文章目录
- 1 简介
- 2 NER标注语料库
- 3 NER工具库
- 4 序列标注标签方案
- 5 四类NER方法(规则-无监督学习-机器学习-深度学习)
- 5.1 基于规则的NER
- 5.2 基于无监督学习方法
- 5.2 基于机器学习(含特征的有监督学习)
- 5.3 基于深度学习方法
- 1、输入层
- 2、编码层
- 3、解码层
- 6 其他
- 6.1 实体识别任务中的常见问题及对策
- 6.2 各类研究方向的NER方法
- 6.3 NER任务的挑战与机遇
- Reference
1 简介
命名实体识别(Named Entity Recongnition,NER)是自然语言处理中的一个基础任务,也是知识图谱构建的关键步骤。一句话就是,NER从自由文本里面识别出预定义的文本片段。
在2005年之前,实体识别任务数据集主要是对新闻做的标注,实体类别数量较少,如实体、时间、数字三大类,人名、机构名、地名、时间、日期、货币和百分比7小类。现在NER任务已经深入到各个垂直领域,比如医疗,金融,法律等等。(通用类实体和特定领域类实体)
2 NER标注语料库
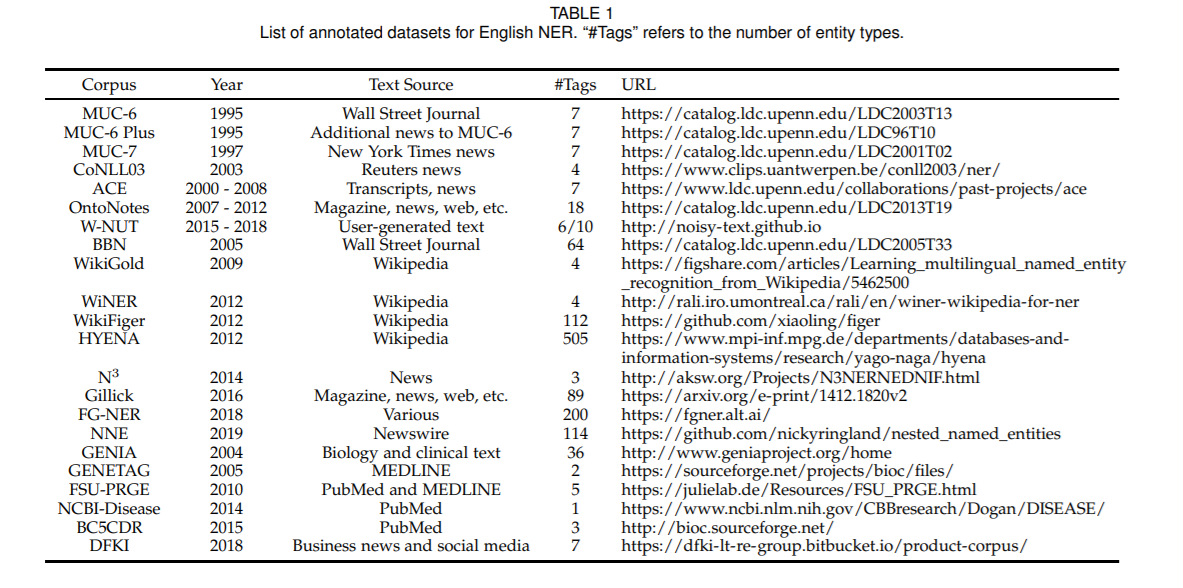
对现有公开评测任务使用的NER语料库进行了汇总,包括链接地址、类别个数以及语料类型。如下图。

3 NER工具库
目前已经有很多现成的(off-the-shelf)NER工具,论文(见参考文献)对学术界和工业界一些NER工具进行汇总,工具中通常都包含预训练模型,可以直接在自己的语料上做实体识别。如果涉及到自己所在特定的领域,还需要依据待抽取领域语料重新训练模型。

4 序列标注标签方案
 BIO:标识实体的开始,中间部分和非实体部分
BIO:标识实体的开始,中间部分和非实体部分
BIOS:增加S单个实体情况的标注
BIOSE:增加E实体的结束标识
下面是BIO和BIOSE的举例

采用不同的标注体系,会对模型产生不同的影响。“BIO”、“BMES”、“BIOES”是常用的三种标签体系,此外还有BIO、BIOSE、IOB、BILOU、BMEWO等,其思想在于一个实体词拥有起始位置和终止位置,而每个字符都充当了构成一个实体词的特定成分,例如:
1)单标签实体标注
在进行多个实体类型识别时,则需要构造相应数量级的实体标签集合。
例如,在这个框架下进行标注时,机构类型ORG,对应于B-ORG,I-ORG的标签类型,给定句子: “我毕业于北京语言大学”,
利用BIO标签标注为:
“我/O 毕/O 业/O 于/O 北/B-ORG 京/I-ORG 语/I-ORG 言/I-ORG 大/I-ORG 学/I-ORG”。
2)多标签实体标注
针对所有可能出现重叠的实体类型,进行标签的两两组合,产生新的标签集合。
例如将“B-Loc”与“B-Org”组合起来,构造一个新的标签“B-Loc|Org”,然后同样作为一个单标签分类问题,针对每个字符,输出对应的标签。
设置多个标签层,对于每一个token给出其所有的label,然后将所有标签层合并。
3)单层指针标注
MRC中通常根据1个question从passage中抽取1个答案片段,转化为若干个n元SoftMax分类预测头指针和尾指针。
对于NER可能会存在多个实体Span,因此需要转化为n个2元Sigmoid分类预测头指针和尾指针。
