1 命名实体识别概述
1.1 定义
命名实体识别(Name Entity Recognition,NER),也称作“专名识别”,是指识别文本中具有特定意义的实体,包括人名、地名、机构名、专有名词等。
1.2 形式化定义
给定标识符集合S=<w1,w2,...,wN>,NER输出一个三元组<Is,Ie,t>的列表,列表中的每个三元组代表S中的一个命名实体。Is为命名实体的起始索引,Ie为命名实体的结束索引,t为实体的类型。

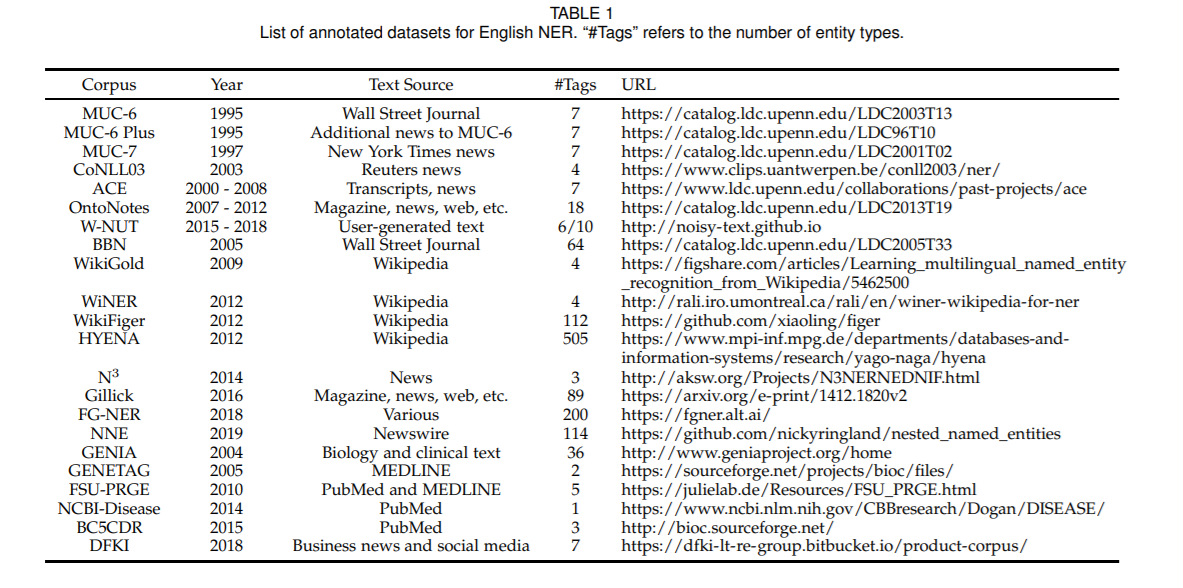
1.3 常用数据集
CoNLL、OntoNotes、MSRA、Weibo、Resume
1.4 评价标准
NER任务需要同时确定实体边界以及实体类别,只有当实体边界以及实体类别同时预测正确时,才能被认定为预测正确。一般采用精确率(precision)、召回率 (recall)和F1值进行评价。
1.5 难点
1)未登录词(OOV)
2)类别模糊。比如地名和机构名,有一些地名本身也是机构。
3)构词灵活。比如中国工商银行,既可以称为工商银行,也可以简称为工行。
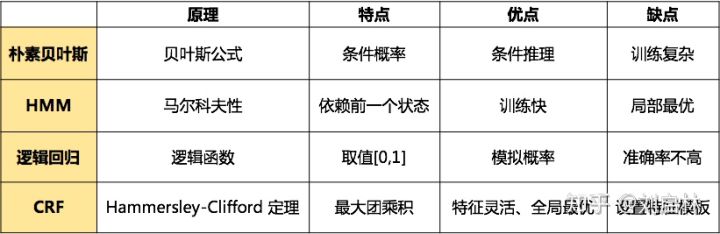
2 方法分类
1)从模型的层面,可以分为基于规则的方法、无监督学习方法、有监督学习方法:
- 基于规则的方法:依赖人工制定的规则,规则的设计一般基于句法、语法、词汇的模式,以及特定领域的知识。当词典的大小有限时,基于规则的方法可以达到很好的效果。这种方法通常具有高精确率和低召回率的特点。但是这种方法无法难以迁移到别的领域,对于新的领域需要重新制定规则。
- 无监督学习方法:利用语义相似性进行聚类,从聚类得到的组当中抽取命名实体,通过统计数据推断实体类别。
- 基于特征的监督学习方法:可以表示为多分类任务或者序列标注任务,从数据中学习。
2)从输入的层面,可以分为基于字(character-level)的方法、基于词(work-level)的方法、两者结合的方法。
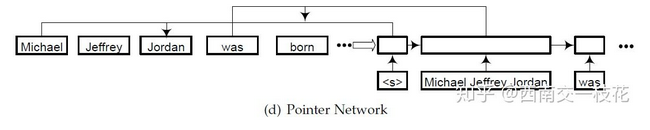
3 论文笔记
================================================================================================
NAACL 2016:Neural Architectures for Named Entity Recognition
================================================================================================


