文章目录
- 一、图的概述
- 1.1 什么是图
- 1.2 图对比线性表和树
- 1.3 图的常见概念
- 二、图的存储方式
- 2.1 邻接矩阵
- 2.2 邻接表
- 三、图的遍历
- 3.1 图的深度优先遍历
- 3.1.1 什么是深度优先遍历
- 3.1.2 深度优先遍历的步骤
- 3.1.3 深度优先遍历代码实现
- 3.2 图的广度优先遍历
- 3.2.1 什么是广度优先遍历
- 3.2.2 广度优先遍历的步骤
- 3.2.3 广度优先遍历代码实现
一、图的概述
1.1 什么是图
图(graph)是一种数据结构,它是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E)。其中 G 表示一个图,V 是图 G 中顶点的集合,E 是图 G 中边的集合。

从图的定义中我们可以注意到它的一个特点:图中数据元素被称为顶点(Vertex)。而在线性表中的数据元素叫元素,树形结构中的数据元素叫做节点。
1.2 图对比线性表和树
前面学习过线性表和树,现在又学到了图。为什么有这么多的数据结构呢?它们各自有什么不可替代的特点呢?
在线性表中,数据元素之间是串起来的,仅有线性关系,每个数据元素只有一个直接前驱和一个直接后继,可以理解为一对一。在树形结构中,数据元素之间有着明显的层次关系,并且每一层上的数据元素可能和下一层中的多个元素相关,但是只能和上一层中一个元素相关,可以理解为一对多。
图示一种较线性表和树更加复杂的数据结构。在图形结构中,节点之间的关系可以是任意的,图中任意两个数据元素之间都可能相关,可以理解为多对多。
1.3 图的常见概念
在图中有比较多的概念需要掌握,下面用一个表格来展示图形结构的常见概念。
| 常见概念 | 概念解释 |
|---|---|
| 顶点 | 数据元素 |
| 边 | 两个顶点之间的连线 |
| 路径 | 从顶点 A 到顶点 B 要经过的边(路径可以有多条) |
| 邻接点 | 相邻的顶点(如 A 和 B 通过一条边直接相连,则 B 是 A 的邻接点,A 是 B 的邻接点) |
| 无向图 | 所有的边都没有方向 |
| 有向图 | 所有的边都有方向(如 A->B,表示只能从 A 到 B,无法从 B 到 A) |
| 带权图 | 所有的边都带有权值 |
| 连通图 | 任意两个顶点都是连通的 |

二、图的存储方式
图的存储方式有两种:二维数组表示(邻接矩阵)、链表表示(邻接表)。
2.1 邻接矩阵
图的邻接矩阵 (Adjacency Matrix) 存储方式是用两个数组来表示图,其中一个一维数组用来存储顶点信息,一个二维数组(称为邻接矩阵)存储图中的边的信息。
邻接矩阵的行和列都是代表着图的第几个顶点。

如上所示图左是一个无向图,右边是该无向图的邻接矩阵:顶点 0 和顶点 1 之间存在一条边,因此 arr[0][1] 和 arr[1][0] 都为 1(仅适用于无向图);顶点 0 和顶点 5 之间没有直接相连的边,因此 arr[0][5] 和 arr[5][0] 都是 0。
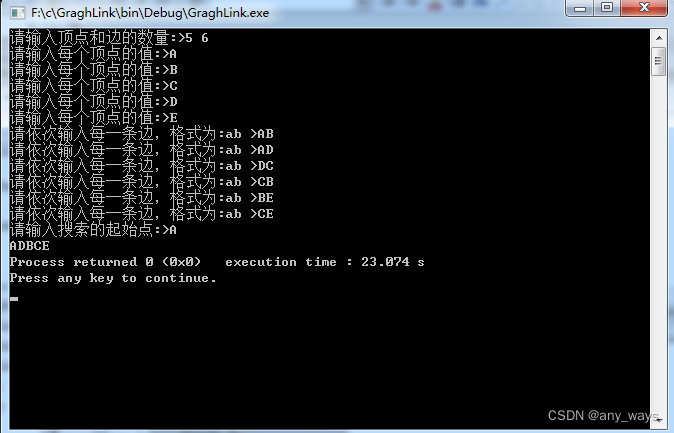
【案例演示】
代码实现如下图结构,要求使用邻接矩阵。

