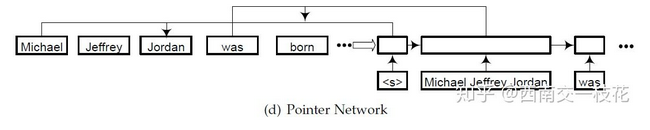
1.命名实体识别定义

例如:
2.常用开源的中英文NER工具


这些工具的缺点是:只提供通用型的实体类别如 人名,地方,组织,时间等,对于特定领域,可能很难提取出你需要的实体。
2.1 代码实践
代码来自贪心科技
nltk的基础用法请参见:nltk基础用法
paragraph1 = "Artificial Intelligence (AI) is the talk of the world and it features prominently in predictions \
for 2019 (see here and here) and recent surveys by consulting firms and other observers of the tech scene. \
Here are the key findings: Consumer adoption: “Smart speakers” lead the way to the AI-infused home of the future\
Smart speakers (e.g., Amazon Echo and Google Home) will become the fastest-growing connected device category \
in history, with an installed base projected to surpass 250 million units by the end of 2019. With sales of \
164 million units at an average selling price of $43 per unit, total smart speakers’ revenues will reach $7 billion, \
up 63% from 2018. "paragraph2 = "Beijing, Shanghai, Tianjin"import nltk
print('NTLK version: %s' % (nltk.__version__))
NTLK version: 3.5
from nltk import word_tokenize, pos_tag, ne_chunk
# print (word_tokenize(paragraph1) ) # 对句子进行分词,返回 list of str
[‘Artificial’, ‘Intelligence’,’(’, ‘AI’, ‘)’, ‘is’, ‘the’, ‘talk’, ‘of’, ‘the’, ‘world’, ‘and’, ‘it’, ‘features’, ‘prominently’, ‘in’, ‘predictions’, ‘for’, ‘2019’, ‘(’, ‘see’, ‘here’, ‘and’, ‘here’, ‘)’, ‘and’,…]
# print(pos_tag(word_tokenize(paragraph1))) #对分完词的句子进行词性标注,返回 list of tuple
[(‘Artificial’, ‘JJ’),(‘Intelligence’, ‘NNP’), (’(’, ‘(’), (‘AI’, ‘NNP’), (’)’, ‘)’), (‘is’, ‘VBZ’), (‘the’, ‘DT’),(‘talk’, ‘NN’), (‘of’, ‘IN’), (‘the’, ‘DT’), (‘world’, ‘NN’),(‘and’, ‘CC’), (‘it’, ‘PRP’), (‘features’, ‘VBZ’), (‘prominently’, ‘RB’), (‘in’, ‘IN’), (‘predictions’, ‘NNS’), (‘for’, ‘IN’),…]
results = ne_chunk(pos_tag(word_tokenize(paragraph1))) # ne_chunk 对标注词性的分词结果进行命名实体识别
print('The sentence is : %s' % (paragraph1))
print()
for x in str(results).split('\n'):if '/NNP' in x: #以NNP结尾的是实体print(x)
The sentence is : Artificial Intelligence (AI) is the talk of the world and it features prominently in predictions for 2019 (see here and here) and recent surveys by consulting firms and other observers of the tech scene. Here are the key findings: Consumer adoption: “Smart speakers” lead the way to the AI-infused home of the futureSmart speakers (e.g., Amazon Echo and Google Home) will become the fastest-growing connected device category in history, with an installed base projected to surpass 250 million units by the end of 2019. With sales of 164 million units at an average selling price of $43 per unit, total smart speakers’ revenues will reach $7 billion, up 63% from 2018.
Intelligence/NNP
AI/NNP
Consumer/NNP
Smart/NNP
(PERSON Amazon/NNP Echo/NNP)
(ORGANIZATION Google/NNP Home/NNP)
#识别出的实体有两个Amazon Echo识别成了PERSON,Google Home识别成了ORGANIZATION
results = ne_chunk(pos_tag(word_tokenize(paragraph2)))
print(paragraph2)
print()
for x in str(results).split('\n'):if '/NNP' in x:print(x)
Beijing, Shanghai, Tianjin
(S (GPE Beijing/NNP) ,/, (GPE Shanghai/NNP) ,/, (PERSON Tianjin/NNP))
3.创建NER识别器
3.1 流程

3.2 训练数据长什么样

C列:表示词性
D列:实体类别;O表示不是实体,B表示实体开始(Begin), I 表示实体其他部分。(B,I,O表示法,也有其他方法如 B,M,E,O)
3.3 评估NER识别器

