装 pyhanlp 库from pyhanlp import HanLP # 使用前导入 HanLP工具
在 Hanlp 工具中,主要使用的是 HMM 算法对人名进行识别,在对人名进行识别时,我们可以通过以下方式:
text =input()segment = HanLP.newSegment().enableNameRecognize(True); # 构建人名识别器result = segment.seg(text) # 对text文本进行人名识别print(result) # 输出结果
比如,我们输入的文本为张三在吃苹果,输出的结果则为 [张三/nr, 在/p, 吃苹果/nz],人名识别的结果中,包含着各个词的识别结果,我们可以根据各个词的识别结果得知哪些词属于人名。常见标注的具体意义如下:
| 代码 | 意义 |
|---|---|
| nr | 人名 |
| n | 名词 |
| v | 动词 |
| p | 介词 |
| g | 语素词 |
| h | 前接部分 |
demo
from pyhanlp import HanLP
text =input()
# 任务:完成对 text 文本的人名识别并输出结果
segment = HanLP.newSegment().enableNameRecognize(True); # 构建人名识别器
result = segment.seg(text) # 对text文本进行人名识别
print(result) # 输出结果测试输入
张三今天没来上课
实际输出
[张三/nr, 今天/t, 没来/v, 上课/vi]
地名识别
中文地名构成
中文地名是指由汉字表示的中国地名及外国地名,从信息处理的角度出发,我们把中文地名定义为基本地名和复合地名构成的二级体系。基本地名是地名的最小成词单位,对应于人脑中存储地名的最小单位:它是人们对具有特定方位、地域范围的地理实体赋予的专有名称。作为地名的原子类型,基本地名满足指称性、非类指性(专门性)、词汇性、开放性等命名实体特征并具有指位性的功能特征。
典型的基本地名由“命名成分+通名”构成,命名成分是所指的标志符,不可缺省,如“江苏省”的“江苏”,“佛罗里达州”的“佛罗里达”;通名标识了所指单位的大小级别或类别,当命名成分已另有所指或为单字时常不可缺省,如“江苏路”中的“路”,“蓟县”的“县”。
基本地名通过合理组合形成复合地名。这里“合理”的意思是组合后形成的新地名有且只有一个所指,如“江苏省南京市”。复合地名是一个意义单位,相邻基本地名是否存在单向的领属关系是能否组合为一个复合地名的关键。因此,让计算机正确地识别、分析和理解复合地名有赖于基本地名的识别和基本地名之间关系的识别。

基于 Hanlp 进行地名识别
在 Hanlp 开发工具中,对地名识别主要采取的是 HMM 算法,在实际开发过程中,我们可以通过以下方式进行地名识别:
text =input()segment = HanLP.newSegment().enablePlaceRecognize(True); # 构建地名识别器result = segment.seg(text) # 对text文本进行地名识别
比如,我们输入文本中国是个好地方,可以得到地名识别的结果为[中国/ns, 是/vshi, 个/q, 好/a, 地方/n],与人名识别类似,地名识别器根据对句子的理解为各个词都做了标注,其中标注为 ns 的词即为地名。
在 Hanlp 中,目前标准分词器都默认关闭了地名识别,用户需要手动开启;这是因为消耗性能,其实多数地名都收录在核心词典和用户自定义词典中;在生产环境中,能靠词典解决的问题就靠词典解决,这是最高效稳定的方法;对命名实体识别要求较高的用户可以使用感知机词法分析器。
demo
from pyhanlp import HanLP
text =input()
# 任务:完成对 text 文本的地名识别并输出结果
segment = HanLP.newSegment().enablePlaceRecognize(True); # 构建地名识别器
result = segment.seg(text) # 对text文本进行地名识别
print(result)测试输入
中国是个好地方
实际输出
[中国/ns, 是/vshi, 个/q, 好/a, 地方/n]
注:ns即是识别为地名的名词
参考书籍
【1】自然语言处理
【2】命名实体识别(NER)综述