public class No1_Graph {public static void main(String[] args) {String[] str = {"A", "B", "C", "D", "E"};// 创建一个图对象Graph graph = new Graph(str.length);// 添加顶点for (String vertex : str){graph.addVertex(vertex);}// 设置顶点之间的边graph.setEdges(0, 1, 1); // A<->Bgraph.setEdges(1, 2, 1); // B<->Cgraph.setEdges(1, 3, 1); // B<->Dgraph.setEdges(1, 4, 1); // B<->E;graph.setEdges(0, 2, 1); // A<->C;}
}/*** 图*/
class Graph{private ArrayList<String> vertexList; // 存储顶点的集合private int[][] edges; // 图对应的邻接矩阵private int numOfEdges; // 顶点之间边的个数// 图的初始化public Graph(int n){this.vertexList = new ArrayList<>();this.edges = new int[n][n];this.numOfEdges = 0;this.isVisited = new boolean[n];}// 添加顶点到图中public void addVertex(String vertex){vertexList.add(vertex);}/*** 设置两个顶点之间的边* @param n 第一个顶点的索引* @param m 第二个顶点的索引* @param weight 边的权重* @return void*/public void setEdges(int n, int m, int weight){edges[n][m] = weight;edges[m][n] = weight;numOfEdges++;}// 打印邻接矩阵public void printGraph(){for (int[] edge : edges){System.out.println(Arrays.toString(edge));}}
}
代码运行结果如下:

2.2 邻接表
图的邻接表(Adjacency List)存储方式是用数组和链表来表示图,其中一个一维数组用来存储顶点,顶点数组中的每个数据元素还需要存储指向该顶点第一个邻接点的指针,每个顶点的所有邻接点构成一个线性表。
邻接矩阵需要为每个顶点都分配 n 个边的空间,其实有很多边都是不存在,会造成空间的一定损失。邻接表的实现只关心存在的边,不关心不存在的边,因此没有空间浪费。
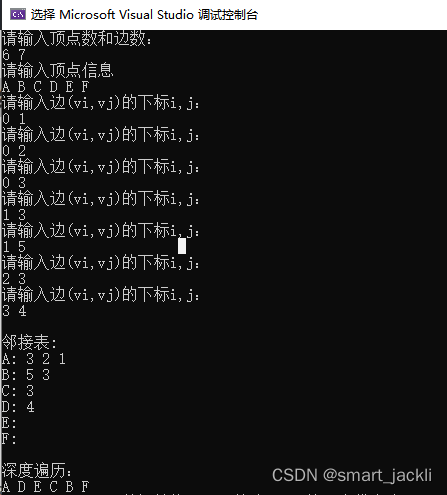
如下图所示就是一个无向图的邻接表结构。