概述
之前的NER模型依赖手工特征和领域知识,从小数据集上学习。本文提出的模型不依赖于手工特征,结合character-based的单词表示和预训练的词向量,可以达到state-of-the-art效果。
模型架构
本文提出两种模型架构:1)BiLSTM+CRF、2)Stack LSTM
1)BiLSTM+CRF
设输入为![]() ,首先使用BiLSTM进行编码,得到每个单词的表示
,首先使用BiLSTM进行编码,得到每个单词的表示![]() 。
。
然后输入到CRF层,得到结果:
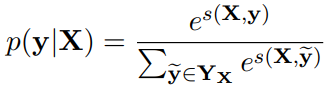 ,
,![]()
2)Stack LSTM
参考《Transition-based dependency parsing with stack long short-term memory》,非文本重点,不详细介绍。
3)Input Word Embeddings
使用一个模型,通过组成单词的字符的表示,来构造单词的表示。
使用BiLSTM获取组成单词的字符序列的表示,并把最终表示和单词的词向量进行拼接。
实验结果





================================================================================================
ACL 2017:Fast and Accurate Entity Recognition with Iterated Dilated Convolutions
================================================================================================
概述
本文指出,之前的基于RNN的模型无法很好的利用GPU的并行计算能力,本文提出空洞卷积(dilated convolutions)的网络架构ID-CNNs用于处理NER问题。相对于传统的RNN模型,在短句子上运行可以提高14-20倍的速度,在文档上可以提高8倍的速度。相对于普通卷积,更有效的捕获长距离依赖。
空洞卷积可以更好的利用全局信息,但是单纯的堆叠空洞层,会导致过拟合。本文把多个空洞卷积层组成空洞卷积块,并且单纯的重复相同的空洞卷积模块,提取特征,可以有效减少过拟合。
再训练的时候,在每一个空洞卷积块后添加预测和损失计算,可以提高效果。
模型架构
设输入![]() ,
,![]()
![]() ,第j层空洞卷积层为
,第j层空洞卷积层为![]() 。
。
输入层卷积为![]() ,设
,设![]() ,
,![]() 为ReLU函数,则一个空洞卷积块中的卷积层计算为
为ReLU函数,则一个空洞卷积块中的卷积层计算为![]() 。在每个空洞卷积块最后添加一个步长为1的空洞卷积层
。在每个空洞卷积块最后添加一个步长为1的空洞卷积层![]() 。把以上的空洞卷积块表示为
。把以上的空洞卷积块表示为![]() 。
。
迭代重复使用空洞卷积块![]() 次,提取特征
次,提取特征![]() ,其中
,其中![]() 。
。
最后通过线性变换,得到最终输出结果![]() 。
。
训练模型时,本文考虑两种方式。
第一种,在最后一层使用交叉熵训练模型:
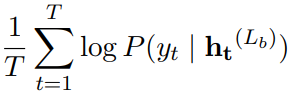
第二种,在训练网络时,使每个块都预测输出标签:
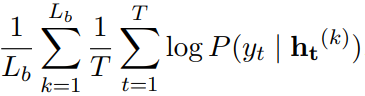
对输入![]() 和每个空洞卷积块的输出
和每个空洞卷积块的输出![]() 使用dropout。
使用dropout。
实验结果
短句子识别实验结果


文档识别结果



不同损失函数计算结果

================================================================================================
ACL 2018:Chinese NER Using Lattice LSTM
================================================================================================



概述
本文提出一种新的模型架构Lattice LSTM,可以同时利用character和word信息用于NER。
首先通过将一个句子与词典进行匹配,获取每个字对应的所有的潜在可能的词,然后通过模型自动选择利用相关词的信息。
模型架构
设输入句子为字序列![]() ,或者词序列
,或者词序列![]() ,第i个词中的第k个字在句子中的位置表示为
,第i个词中的第k个字在句子中的位置表示为![]() ,以位置b的字为开头,位置e的字为结尾的词表示为
,以位置b的字为开头,位置e的字为结尾的词表示为![]() 。
。
首先把字转变为字向量:![]() ,然后使用LSTM,计算隐藏状态:
,然后使用LSTM,计算隐藏状态:

