献给英语不好的小白们
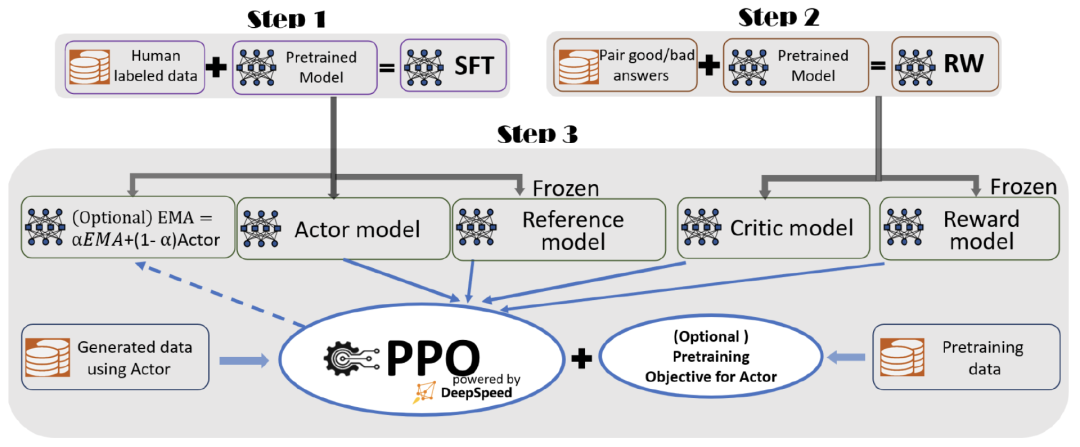
我们已经在ChatGPT中实现了插件的初始支持。插件是专门为语言模型设计的工具,具有安全性作为核心原则,帮助ChatGPT获取最新的信息,运行计算或使用第三方服务。
前言
为了符合我们的迭代部署哲学,我们正在逐步推出ChatGPT中的插件,以便我们可以研究它们在现实世界中的使用、影响、安全和对齐挑战,这些都是我们必须正确处理才能实现我们的使命。
自从我们推出ChatGPT以来,用户一直在要求插件(许多开发人员正在尝试类似的想法),因为它们可以解锁大量可能的用例。我们从一小部分用户开始,计划在学习更多内容后逐步推出更大规模的访问(针对插件开发人员、ChatGPT用户以及在alpha测试期后,希望将插件集成到其产品中的API用户)。我们很高兴建立一个社区,来塑造人类和人工智能交互范式的未来。
被邀请进入我们等待名单的插件开发人员可以使用我们的文档为ChatGPT构建插件,然后将启用的插件列在显示给语言模型的提示中,以及提供文档来指导模型如何使用每个插件。第一批插件由 Expedia1 、FiscalNote2、Instacart3、KAYAK4、Klarna5、Milo6、OpenTable7、Shopify8、Slack、Speak9、Wolfram10和Zapier11创建。
我们还自己托管了两个插件,一个是网页浏览器,另一个是代码解释器。我们还开源了知识库检索插件的代码,任何希望增强ChatGPT信息的开发人员都可以自行托管。
今天,我们将开始向等待名单中的用户和开发人员扩展插件alpha访问权限。虽然最初我们会优先考虑少量开发人员和ChatGPT Plus用户,但我们计划逐步扩大访问规模。
概述
语言模型今天虽然对于各种任务都很有用,但仍然存在限制。它们只能学习自己的训练数据中的信息,这些信息可能已经过时,并且在应用程序中适用于所有人。此外,语言模型只能默认生成文本,这些文本可能包含有用的指令,但要实际遵循这些指令,您需要另一个进程。
虽然这不是一个完美的比喻,但插件可以成为语言模型的“眼睛和耳朵”,使它们能够访问太新、太个人化或太特定以至于无法包含在训练数据中的信息。在用户明确要求的情况下,插件还可以使语言模型代表用户执行安全、受限制的操作,从而增加整个系统的有用性。
我们预计将出现开放标准,以统一应用程序公开面向AI的接口的方式。我们正在尝试早期版本的这种标准,我们正在寻找有兴趣与我们一起构建的开发人员的反馈。
今天,我们开始逐渐启用来自早期合作伙伴的现有插件,供ChatGPT用户使用,首先为ChatGPT Plus订阅用户。我们还开始推出开发人员创建自己的ChatGPT插件的功能。
在未来的几个月中,随着我们从部署中学习并继续改进我们的安全系统,我们将对这个协议进行迭代,并计划使使用OpenAI模型的开发人员能够将插件集成到ChatGPT之外的应用程序中。
安全和更广泛的影响
将语言模型连接到外部工具既带来了新的机会,也带来了重大的新风险。
插件提供了解决大型语言模型所面临的各种挑战的潜力,包括“幻觉”、跟上最新事件和访问(经过许可的)专有信息源。通过集成外部数据的明确访问权限,例如在线最新信息、基于代码的计算或自定义插件检索的信息,语言模型可以通过基于证据的参考加强其回应。
这些参考不仅增强了模型的实用性,还使用户能够评估模型输出的可信度并核对其准确性,潜在地减轻了过度依赖所带来的风险,正如我们最近的GPT-4系统卡中所讨论的那样。最后,插件的价值可能远远超出了解决现有限制的范围,帮助用户处理各种新用例,从浏览产品目录到预订机票或订购食品。
同时,插件可能会增加安全挑战,导致模型采取有害或意外的行动,增加坏行为者欺诈、误导或滥用他人的能力。通过扩大可能的应用范围,插件可能会提高因模型在新领域中采取错误或不协调的行动而导致的负面后果的风险。从第一天起,这些因素就指导了我们插件平台的开发,并实施了几项安全保障措施。
从一开始,这些因素就指导了我们插件平台的开发,并且我们已经实施了几项安全措施。
我们进行了内部和外部合作伙伴的红队演练,发现了许多可能引起关注的情况。例如,我们的红队发现,如果插件发布没有保护措施,它们可以进行复杂的提示注入,发送欺诈和垃圾邮件,绕过安全限制或滥用发送给插件的信息。我们利用这些发现来制定安全设计缓解措施,限制高风险的插件行为,并提高其在用户体验中运行的方式和时间的透明度。我们还利用这些发现来指导我们决定逐步开放插件访问权限。