如图右所示,是无向图的邻接表:如标号为 0 的顶点的邻接点为 1、2、3、4;标号为 2 的订单的邻接点为 0、5。
顶点数组中的数据元素由两部分组成,一部分是数据域存储顶点的信息,另一部分是指针域,指向该顶点的第一个邻接点。链表节点同样由两部分组成,一部分是邻接点域,用于存储与顶点相邻的点在图中的位置,另一部分是指针域,指向下一条边(如果边还有权值,还需要一个数据域用于存储权值,共三部分)。
三、图的遍历
从图中某一个顶点出发遍历图中其余顶点,且使每一个顶点仅被访问一次,这个过程就叫做图的遍历。一个图有多个顶点,如何遍历这些顶点,需要特定策略,一般有两种访问策略:深度优先遍历、广度优先遍历。
3.1 图的深度优先遍历
3.1.1 什么是深度优先遍历
深度优先遍历(Depth First Search),也称深度优先搜索,简称为 DFS。
深度优先遍历的思想说起来可能比较抽象,下面举个例子说一下。
古时候有个功夫平平的剑客,一直想找到武林秘籍来提升自己的功夫。也算他命好,在行走江湖的路上他认识了一位神秘的老者,老者看他心系武林,就把守护了一生的秘密告诉他:在黄山、华山、泰山、峨眉山中的其中一座山里藏着失传已经的降龙十八掌,但是具体在哪座山需要他自己去找。
一听说这个,剑客可就不困了。但是冷静下来之后,这个剑客有点懵逼了,这几座山这么大,离得还这么远,该怎么去寻找武林秘籍呢?
经过一夜的辗转反侧,剑客最终确定了行动思路:先去黄山,不放过黄山的任何一个角落,把黄山的所有山洞、所有的小溪、所有的山路、所有的树木甚至是动物都找个遍,简单来说就是翻个底朝天,然后再去下一座山,再翻个底朝天,直到找到为止。
这就是深度优先遍历的思想,简单来说就是优先向纵深挖掘,它类似于树的先序遍历的过程。
3.1.2 深度优先遍历的步骤
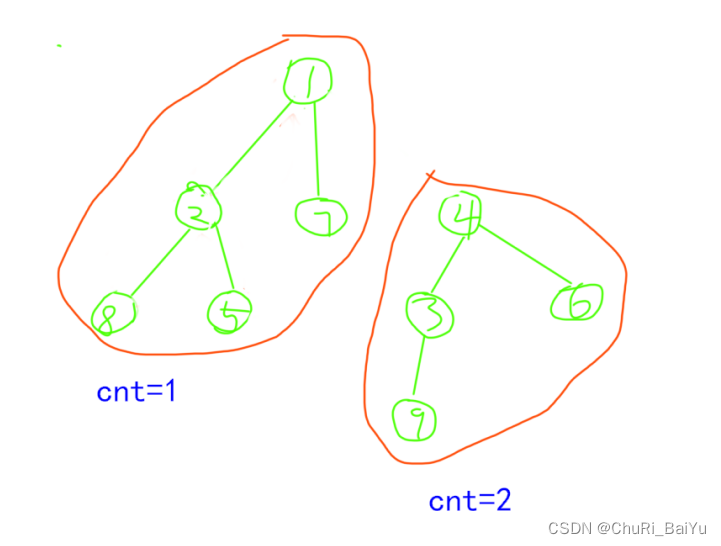
假设初始状态是图中所有顶点未曾被访问,则深度优先搜索可从图中某个顶点 v 出发,访问此顶点,然后依次从 v 的未被访问的邻接点出发深度优先遍历图,直至图中所有和 v 有路径相通的顶点都被访问到;若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。
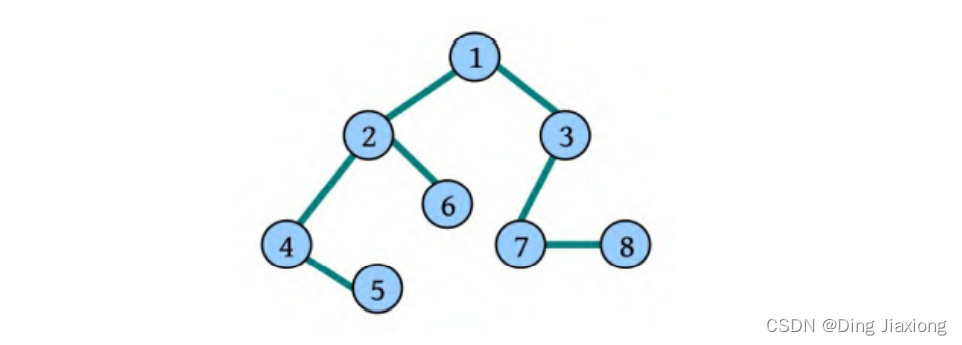
以下面一个无向图为例,讲解其深度优先遍历过程。