但是这里的![]() 的计算方式,需要结合词信息,重新计算。
的计算方式,需要结合词信息,重新计算。
对于词,同样把每个候选的词转变为词向量![]() ,然后使用LSTM,计算隐藏状态:
,然后使用LSTM,计算隐藏状态:
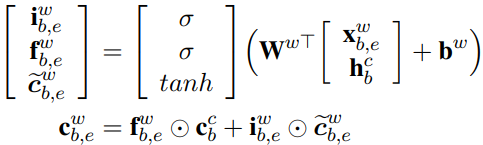
由于每个字可能对应多个词,这里为每个以该字结束的词分别计算一个权重,然后把所有的词信息和该字本身的信息结合,得到最后的隐藏状态:
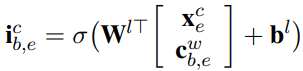
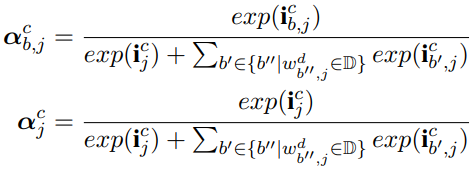
![]()
然后把隐藏状态输入到CRF层。
输出和损失函数使用传统的基于CRF的LSTM方式计算:
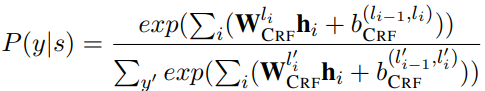
![]()
实验结果







================================================================================================
NAACL 2019:CAN-NER: Convolutional Attention Network for Chinese Named Entity Recognition
================================================================================================

概述
本文提出一种用于中文NER的模型架构,首先使用CNN与局部注意力结合捕获字间的局部信息,然后再使用BiGRU结合全局注意力捕获句子全局信息。
模型架构
设输入为![]() ,输出为
,输出为![]() 。输入的每个位置表示为
。输入的每个位置表示为![]() ,其中
,其中![]() 是字向量,
是字向量,![]() 是分词标签(BMES)向量。
是分词标签(BMES)向量。
1)Convolutional Attention Layer
对于每个字,提取窗口大小为k的上下文信息。
首先为窗口内的每个字拼接一个位置向量,位置向量大小为k,初始化时,对应的位置的值设为1,其他位置为0。所以本层的输入维度为![]() 。
。
然后使用局部注意力,计算字间的交互信息。对于输入![]() ,计算
,计算![]() :
:
![]()
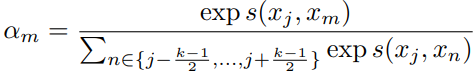
![]()
其中![]() 。
。
然后使用![]() 个卷积核提取信息
个卷积核提取信息
![]()
最后对第一个维度使用sum-pooling得到该字的隐藏表示。
2)BiGRU-CRF with Global Attention
首先使用BiGRU提取信息:![]() ,其中
,其中![]() 是Convolutional Attention Layer的输出,
是Convolutional Attention Layer的输出,![]() 是上一时刻的隐藏状态。
是上一时刻的隐藏状态。
然后使用全局注意力,得到每个字的最终表示:
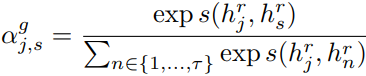
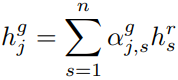
最后,把BiGRU的输出和计算全局注意力后的向量进行拼接![]() ,输入到CRF层,计算最终输出:
,输入到CRF层,计算最终输出:
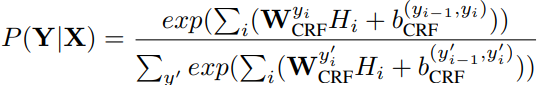
损失函数为
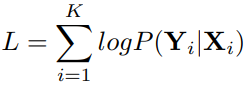
实验结果




================================================================================================
AAAI 2019:GRN: Gated Relation Network to Enhance Convolutional Neural Network for Named Entity Recognition
================================================================================================

概述
本文指出,之前的基于RNN的模型无法很好的利用GPU的并行计算能力,传统CNN架构无法有效捕获长距离信息,本文提出gated relation network (GRN),可以有效解决长距离信息问题。首先使用CNN来捕获每个词的局部上下文信息。然后,我们对词之间的关系建模,将局部上下文信息融合到全局特征当中。
模型架构
本模型有四部分组成:representation layer、context layer、relation layer、CRF layer。
设输入句子为![]() ,对应标签为
,对应标签为![]() 。
。
1)representation layer
使用CNN提取character-level特征,然后和word-level特征进行拼接,得到本层输出。
首先把每个词![]() 中的每个字表示为字向量
中的每个字表示为字向量![]() ,其中字向量开始时随机初始化。然后使用下图所示的CNN架构(卷积层+最大池化层)提取每个词的character-level特征。 卷积核的大小统一设置为3。
,其中字向量开始时随机初始化。然后使用下图所示的CNN架构(卷积层+最大池化层)提取每个词的character-level特征。 卷积核的大小统一设置为3。

