转载https://blog.csdn.net/fendouaini/article/details/81137424
link
作者:Walker
目录
一.什么是命名实体识别
二.基于NLTK的命名实体识别
三.基于Stanford的NER
四.总结
一 、什么是命名实体识别?
命名实体识别(Named Entity Recognition,简称NER),又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。通常包括两部分:(1)实体边界识别;(2) 确定实体类别(人名、地名、机构名或其他)。
命名实体识别通常是知识挖掘、信息抽取的第一步,被广泛应用在自然语言处理领域。接下来,我们将介绍常用的两种命名实体识别的方法。
二 、基于NLTK的命名实体识别:
NLTK:由宾夕法尼亚大学计算机和信息科学使用python语言实现的一种自然语言工具包,其收集的大量公开数据集、模型上提供了全面、易用的接口,涵盖了分词、词性标注(Part-Of-Speech tag, POS-tag)、命名实体识别(Named Entity Recognition, NER)、句法分析(Syntactic Parse)等各项NLP领域的功能。
使用前需要先下载NLTK,下载地址为:http://pypi.python.org/pypi/nltk,安装完成后,在python环境下输入import nltk测试是否安装成功,然后输入nltk.download()下载nltk所需要的数据包,完成安装。
Python代码实现(注意文件的编码格式为utf-8无BOM格式):
-- coding: utf-8 --
import sys
reload(sys)
sys.setdefaultencoding(‘utf8’) #让cmd识别正确的编码
import nltk
newfile = open(‘news.txt’)
text = newfile.read() #读取文件
tokens = nltk.word_tokenize(text) #分词
tagged = nltk.pos_tag(tokens) #词性标注
entities = nltk.chunk.ne_chunk(tagged) #命名实体识别
a1=str(entities) #将文件转换为字符串
file_object = open(‘out.txt’, ‘w’)
file_object.write(a1) #写入到文件中
file_object.close( )
print entities
具体的方法可参考NLTK官网介绍:http://www.nltk.org/,输出的结果为:
>>> entities = nltk.chunk.ne_chunk(tagged)
>>> entities
Tree(‘S’, [(‘At’, ‘IN’), (‘eight’, ‘CD’), (“o’clock”, ‘JJ’),
(‘on’, ‘IN’), (‘Thursday’, ‘NNP’), (‘morning’, ‘NN’),
Tree(‘PERSON’, [(‘Arthur’, ‘NNP’)]),
(‘did’, ‘VBD’), (“n’t”, ‘RB’), (‘feel’, ‘VB’),
(‘very’, ‘RB’), (‘good’, ‘JJ’), (‘.’, ‘.’)])
当然为了方便查看,我们可以以树结构的形式把结果绘制出来:
>>> from nltk.corpus import treebank
>>> t = treebank.parsed_sents(‘wsj_0001.mrg’)[0]
>>> t.draw()
三 、基于Stanford的NER:
Stanford Named Entity Recognizer (NER)是斯坦福大学自然语言研究小组发布的成果之一,主页是:http://nlp.stanford.edu/software/CRF-NER.shtml。Stanford NER 是一个Java实现的命名实体识别(以下简称NER))程序。NER将文本中的实体按类标记出来,例如人名,公司名,地区,基因和蛋白质的名字等。
NER基于一个训练而得的Model(模型可识别出 Time, Location, Organization, Person, Money, Percent, Date)七类属性,其用于训练的数据即大量人工标记好的文本,理论上用于训练的数据量越大,NER的识别效果就越好。
因为原始的NER是基于java实现的,所以在使用Python编程之前,要确保自己电脑上已经安装了jar1.8的环境(否则会报关于Socket的错误)。
然后我们使用Pyner使用python语言实现命名实体识别。下载地址为:https://github.com/dat/pyner
安装Pyner:解压下载的Pyner,命令行中将工作目录切换到Pyner文件夹下, 输入命令 :python setup.py install 完成安装.