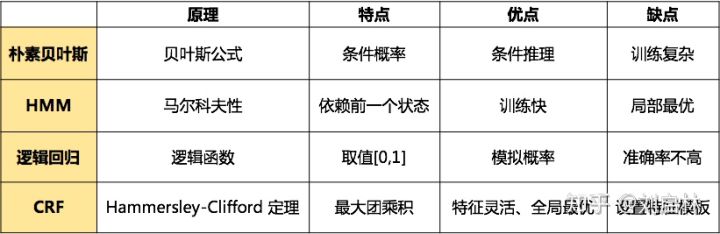
4.NRE的方法

4.1 基于规则的方法
比如:要识别美国电话这个实体,只要写一个正则表达式就行了;
再比如:我们提前定义好了一个词库,只要某个单词在词库中,我们就把它标记为某个实体

4.2 投票决策方法

举个栗子:有 4句话,每句话中单词 lodon 被标记为实体
S1 : …lodon / GEO…
S2: …lodon / LOC …
S3: …lodon / GEO …
S4: …lodon / GEO …
经过统计:针对单词 lodon 有 3次被标记为 GEO,只有一次被标记为 LOC,根据投票原则,那么我们就认为 lodon 的 实体类别为 GEO。对于其他单词,也是统计训练语料库中该单词被标记的不同实体类别的概率,从而选择最大的
该方法特点:不需要学习,只要统计就行了(类似于语言模型的概率计算也是统计来的)
代码:(代码来源于贪心科技)
import pandas as pd
import numpy as np
data = pd.read_csv("ner_dataset.csv", encoding="latin1")
data = data.fillna(method="ffill") # 用前面的值来填充缺失值
data.tail(10) # 显示最后10行

len(data["Word"].values) #1048575
len(set(data["Word"].values)) #35178 去重之后为集合类型
words = list(set(data["Word"].values)) #把集合变成list
n_words = len(words); n_words #35178
from sklearn.base import BaseEstimator, TransformerMixin
BaseEstimator, TransformerMixin的使用参考博文:sklearn 自定义转换器函数
class MajorityVotingTagger(BaseEstimator, TransformerMixin):def fit(self, X, y):"""X: list of words --> data["Word"].values.tolist()y: list of tags --> data["Tag"].values.tolist()"""word2cnt = {}self.tags = []for x, t in zip(X, y): if t not in self.tags: # x : word, t : tagself.tags.append(t)if x in word2cnt: # x : word , word2cnt = {word : {t1: 1, t2 : , ....}, ...}if t in word2cnt[x]: word2cnt[x][t] += 1else:word2cnt[x][t] = 1else:word2cnt[x] = {t: 1}#print("word2cnt: ", word2cnt) # word2cnt: {'A': {'O': 1735, 'I-org': 8, 'I-art': 4, 'B-art': 1, 'B-org': 3}, 'mathematician': {'O': 3}, 'does': {'O': 172}, "n't": {'O': 58, 'I-art': 2}, 'care': {'O': 70}, '.': {'O': 38190}, 'There': {'O': 188}, 'were': {'O': 2814}, '11': {'O': 125, 'I-tim': 83, 'B-org': 1, 'B-tim': 10}, 'people': {'O': 2135}, '-': {'O': 695, 'I-geo': 25, 'I-tim': 148, 'I-per': 22, 'B-geo': 1, 'B-tim': 18, 'I-org': 30, 'B-per': 2, 'I-art': 1, 'B-org': 5}, 'ten': {'O': 10}, 'men': {'O': 385}, 'and': {'O': 15361, 'I-tim': 163, 'I-org': 389, 'B-org': 21, 'B-tim': 8}, 'one': {'O': 1124, 'B-tim': 75, 'I-tim': 13}, 'woman': {'O': 155}, 'hanging': {'O': 11}, 'onto': {'O': 16}},self.mjvote = {}for k, d in word2cnt.items(): # k : word , d: dictself.mjvote[k] = max(d, key=d.get) # 字典默认按 键 比较返回最大的键, 用key = d.get可使按 值 比较,并返回最大值的 键#print(" mjvote: ", self.mjvote)# {finished': 'O', 'speaking': 'O', 'started': 'O', 'clapping': 'O', 'Palestinian': 'B-gpe', 'militants': 'O', 'have': 'O', 'fired': 'O', 'rockets': 'O', 'at': 'O', 'Israel': 'B-geo', 'after': 'O', 'Israeli': 'B-gpe', 'troops': 'O', 'killed': 'O', 'senior': 'O', 'Islamic': 'O', 'Jihad': 'I-org', 'commander': 'O', 'The': 'O', 'caused': 'O', 'no': 'O',}def predict(self, X, y=None):'''Predict the the tag from memory. If word is unknown, predict 'O'.'''return [self.mjvote.get(x, 'O') for x in X] # 当字典的键(这里是word)不存在时,#也就是测试集中出现了训练集意外的单词,则返回默认值 'O'pred = cross_val_predict(estimator=MajorityVotingTagger(), X=words, y=tags, cv= 5)report = classification_report(y_true=tags, y_pred=pred) # 打印与分类任务相关的信息
print(report)