如果您是一位研究人员,对此领域的安全风险或缓解措施感兴趣,我们鼓励您使用我们的研究人员访问计划。我们还邀请开发人员和研究人员提交与我们最近开源的 Evals 框架相关的插件安全和功能评估。
插件可能会产生广泛的社会影响。例如,我们最近发布了一份工作论文,发现拥有工具访问权限的语言模型可能比没有访问权限的模型产生更大的经济影响,而且总体上,与其他研究人员的发现一致,我们预计当前的人工智能技术浪潮将对职业转型、替代和创造的速度产生巨大影响。我们非常乐意与外部研究人员和客户合作研究这些影响。
插件类型
Web浏览(Browsing)
一个实验性模型,它知道何时以及如何浏览互联网
受到之前的研究工作(我们自己的WebGPT,以及GopherCite、BlenderBot2、LaMDA2等)的启发,允许语言模型从互联网上获取信息严格扩展了它们可以讨论的内容量,超越了训练语料库,获取了来自现代的新鲜信息。
以下是浏览器为ChatGPT用户开启的一种体验示例,而以前该模型可能只会礼貌地指出,它的训练数据没有包含足够的信息来回答。这个示例中,ChatGPT检索了关于最新奥斯卡奖的最新信息,然后执行了现在已经熟悉的ChatGPT诗歌壮举,这是浏览可以作为增量体验的一种方式。
除了为最终用户提供明显的实用性之外,我们认为使语言和聊天模型能够进行彻底且可解释的研究,对于可扩展的对齐具有令人兴奋的前景。
安全考虑
我们创建了一个Web浏览插件,让语言模型可以访问Web浏览器,其设计优先考虑了安全性,并作为网络的良好用户进行操作。插件的基于文本的Web浏览器仅限于进行GET请求,这减少了(但并未消除)某些安全风险的类别。这将浏览插件的范围限定为有用于检索信息,但排除了“交易”操作(例如表单提交),因为它们具有更多的安全和安全问题。浏览使用Bing搜索API从Web检索内容。因此,我们继承了微软在信息来源的可靠性和真实性以及“安全模式”方面的大量工作,以防止检索到有问题的内容。该插件在一个隔离的服务中运行,因此ChatGPT的浏览活动与我们基础设施的其余部分分离。
为尊重内容创建者并遵守Web的规范,我们的浏览器插件的用户代理令牌为ChatGPT-User,并配置为遵守网站的robots.txt文件。这有时可能导致“点击失败”消息,这表示插件正在遵守网站的指示以避免爬取它。此用户代理仅用于代表ChatGPT用户采取直接操作,并不用于以任何自动方式爬取Web。我们还发布了我们的IP出口范围。此外,实施了速率限制措施,以避免向网站发送过多的流量。
我们的浏览插件在ChatGPT的响应中显示访问的网站并引用其来源。这种增加的透明度帮助用户验证模型的响应的准确性,并为内容创作者提供了回馈。我们欣赏这是一种与Web互动的新方法,并欢迎有关进一步将流量驱动回源并增加生态系统整体健康的反馈。
代码解释器(Code interpreter)
一个实验性的ChatGPT模型,可以使用Python,处理上传和下载。
我们在一个受沙盒、防火墙限制的执行环境中为我们的模型提供一个工作的Python解释器,并提供一些临时磁盘空间。我们的解释器插件运行的代码在一个持久的会话中进行评估,该会话在聊天对话期间一直保持活动状态(有一个上限超时时间),后续的调用可以在其基础上进行构建。我们支持将文件上传到当前的聊天工作区并下载工作结果。
我们希望我们的模型能够利用其编程技能,为计算机的大多数基本功能提供更自然的界面。拥有一个极其热情的初级程序员,以指尖的速度工作,可以使全新的工作流程变得轻松高效,并将编程的好处带给新的受众。
根据我们最初的用户研究,我们确定了使用代码解释器特别有用的用例:
- 解决数学问题,包括定量和定性问题
- 进行数据分析和可视化
- 在不同格式之间转换文件
我们邀请用户尝试代码解释器集成并发现其他有用的任务。
安全考虑
连接我们的模型到编程语言解释器主要考虑如何正确地隔离执行,以避免人工智能生成的代码在现实世界中产生意外的副作用。我们在受保护的环境中执行代码,并使用严格的网络控制,以防止执行的代码访问外部互联网。此外,我们对每个会话设置了资源限制。禁用互联网访问限制了我们的代码沙盒的功能,但我们认为这是正确的初步权衡。第三方插件被设计为将我们的模型与外部世界连接起来的安全优先方法。