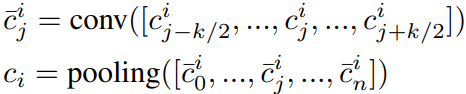
然后把词![]() 转换为词向量
转换为词向量![]() ,得到word-level特征。
,得到word-level特征。
最后把character-level特征和word-level特征拼接,得到word feature:![]() 。
。
2)context layer
参考InceptionNet,本文使用多分支的方式,使用不同尺寸的卷积核,分别在对应分支提取每个词的局部上下文特征。对于上一层的word feature输出![]() ,每个分支首先提取特征
,每个分支首先提取特征![]() ,然后使用tanh函数进行激活,接着对所有分支的同一位置的卷积核输出使用最大池化,得到该位置的卷积输出。卷积核的大小取1、3、5三种。
,然后使用tanh函数进行激活,接着对所有分支的同一位置的卷积核输出使用最大池化,得到该位置的卷积输出。卷积核的大小取1、3、5三种。

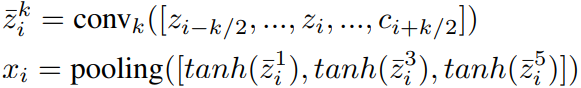
得到词![]() 的context feature
的context feature![]() 。
。
3)relation layer
通过对某个词和句子中其他词的关系进行建模,提取该词的全局上下文特征。
首先计算两个词之间的关系得分![]() :
:
![]()
得到![]() 后,我们有三种处理方式。
后,我们有三种处理方式。
第一种,简单的把所有单词的得分进行相加:
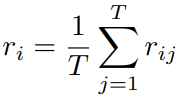
第二种,使用普通的注意力计算方式:
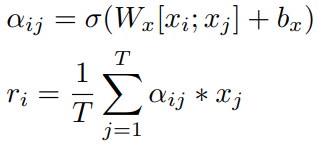
第三种,对![]() 使用sigmoid进行归一化之后,与对应单词的context feature相乘,然后把相乘后的得分相加:
使用sigmoid进行归一化之后,与对应单词的context feature相乘,然后把相乘后的得分相加:
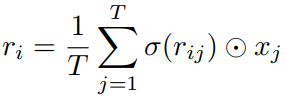
本文把第一种方式称为DFN,第二种方式称为GAttN,第三种方式称为GRN。
最后,通过tanh进行激活,得到每个单词的最终表示:
![]()
4)CRF layer
最后把每个单词的最终表示输入到CRF层,得到损失函数和预测结果:
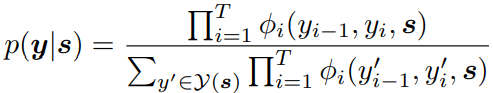
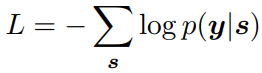
![]()
实验结果



================================================================================================
ACL 2020:TENER: Adapting Transformer Encoder for Named Entity Recognition
================================================================================================

概述
传统的Transformer在NER上效果不理想,主要基于两个原因:第一,传统的Transformer可以捕获距离信息,但是无法捕获方向信息;第二,传统的Transformer对参数的缩放和平滑,不适用于NER任务。
本文提出一种改进版本的Transformer(Adapted Transformer),对于第一个问题,提出使用相对位置编码,而不是绝对位置编码。对于第二个问题,取消了dot-production attention阶段的缩放因子。
同时,本文使用Transformer提取character-level信息,结合word-level的信息,共同使用。
模型架构
1)Embedding Layer
使用Adapted Transformer提取character-level信息,然后把得到的特征和预训练的词向量拼接,得到本层的输出。
2)Encoding Layer
为了更好的捕获方向和距离信息,本文提出使用以下方式计算:
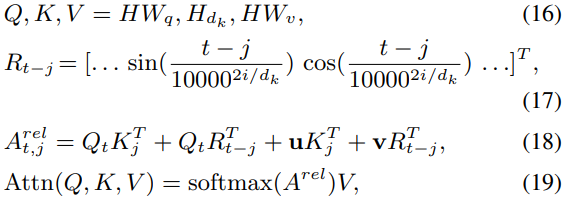
其中,t是目标token,j是上下文token,![]() 是两个token分别对应的行,
是两个token分别对应的行,![]() 是需要学习的参数。为了得到
是需要学习的参数。为了得到![]() ,首先把H在第二个维度切分成
,首先把H在第二个维度切分成![]() 份,对于多头注意力中的每个头,使用其中的一份。
份,对于多头注意力中的每个头,使用其中的一份。![]() 是相对位置编码。第公式(17)中,i的范围是
是相对位置编码。第公式(17)中,i的范围是![]() 。
。
然后直接把多个头的输出拼接,输入到全连接层。
![]()
3)CRF Layer
最后把Encoding Layer的输出,输入到CRF层,计算损失和输出:
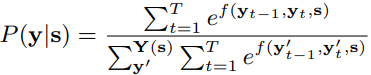
实验结果