对每个span的start和end进行标记,对于多片段抽取问题转化为N个2分类(N为序列长度),如果涉及多类别可以转化为层叠式指针标注(C个指针网络,C为类别总数)。
4)多层指针标注
多层label指针网络是对单层指针网络的扩展。由于只使用单层指针网络时,无法抽取多类型的实体,通常可以构建多层指针网络,每一层都对应一个实体类型。
5)多头指针标注
对对每个token pair进行标记,其实就是构建一个 [公式] 的分类矩阵,可以用于实体或关系抽取。其重点就是如何强有力的表征构建分类矩阵。对于每类实体,常采用标签-实体类型的方式进行标记,构建一个 [公式] 的Span矩阵。
5)片段序列标注
片段序列标注源自于Span-level NER的思想,枚举所有可能的span进行分类,同序列长度进行解耦,可以更加灵活地处理复杂抽取和低资源问题。
对于含T个token的文本,理论上共有N=T(T+1)/2种片段排列。如果文本过长,会产生大量的负样本,在实际中需要限制span长度并合理削减负样本。
5 四类NER方法(规则-无监督学习-机器学习-深度学习)
5.1 基于规则的NER
基于规则,其思想在于在观察特定的领域文本以及实体出现的语法构成和模式的情况后,设计特定的实体提取规则以完成提取。
实体词表、关系词或属性词触发词表、正则表达式是基于词典规则方法的三大核心部件,主要是2种方式:
1.基于实体词表的匹配识别
基于实体词表的匹配识别是使用最广泛的一种实体识别方法,虽然实体词表实现目标文本词表的有限匹配,但见效十分快速。
一般,在进行领域实体识别时,每个特定领域都有专属的实体词典,如医药行业的药名、科室名、手术名,汽车行业的车型、车系、品牌名称,金融行业中的公司词典、行业词典,招聘领域的职位词典等,这些词典都可以用来进行实体识别。
对于有歧义的词汇,可以先进行分词,比如采用最大匹配法,在分词的基础上在进行NER任务。
2. 基于规则模板的匹配识别
规则模板可以实现对实体词表识别的扩展,其中的核心在于规则模板的设计,在此之前需要分析实体词或者属性值的构词规则,包括基于字符构词规则的识别以及基于词性组合规则的识别两种。其中,基于字符构词规则的识别采用正则表达式进行提取。例如:
-
Email的表现形式通常为xxxx@xxx.com;利用“^\w+([-+.]\w+)@\w+([-.]\w+).\w+([-.]\w+)*$”来匹配Email地址,
-
借助“\d{4}[年-]\d{1,2}[月-]\d{1,2}日”的正则模板表达式来提取日期;
5.2 基于无监督学习方法
基于无监督的方法,主要是基于聚类的方法,或者基于实体与种子术语的相似度判定方法,在大规模未标注语料上使用词汇特征进行统计分析,以实现实体识别。根据文本相似度得到不同的文本簇,表示不同的实体组别,常用到的特征或者辅助信息有词汇资源、语料统计信息(TF-IDF)、浅层语义信息(分块NP-chunking)等。
5.2 基于机器学习(含特征的有监督学习)
基于有监督的特征学习方法,就是通过见NER任务转换为一个token级别的多分类问题或者是序列标注问题,成为一个基于字符的打标签(分类)问题,通过构造标注数据,训练标注模型,即将不同字符映射成为不同的标签的过程。深度学习方法也是基于这两个任务。
特征工程:word级特征(词性特征,词性标注);词汇特征(维基百科);文档语料级别特征。