4.3 基于监督学习的方法
基于监督学习的方法核心是将数据表示成特征向量输入到模型当中;所以第一步要做特征工程,然后模型是个多分类模型如随机森林,逻辑回归等,类别个数为实体类别个数。
1. 如何提取每个单词的特征呢?
最基本的特征如word.istitle(), word.islower(), word.isuper(), word.isdigit(), 词长,word.isalpha()…等,这些特征都没有考虑上下文信息
2. 特征工程(很重要),以英文单词Colin为例, 它属于 PER 还是 LOC 实体呢?

上述每个特征都是最终特征向量的一个分量,所以特征向量通常很长很长…
把上述特征描述转化成向量时,是要考虑词库大小的
代码详解,简单的特征向量
import pandas as pd
import numpy as np
data = pd.read_csv("ner_dataset.csv", encoding="latin1")
data = data.fillna(method="ffill") # 用前面的值来填充缺失值
data.tail(10) # 显示最后10行
words = list(set(data["Word"].values))
n_words = len(words); n_words
from sklearn.base import BaseEstimator, TransformerMixinclass MajorityVotingTagger(BaseEstimator, TransformerMixin):def fit(self, X, y):"""X: list of wordsy: list of tags"""word2cnt = {}self.tags = [] #为什么要用self来定义变量呢,因为调用该函数之后,对象就有这个属性了for x, t in zip(X, y):if t not in self.tags:self.tags.append(t)if x in word2cnt:if t in word2cnt[x]:word2cnt[x][t] += 1else:word2cnt[x][t] = 1else:word2cnt[x] = {t: 1}self.mjvote = {}for k, d in word2cnt.items():self.mjvote[k] = max(d, key=d.get)def predict(self, X, y=None): #放入测试数据,单词列表'''Predict the the tag from memory. If word is unknown, predict 'O'.'''return [self.mjvote.get(x, 'O') for x in X]from sklearn.ensemble import RandomForestClassifier***********************************核心代码***************************
def get_feature(word):return np.array([word.istitle(), word.islower(), word.isupper(), len(word),word.isdigit(), word.isalpha()]) #单词的特征向量,很长维度
*********************************************************************
words = [get_feature(w) for w in data["Word"].values.tolist()]
print(len(words)) # 1048575
tags = data["Tag"].values.tolist()from sklearn.model_selection import cross_val_predict
from sklearn.metrics import classification_report
pred = cross_val_predict(RandomForestClassifier(n_estimators=20), X=words, y=tags, cv=5)
report = classification_report(y_pred=pred, y_true=tags)
print(report)

很不幸,正确率只有 80% 几,所以我们创造更加复杂的特征
代码详解,增强的特征向量
import pandas as pd
import numpy as np
data = pd.read_csv("ner_dataset.csv", encoding="latin1")
data = data.fillna(method="ffill") # 用前面的值来填充缺失值
data.tail(10) # 显示最后10行
words = list(set(data["Word"].values))
n_words = len(words); n_words
from sklearn.base import BaseEstimator, TransformerMixinclass MajorityVotingTagger(BaseEstimator, TransformerMixin):def fit(self, X, y):"""X: list of wordsy: list of tags"""word2cnt = {}self.tags = [] #为什么要用self来定义变量呢,因为调用该函数之后,对象就有这个属性了for x, t in zip(X, y):if t not in self.tags:self.tags.append(t)if x in word2cnt:if t in word2cnt[x]:word2cnt[x][t] += 1else:word2cnt[x][t] = 1else:word2cnt[x] = {t: 1}self.mjvote = {}for k, d in word2cnt.items():self.mjvote[k] = max(d, key=d.get)def predict(self, X, y=None): #放入测试数据,单词列表'''Predict the the tag from memory. If word is unknown, predict 'O'.'''return [self.mjvote.get(x, 'O') for x in X]def get_sentences(data):agg_func = lambda s: [(w, p, t) for w, p, t in zip(s["Word"].values.tolist(),s["POS"].values.tolist(),s["Tag"].values.tolist())]sentence_grouped = data.groupby("Sentence #").apply(agg_func) # 返回Series类型,每一行格式:sentence 1 [(Word, POS, Tag)] return [s for s in sentence_grouped]
# list of list [[(word1, pos1, tag1), (...), (....),(...) ], [(word2, pos2, tag2),(),(),()..], [(word3, ps3, tag3), (),(),() ].....]
#内层的list 表示一句话,元组表示一句话中每个(单词,词性,标签)sentences = get_sentences(data)
#print(sentence_grouped)