假设从顶点 v1 出发,在访问完 v1 之后,选择邻接点 v2,因为 v2 未被访问,则从 v2 出发进行搜索。依次类推,接着从 v4、v7 出发进行搜索。在访问了 v7 之后,由于 v7 的邻接点都已经被访问,则搜索退回到 v4。由于同样的理由搜索继续回到 v2,直至 v1。此时由于 v1 的另一个邻接点未被访问,则搜索又从 v1 到 v3,再继续进行下去。由此,得到的顶点访问序列为:
v 1 → v 2 → v 4 → v 7 → v 3 → v 5 → v 6 v1→v2→v4→v7→v3→v5→v6 v1→v2→v4→v7→v3→v5→v6
显然,这是一个递归加回溯的过程。为了在遍历过程中便于区分顶点是否已被访问,需附设访问标志数组 isVisited[0.. n-1],其初始值为false,一旦某个顶点被访问,则其相应的分量置为 true。
3.1.3 深度优先遍历代码实现
boolean[] isVisited = new boolean[vertexList.size]; // 标志数组/*** 从顶点 v 开始深度优先搜索 (DFS)* @param v 顶点*/
public void dfs(int v){isVisited[v] = true; // 设置当前顶点状态为已访问System.out.print(vertexList.get(v) + "->"); // 打印当前顶点for (int i=0; i<vertexList.size(); i++){ // 遍历顶点 if (edges[v][i]==1 && !isVisited[i]){ // 如果某个顶点和当前顶点有直连的边且该顶点未被访问过dfs(i); // 递归深度优先遍历这个顶点}}
}/*** 对图深度优先搜索*/
public void dfsTraverse(){/* 有可能是非连通图,出现顶点独立现象,因此有可能要以每个顶点为起点都来一次深度优先搜索 */for (int i=0; i<vertexList.size(); i++){if (!isVisited[i]){ // 如果顶点未被访问过,则从它开始 dfs。对于连通图,只会执行一次。dfs(i);}}
}
3.2 图的广度优先遍历
3.2.1 什么是广度优先遍历
广度优先遍历(Breadth First Search),又称为广度优先搜索,简称 BFS。
还是以剑客找武林秘籍为例。剑客在赶往黄山的路上一想到要把整座山都翻个遍,瞬间头皮就麻了,他觉得武林秘籍总不至于会藏在山上的某个小石头下面吧,一定是藏在某个有灵气的地方。于是他改变了策略:先到每座山上大概瞅一眼,看看山的山势、灵气是不是像有武林秘籍的地方,如果都没有,再依次到各个山的山洞、小溪中找一找,如果没找到,再依次到各个山的小石头下翻一翻…,直到找到为止。
这就是广度优先遍历的思想,它类似于树的按层次遍历的过程。
3.2.2 广度优先遍历的步骤
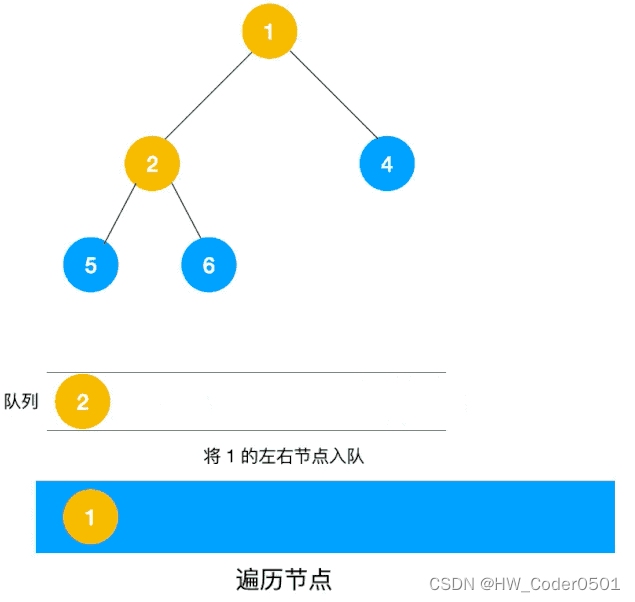
假设从图中顶点 v 出发,在 访问了 v 之后依次访问 v 的各个未曾访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,并使 “先被访问的顶点的邻接点” 先于 “后被访问的顶点的邻接点” 被访问,直至图中所有已被访问的顶点的邻接点都被访问到。若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。
还是以下面一个无向图为例,讲解广度优先遍历过程。
首先访问 v1 和 v1 的邻接点 v2 和 v3,然后依次访问 v2 的邻接点 v4 和 v7 以及 v3 的邻接点 v5 和 v6。由于这些顶点的邻接点均已被访问,并且图中所有的顶点都被访问,由此完成了图的遍历。最终得到的顶点访问序列为:
v 1 → v 2 → v 3 → v 4 → v 7 → v 5 → v 6 v1→v2→v3→v4→v7→v5→v6 v1→v2→v3→v4→v7→v5→v6
和深度优先遍历类似,广度优先遍历在遍历的过程中也需要一个访问标志数组。并且,为了顺次访问路径长度为 2、3 … 的顶点,需要附设队列以存储已被访问的路径长度为 1、2 … 的顶点。
3.2.3 广度优先遍历代码实现
/*** 从顶点 v 开始广度优先遍历 (BFS)* @param v 顶点*/
public void bfs(int v){LinkedList<Integer> queue = new LinkedList<>(); // 队列,用于存放已被访问的顶点isVisited[v] = true; // 设置状态为已访问System.out.print(vertexList.get(v) + "->"); // 打印顶点queue.addLast(v); // 添加当前顶点到队列中while (!queue.isEmpty()){ // 如果当前队列不为空v = queue.removeFirst(); // 队头元素出队列,接下来将以这个出队列的元素为起点访问邻接点for (int i=0; i<vertexList.size(); i++){if (edges[v][i] == 1 && !isVisited[i]){ // 判断其它顶点与当前顶点是否有边且是否访问过isVisited[i] = true; // 标记符合条件的顶点状态为已访问System.out.print(vertexList.get(i) + "->"); // 打印顶点queue.addLast(i); // 将此顶点入队列}}}
}/*** 广度优先遍历图*/
public void bfsTraverse(){/* 可能是非连通图,出现顶点独立现象,因此有可能每个顶点都要广度优先搜索 */for (int i=0; i<vertexList.size(); i++){if (!isVisited[i]){ // 如果顶点未被访问过,则对该顶点广度优先搜索,对于连通图只会执行一次bfs(i);}}
}