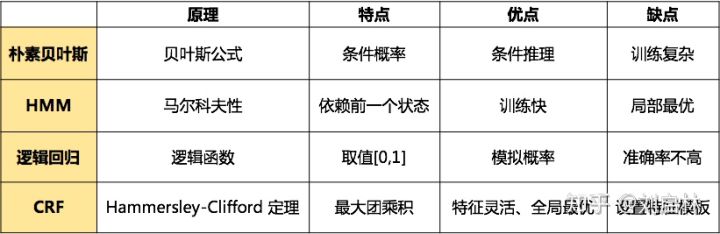
算法:隐马尔可夫模型(HMM);决策树(DT);最大熵模型(MEM);支持向量机(SVM);条件随机场(CRF)。
5.3 基于深度学习方法
深度学习的优势
- 强大的向量表示能力;
- 神经网络的强大计算能力;
- DL从输入到输出的非线性映射能力;
- DL无需复杂的特征工程,能够学习高维潜在语义信息;
- 端到端的训练方式
一个标准的NER模型可以建模成由输入层、编码层和解码层三层结构结构。
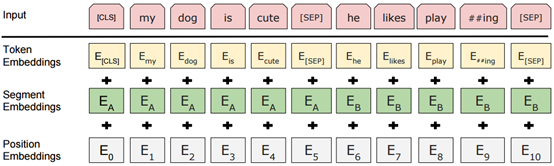
 输入层:解决字符序列到分布式序列的转换
输入层:解决字符序列到分布式序列的转换
编码层:用于特征建模和语义编码,学习整个句子和实体的语义表示
解码层:预测实体的边界以及实体的类型。
例如,BI-LSTM+CRF是一个十分普遍的实体识别基准模型。在构造上,使用两个 LSTM进行语义编码,一个从左往右跑得到第一层表征向量,一个从右往左跑得到第二层向量,然后两层向量加一起得到第三层向量。
如果不使用CRF,则后面直接接一层全连接和softmax,进行实体标签预测。
如果用CRF,则把第三层向量输入到 CRF 层中,经过 CRF进行计算来决定最终结果。
1、输入层
输入层解决从字符序列进行分布式表示的转换,
例如:针对“小勇毕业于北京语言大学”这个字符序列进行数值化,先进行字符切分,
得到[“小”,“勇”,“毕”,“业”,“于”,“北”,“京”,“语”,”言”,“大”,”学”]等字符列表,或者是词级别序列。
- 词级别表示 word-level representation
首先Mikolov提出的word2vec(两种框架CBOW和skip-gram),斯坦福的Glove,Facebook的fasttext和SENNA。 - 字符级别表示 character-level representation
字符级别通常是指英文或者是其他具备自然分隔符语种的拆开嵌入,在中文中指字级别嵌入,字符嵌入主要可以降低OOV率。文中给出了两种常用的字符级别嵌入方式,分别为CNN、RNN。
2、编码层
编码层,解决特征抽取的问题,以捕获实体上下文的特征表示。典型的编码方式有三种:
1)CNN编码器。 CNN可以方便的获取局部特征(如n-gram特征),并通过padding操作,可以让CNN的输出层与输入层具有相同的序列长度,从而通过CNN来进行序列相关的特征抽取,为了解决CNN无法捕获长距离特征的问题,后面逐步出现了膨胀卷积神经网络以及迭代膨胀神经网络;

句子经过embedding层,一个word被表示为N维度的向量,随后整个句子表示使用卷积(通常为一维卷积)编码,进而得到每个word的局部特征,再使用最大池化操作得到整个句子的全局特征,可以直接将其送入解码层输出标签,也可以将其和局部特征向量一起送入解码层。
2)RNN编码器。 循环卷积神经网络RNN能够获取当前位置之前与之后的信息,更好的建模上下文信息,成为了常用的编码器选择如LSTM,GRU等,为了更好的学习前后两向信息,通常会采用双层编码器结构;
 递归神经网络 Recursive Neural Networks
递归神经网络 Recursive Neural Networks
递归神经网络采用基于非线性自适应模型,能够通过给定的拓扑结构进行遍历,学习到深度结构化信息,如通过句法分析后,学习短语之间的组合关系。