from sklearn.preprocessing import LabelEncoder
#标签专用,能够将分类转换为分类数值,如能将 ”A“,”B",“C”转换成 1,2,3out = []
y = []
mv_tagger = MajorityVotingTagger()
tag_encoder = LabelEncoder() # 实例化LabelEncoder
pos_encoder = LabelEncoder()words = data["Word"].values.tolist() #转化为单词列表
pos = data["POS"].values.tolist()
tags = data["Tag"].values.tolist()mv_tagger.fit(words, tags)
tag_encoder.fit(tags) #导入数据
pos_encoder.fit(pos) #导入数据for sentence in sentences: #每个sentence是[(word, pos, tag), (), (), (), ().....] ,一句话有多少个单词就有多少个元组for i in range(len(sentence)): # len(sentence) 句子的长度,循环每个单词(单词,词性,tag)w, p, t = sentence[i][0], sentence[i][1], sentence[i][2]if i < len(sentence)-1: # 如果不是最后一个单词,则可以用到下文的信息pos 和 tag# predict()传入单词列表,预测每个单词的tag# [sentence[i+1][0]:下一个 word#transfom: 调取类别结果,如传入”A“,”B",“C”取出 1,2,3#返回 array([#])类型,tag_encoder.transform()[0]取出 array中的数字 #mem_tag_r = tag_encoder.transform(mv_tagger.predict([sentence[i+1][0]]))[0] true_pos_r = pos_encoder.transform([sentence[i+1][1]])[0]else:mem_tag_r = tag_encoder.transform(['O'])[0]true_pos_r = pos_encoder.transform(['.'])[0] #每句话最后一个单词是 "."if i > 0: # 如果不是第一个单词,则可以用到上文的信息tag 和 posmem_tag_l = tag_encoder.transform(mv_tagger.predict([sentence[i-1][0]]))[0]true_pos_l = pos_encoder.transform([sentence[i-1][1]])[0]else:mem_tag_l = tag_encoder.transform(['O'])[0]true_pos_l = pos_encoder.transform(['.'])[0]#print (mem_tag_r, true_pos_r, mem_tag_l, true_pos_l)
**************************************核心代码***************************out.append(np.array([w.istitle(), w.islower(), w.isupper(), len(w), w.isdigit(), w.isalpha(),tag_encoder.transform(mv_tagger.predict([sentence[i][0]]))[0], #当前单词的 tagpos_encoder.transform([p])[0], mem_tag_r, true_pos_r, mem_tag_l, true_pos_l])) #p 当前单词的词性# out:每个单词的特征向量y.append(t) #t: 当前单词的tag, y: list, 每个单词的tag
************************************************************************
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import classification_report
pred = cross_val_predict(RandomForestClassifier(n_estimators=10), X=out, y=y, cv=5)
report = classification_report(y_pred=pred, y_true=y)
print(report)
这个运行时间会有点长。。。,就留给大家运行吧,正确率应该会比上一个高
附加知识点 --特征分类
1. 分类型特征。可以用 one-hot 编码 [0,0,0,1,0,0,0,…]
from sklearn.preprocessing import OneHotEncoder

2. Ordinal 特征, 只有顺序,不能做运算。①可以对其二值化或标准化之后直接使用;②可以用OrdinalEncoder,[0,1,2,3,4,…];③也可以用 one - hot
from sklearn.preprocessing import Binarizer
from sklearn.preprocessing import KBinsDiscretizer
from sklearn.preprocessing import OrdinalEncoder
from sklearn.preprocessing import OneHotEncoder

3. 连续型特征,有顺序,并且可以运算。①可以对其二值化或标准化之后直接使用;②也可以对该类型特征分箱(KBinsDiscretizer) 变成分类型特征,再用 one-hot 编码
from sklearn.preprocessing import OrdinalEncoder
from sklearn.preprocessing import KBinsDiscretizer

4.4 时序模型 --LSTM+CRF
现在做命名实体识别的主流方法就是 LSTM+CRF
这里可以看参考博文:LSTM+CRF模型的CRF层原理与代码理解
结合博文:CRF轻松详解