检索(Retrieval)
开源的Retrieval插件使ChatGPT能够访问个人或组织信息源(经过许可)。它允许用户通过自然语言提问或表达需求,从他们的数据源(如文件、笔记、电子邮件或公共文档)中获取最相关的文档片段。
作为一种开源和自托管的解决方案,开发人员可以部署自己的插件版本并在ChatGPT中进行注册。该插件利用了OpenAI的嵌入技术,并允许开发人员选择一个矢量数据库(Milvus、Pinecone、Qdrant、Redis、Weaviate或Zilliz)来索引和搜索文档。信息源可以使用Webhook与数据库同步。
要开始使用,请访问Retrieval插件仓库。
安全考虑
retrieval插件允许ChatGPT搜索一个向量数据库的内容,并将最佳结果添加到ChatGPT会话中。这意味着它没有任何外部影响,主要的风险是数据授权和隐私。开发人员应仅将其有权使用并可以在用户的ChatGPT会话中共享的内容添加到其retrieval插件中。
第三方插件(Third-party plugins)
一个实验性的模型,它知道何时以及如何使用插件。
第三方插件由清单文件描述,其中包括插件功能的机器可读说明以及如何调用它们的说明和用户文档。
{"schema_version": "v1","name_for_human": "TODO Manager","name_for_model": "todo_manager","description_for_human": "Manages your TODOs!","description_for_model": "An app for managing a user's TODOs","api": { "url": "/openapi.json" },"auth": { "type": "none" },"logo_url": "https://example.com/logo.png","legal_info_url": "http://example.com","contact_email": "hello@example.com"
}
创建插件的步骤如下:
- 创建一个API,其中包含你想要语言模型调用的端点(这可以是新的API、现有的API,或者是专门为LLM设计的现有API的包装器)。
- 创建一个OpenAPI规范,记录你的API,以及一个链接到OpenAPI规范并包含一些插件特定元数据的清单文件。
在chat.openai.com上开始对话时,用户可以选择他们想要启用哪些第三方插件。启用的插件的文档将作为对话上下文的一部分显示给语言模型,从而使模型能够根据需要调用适当的插件API以实现用户意图。目前,插件设计用于调用后端API,但我们正在探索能够调用客户端API的插件。
展望未来
我们正在努力开发插件并将它们带给更广泛的受众。我们有很多东西要学习,希望在大家的帮助下建立既有用又安全的东西。
【Expedia】将您的旅行计划变成现实——到达那里、留在那里,并找到值得看和做的事情。 ↩︎
【FiscalNote】为法律、政治和监管数据和信息提供市场领先的实时数据集的访问。 ↩︎
【Instacart】从您最喜爱的本地商店订购商品。 ↩︎
【KAYAK】搜索航班、住宿和租车。根据您的预算,为您推荐所有可以去的地方。 ↩︎
【Klarna Shopping】从数千家在线商店搜索和比较价格。 ↩︎
【Milo Family AI】给予父母超能力,让每天的20分钟变得神奇起来。询问:“嘿,Milo,今天有什么魔法?” ↩︎
【OpenTable】提供餐厅推荐,并直接提供预订链接。 ↩︎
【Shop】从全球顶尖品牌搜索数百万种产品。 ↩︎
【Speak】使用Speak,您的AI语言导师,学习如何用另一种语言说任何事情。 ↩︎
【Wolfram】通过Wolfram|Alpha和Wolfram Language访问计算、数学、筛选过的知识和实时数据。 ↩︎
【Zapier】与5000多个应用程序进行交互,例如Google Sheets、Trello、Gmail、HubSpot、Salesforce等。 ↩︎