递归神经网络相较循环神经网络,最大区别是具有树状阶层结构。循环神经网络一个很好的特性是通过神经元循环结构处理变长序列,而对于具有树状或图结构的数据很难建模(如语法解析树)。还有一点特别在于其训练算法不同于常规的后向传播算法,而是采用BPTS (Back Propagation Through Structure)。

3)Transformer编码器。
Google的一篇《Attention is all you need》将注意力机制推上新的浪潮之巅,于此同时transformer这一不依赖于CNN、RNN结构,纯堆叠自注意力、点积与前馈神经网络的网络结构也被大家所熟知。此后的研究证明,transformer在长距离文本依赖上相较RNN有更好的效果。

2015-2019年,Bi-LSTM+CRF的命名实体识别基准模型成为了序列标注方法下进行实体识别的模型标配,BERT出现后,BERT-CRF、BERT-LSTM-CRF迅速成为了新的基准模型选择。
3、解码层
解码层用于预测实体的边界以及实体的类型,是整个实体识别模型的最后阶段,通过编码层对实体上下文的抽象语义表示,生成相应的标签序列。常用的标签解码器包括
1)MLP+Softmax解码器。
将序列标注任务转化为一个多分类问题,每个单词的标签根据上下文相关的表示独立预测的,做了局部的考虑,即当前词的标签,不受其它标签的影响,所以并不考虑它的邻居标签结果;
2)循环神经网络RNN解码器。
与MLP+Softmax解码器不同,考虑了上一标签的解码结果,采用全局贪婪的策略,先计算出第一个位置的标签,然后后面每一个位置的标签都基于前面的状态得出,但并不考虑标签之间的出现依赖关系;
文中所述当前输出(并非隐藏层输出)经过softmax损失函数后输入至下一时刻LSTM单元,所以这是一个局部归一化模型。

3)条件随机场CRF解码器。
在循环神经网络解码器的基础上,将标签之间的依赖关系加以考虑,CRF将输出层面的关联性分离出来,在预测标签时充分考虑上下文关联,学习得到一些基于全局的约束信息,比如句子中识别出的实体标签的起始应当是“B-”而不是“I-”;不同类的标签不会相互连接,识别出的人名、地名、组织名标签不可能混搭,从而能够识别出准确的命名实体。
4)指针网络Pointer network编码器。
指针网络解码器将序列标注问题转化为先分块再分类两个子任务,其中先分块指找出实体的开始位置和结束位置,然后对识别出的实体块进行类型识别。
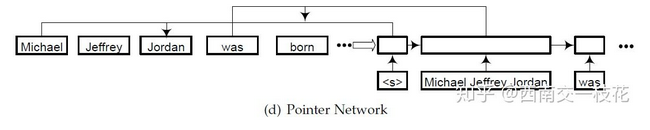
指针网络编码器采用循环解码的结果,从头开始找下一个块结束的位置,然后将这个块进行分类确定类别,之后再继续找下一个块的结束位置,再将这个块进行分类,一直循环直到序列结束。
6 其他
6.1 实体识别任务中的常见问题及对策
1、实体识别对象的复杂性
与典型用于学术评测的实体识别数据集不同,在真实工业场景中所面临的文本是复杂多样的,无论是在格式,还是在文本的规范性上都呈现出复杂的特点。
例如,常见的文本拼写错误(同音不同字错误、同形错字、多字错误、缺字错误、顺序错误)、标点错误、数字错误、经OCR方法以及其他文件转换(如pdf转txt中表格内容发生的错乱和换行)等。