接下来,还需要下载StanfordNER工具包,下载地址为:http://nlp.stanford.edu/software/stanford-ner-2014-01-04.zip,然后在解压后的目录打开cmd命令窗体,执行,java -mx1000m -cp stanford-ner.jar edu.stanford.nlp.ie.NERServer -loadClassifier classifiers/english.muc.7class.distsim.crf.ser.gz -port 8080 -outputFormat inlineXML,直到结果为:Loading classifier from classifiers/english.muc.7class.distsim.crf.ser.gz … done [1.2 sec].
以上操作是因为斯坦福的命名实体识别是基于java的socket写的,所以必要保证有一个窗题与我们执行的命令通信。关于java的socket编程,可以参考以下文章:http://www.cnblogs.com/rond/p/3565113.html
最后,我们终于可以使用python编程实现NER了:
import ner
import sys
import nltk
reload(sys)
sys.setdefaultencoding(‘utf8’)
newfile = open(‘news.txt’)
text = newfile.read()
tagger = ner.SocketNER(host=’localhost’, port=8080)#socket编程
result=tagger.get_entities(text) #stanford实现NER
a1=str(result)
file_object = open(‘outfile.txt’, ‘w’)
file_object.write(a1)
file_object.close( )
print result
以上是我对文本文件进行的测试,官网的案例https://github.com/dat/pyner运行结果为:
>>> import ner
>>> tagger = ner.SocketNER(host=’localhost’, port=8080)
>>> tagger.get_entities(“University of California is located in California, United States”)
{‘LOCATION’: [‘California’, ‘United States’],
‘ORGANIZATION’: [‘University of California’]}
四 、两种方法的比较:
我拿同一个文本文件用两种方法进行命名实体识别,结果如下:

图1 NLTK运行结果
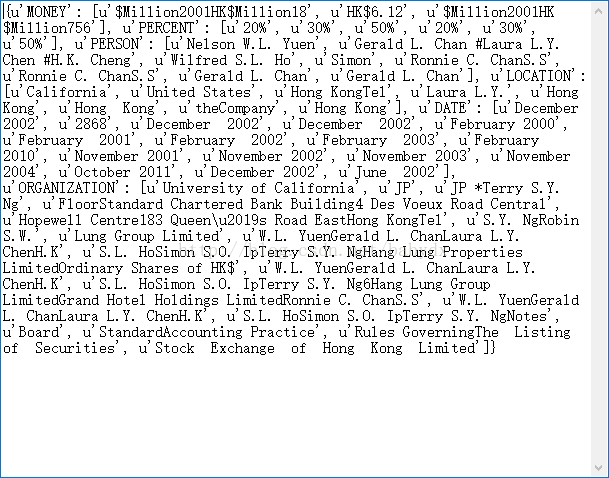
图2 Stanford方式运行结果
比较两种方式,我们可以发现,NLTK下的命名实体识别更加倾向于分词和词性标准,虽然它也会将组织名,人名,地名等标注出来,但由于它把文件中的谓语,宾语等成分也标注了出来,造成了输出文本的冗余性,不利于读者很好的识别命名实体,需要我们对文本做进一步处理。NLTK下的命名实体识别的有点时,可以使用NLTK下的treebank包将文本绘制为树形,使结果更加清晰易读。相较而言,我更加倾向于Stanford的命名实体识别,它可以把Time, Location, Organization, Person, Money, Percent, Date七类实体很清晰的标注出来,而没有多余的词性。但由于NER是基于java开发的,所以在用python实现时可能由于jar包或是路径问题出现很多bug。
以上就是关于NLTK和stanford对英文文本的命名实体识别,关于自然语言处理中文文件,我们可以考虑jieba分词:https://www.oschina.net/p/jieba。
【总结】:命名实体识别是构建知识图谱、进行自然语言处理问题的第一步,本文总结了现有的处理命名实体识别问题的两种方法,你掌握了吗?