在这种情况下,通常需要包括错字纠正、换行复原、繁体转简体、拼音转中文、英文转翻译、字符标准化等基础规范化操作,使用正则表达式等方式进行数据清洗,将该文本转化为标准的规范化文本。
2、实体类型一对多的问题
实体类型定义是进行实体识别任务的第一个步骤,在通常情况下,都会根据业务需求来确定需要识别的实体类型。但实体类型在标注的时候存在很大的主观性。
例如,地点类实体和机构类实体的区分,
“我在中科院软件所”和“我就职于中科院软件所”中的“中科院软件所”可以是地点类实体和机构类实体,
又如“巴尔的摩打败了纽约洋基队”中的“巴尔的摩”就被MUC-7标注为了地点而不是组织,
而”帝国“和”帝国大厦“都在CoNLL2003当中被标注为了地点,那么实体的边界划分也会出先歧义。
此外,随着实体识别在领域应用中的推广,多类型实体的识别,尤其是开放域细粒度实体识别逐步成为了一个重大问题。
实际上,实体类型标签的设计在实体识别中是一个十分基础且关键的工作,常常需要“科学”地设定,即对问题进行科学建模,以最小化模型搭建的难度。
例如,针对一些并不常见的长尾标签,某些实体标签下的样本在实际语料中本身就很少出现,那么就可以将这一类试题类型设置为“其他”,然后在下一阶段采用规则的方法进行进一步处理;
又如,针对容易混淆的实体标签,先考虑对这些标签进行合并,如果不行,那么先将这类标签进行统一,然后在下一阶段采用规则方式规则处理;
又如,针对多类型实体识别问题(标签设置可能达到几百个),可以进一步归类成大类-小类的多层级标签体系进行处理,也可以转化为多个二分类问题。
3、实体成分重叠(实体嵌套)的问题
实体重叠,又称实体嵌套(Nested NER),即在一个实体的内部还存在着一个或多个其他的实体,是实体识别过程中常见的问题。
例如: “北京市海淀区”中存在北京市和海淀区两个实体;
“马亲王发布新书长安十二时辰”,其中“长安”和“长安十二时辰”可能都是待抽取实体,一个地名一个书名,
“北京大学”不仅是一个组织,同时“北京”也是一个地点,雅诗兰黛小棕瓶是一个产品,同时“雅诗兰黛”是一个品牌。
实际上,根据Katiyar等人的统计,ACE 2004,ACE 2005数据集中主要包含7种实体类型,其中含有嵌套命名实体的句子占30%左右。GENIA数据集中主要包含4种实体类型,其中含有嵌套命名实体的句子占17%左右。
为了解决实体成分重叠的问题,相关研究人员陆续提出了几种解决方案,包括
- 基于组合单标签的实体识别;
- 基于多标签分类的实体识别;
- 基于多标签层的实体识别;
- 基于堆叠层次的实体识别;
- 基于基于区域分类的实体识别;
- 基于MRC方法的实体识别方法。
4、实体成分非连续的问题
实体名非连续也是实体识别中常见的一类问题,指实体名称的部分分离在不同的地方。
例如“我这有iphone11和12”中包含了“iphone11”和“iphone12”两个实体,“尿道、膀胱、肾绞痛”中存在 “尿道痛”、“膀胱痛”、“肾绞痛”三个非连续实体。
在ShARe/CLEF Health Evaluation Lab 2013数据集中,大概有10%的实体存在不连续或者相互重叠的情况。
5、实体名称范围过长的问题
实体名称过长(也叫span过长)的问题是实体识别中的又一难题,例如某个精确到门牌号的地点通常十分长,如“北京市海淀区中关村派出所52号院23栋2单元302室”,有些医疗术语也很长,甚至达到几十个字等情况,这使得在抽取时候经常出现断裂问题。
为了解决这个问题,通常会采取基于指针网络的方式进行提取,通过识别实体的span,然后再进行实体类型的分类。
6、词典规则方法下的实体冲突问题
实体冲突问题,是实体识别过程中的一类常见问题。
例如,一个句子中通过匹配得到了词典中的多个实体名称(如“我在北京语言大学”中可以匹配到“北京”和“北京语言大学”两个实体);
匹配得到的实体可以映射成不同的实体类型(如“我买了苹果”中的“苹果”可以是公司名,也可以是水果名)。
为了解决这个问题,通常需要制定一些冲突解决规则,例如:
- 先被识别出的实体替换掉后识别的实体;
- 长的实体替换掉短的实体;
- 制定实体评分函数,对识别出的实体进行评分,将分数低的实体替换为分数高的实体。
7.回到工业界,快速冷启动和快速响应是工业实体识别中的两个关键问题
因此,在这一大背景下,在真实的工业界场景中,通常面临标注成本昂贵、泛化迁移能力不足、计算资源受限等问题。
因此,通常会优先地选择“词典+规则”的方式先解决实体识别冷启动的问题,然后在此基础上在考虑使用有监督识别的方法。
一方面,以实体词典和实体构词规则为核心的规则实体识别方法能够在短时间内快速见到效果,但对于未登陆词(OOV)的识别上,就会受到较大的瓶颈,因为词典的收集以及实体构词规则十分耗费人力,所能涵盖的范围也相对受限。另一方面,实体的很多特征往往都无法通过形式化的规则表现出来。
其次,在实体识别任务中,经常会收到私有化部署以及QPS要求高的问题(尤其是在硬件条件不够的情况下),这时候,基于预训练语言模型的识别方法往往不是优选,需要考虑到其对资源的需求以及推理速度上的劣势,可以先选用轻量的模型先上一个版本。
此外,通过QA阅读理解的新方式进行命名实体识别,在某些领域中过效果也许会提升,但计算复杂度上来了,因为需要对同一文本本进行多次编码,对于长文本,还需要采取滑窗的方式进行处理,这样的复杂程度在实际选用过程中还是需要注意。
6.2 各类研究方向的NER方法
下面列出各类研究方向的NER方法,若想细致了解每个方向的文献,请移步原文。
多任务学习 Multi-task Learning
深度迁移学习 Deep Transfer Learning
深度主动学习 Deep Active Learning
深度强化学习 Deep Reinforcement Learning
深度对抗学习 Deep Adversarial Learning
注意力机制 Neural Attention
6.3 NER任务的挑战与机遇
挑战
数据标注
非正式文本(评论、论坛发言、tweets或朋友圈状态等),未出现过的实体。
机遇与未来可研究方向
多类别实体
嵌套实体
实体识别与实体链接联合任务
利用辅助资源进行基于深度学习的非正式文本NER(补充一点,知识图谱方向)
NER模型压缩
深度迁移学习 for NER
Reference
1 https://mp.weixin.qq.com/s/-vpybS-l9QIhxCJbkRzxQg
2 论文《A Survey on Deep Learning for Named Entity Recognition》
链接:https://arxiv.org/pdf/1812.09449.pdf
3 https://zhuanlan.zhihu.com/p/77868938
4 https://zhuanlan.zhihu.com/p/350616879